-
Epic
-
Resolution: Unresolved
-
 Major
Major
-
None
-
Modifications to structure and markup needed to prepare source files for conversion to DITA
-
5
-
False
-
-
False
-
0% To Do, 0% In Progress, 100% Done
-
-
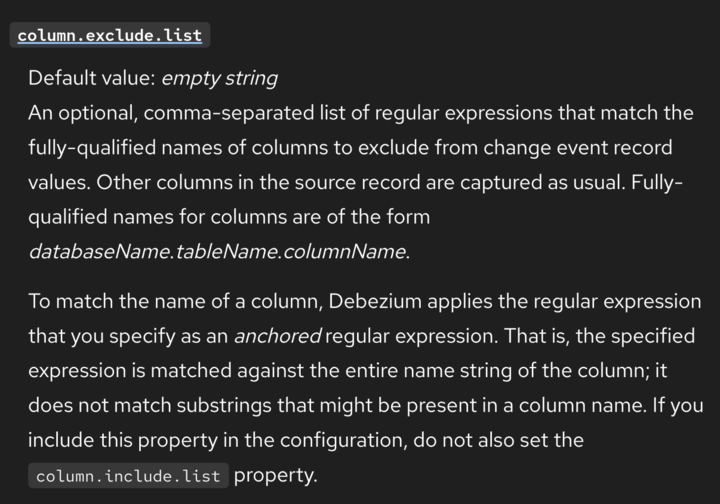
The Debezium community documentation has always been authored in AsciiDoc. Beginning next year the Red Hat product documentation is migrating to DITA. To facilitate a smooth migration, the following changes are required in the current AsciiDoc files:
- Reformat content to remove third-level (and higher) topic headings. This implies a great deal of restructuring. (Pending testing, it's unclear whether all of these must be removed, or whether the current documentation toolchain can do some of this processing). This might not be necessary. After Nebel splits source files, the resulting module files no longer contain third-level headings. However, review of files in the /partials directory is needed to determine whether any block titles they contain are valid.
- Remove in-line links and replace them with entries within an Additional resources section.
- Remove text from Additional resources list entries. Only links are allowed.
- Remove hard line breaks (the are present mostly in properties descriptions within table cells).
- Insert blank line after topic title headings.
- Remove block titles before admonition blocks (and most everywhere else, but that's where most of the illegal instances occur).
- Remove [discrete] attributes before headings.
- Add short description introductory sentence for each content chunk that's designated for use as a downstream topic module.
- Add alt text to image tags (image::[]) as needed.
Other issues are likely to present themselves, but that represents the majority of the known required fixes.
Any "corrections" implemented must be applied to the upstream files, so that they are not overwritten by successive releases.
Over time, the migration process should become easier and smoother as I incrementally weed out constructions that block conversion.
- is caused by
-
DBZ-9811 Initial Vale DITA compatibility assessment
-

- Resolved
-