-
Story
-
Resolution: Done
-
 Normal
Normal
-
None
-
None
-
None
-
Product / Portfolio Work
-
False
-
-
False
-
3
-
None
-
None
-
OTA 256, OTA 257
