-
Story
-
Resolution: Done
-
 Critical
Critical
-
None
-
None
-
None
-
None
-
Product / Portfolio Work
-
False
-
-
False
-
2
-
None
-
None
-
HAC Infra OCP - Sprint 240
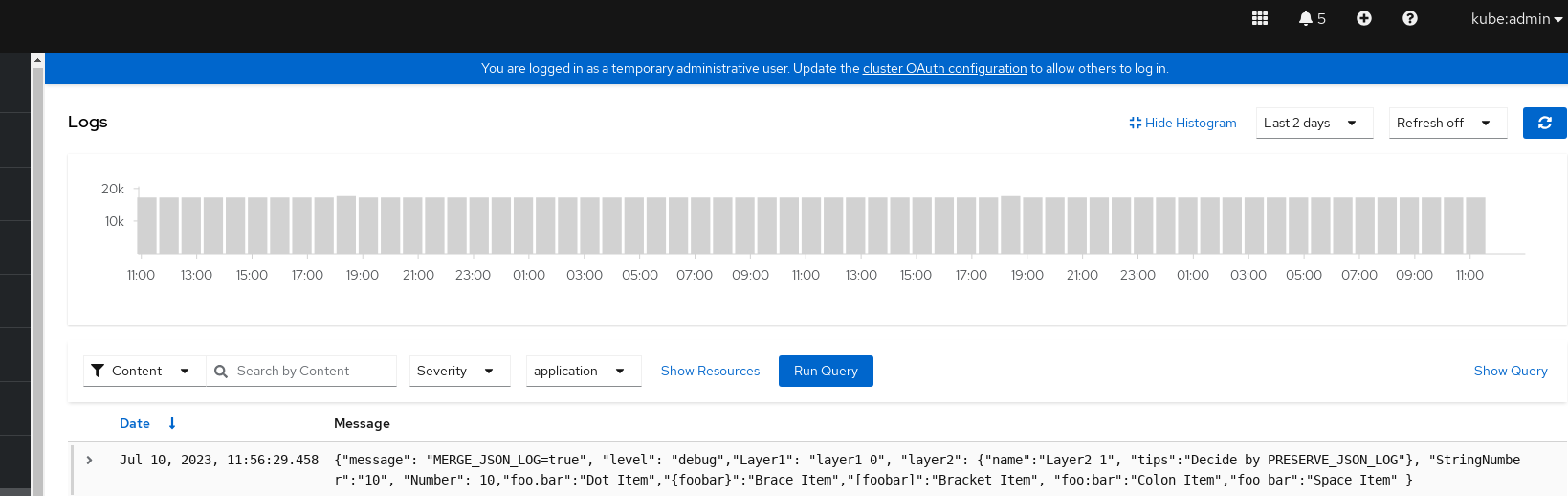
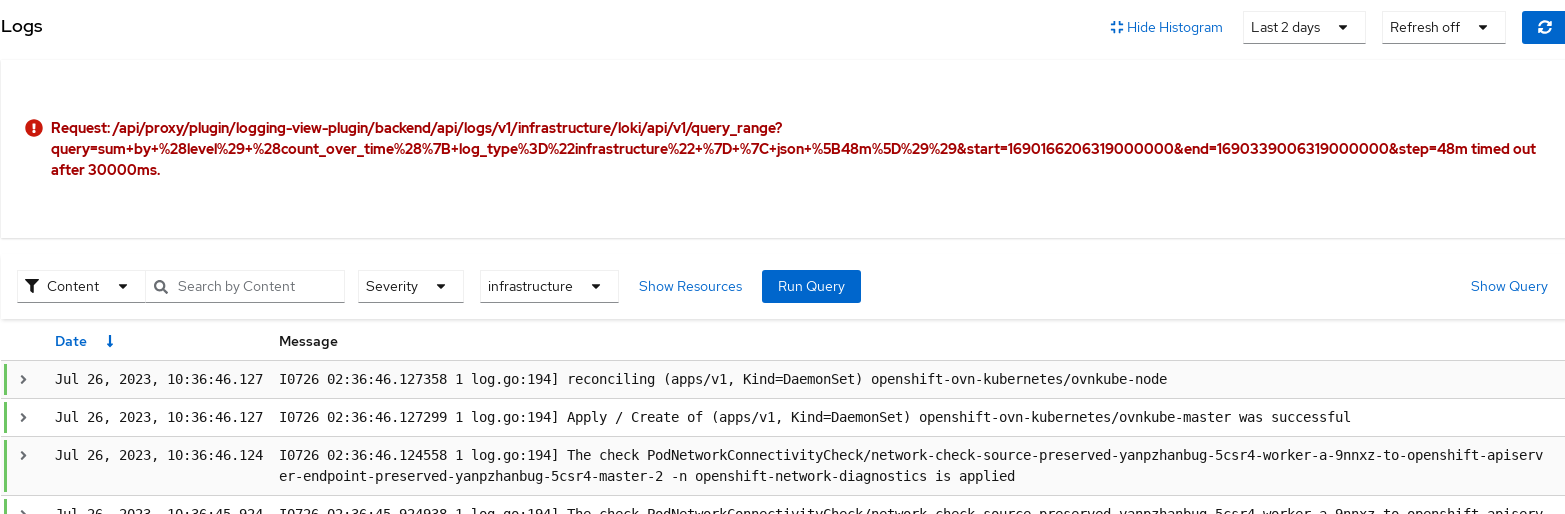
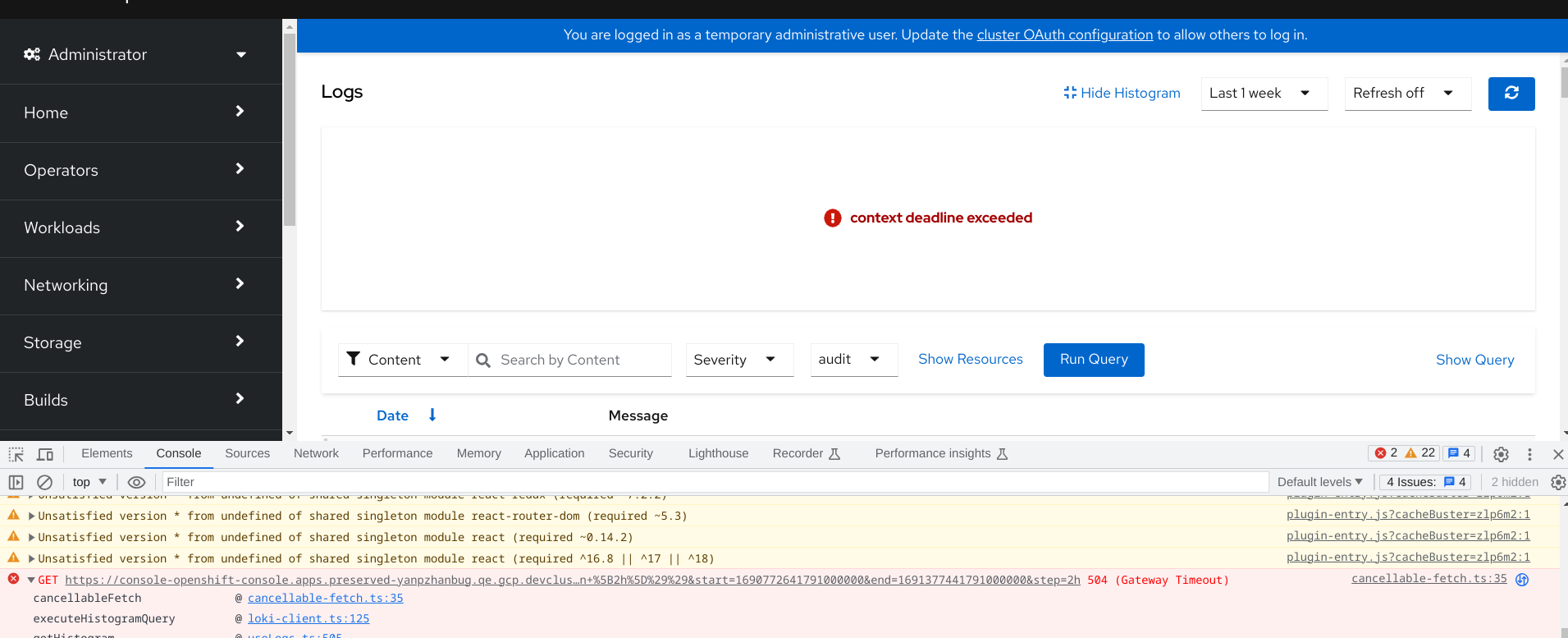
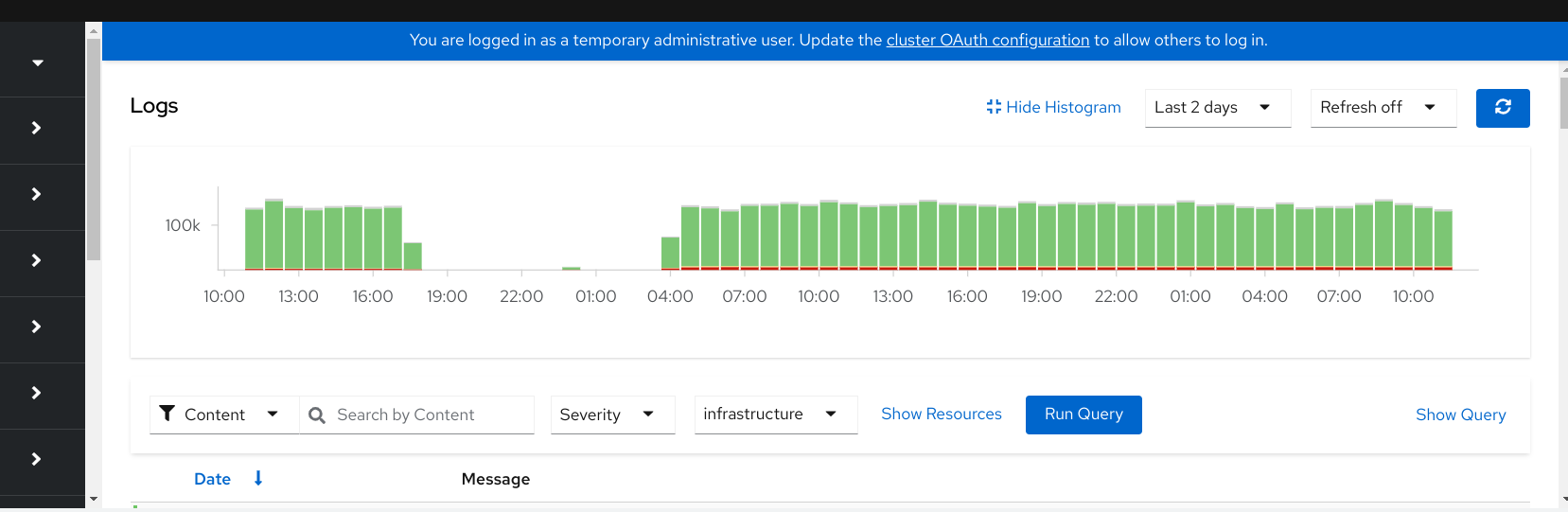
Based on https://issues.redhat.com/browse/RFE-3775 we should be extending our proxy package timeout to match the browser's timeout, which is 5 minutes.
AC: Bump the 30second timeout in the proxy pkg to 5 minutes

- is depended on by
-
LOG-3498 Loki returning timed out after 30000ms
-

- Closed
-
- is related to
-
RFE-3775 Make dynamic plugins proxy timeout customizable
-
- Approved
-
-
-

- Closed
-
- links to
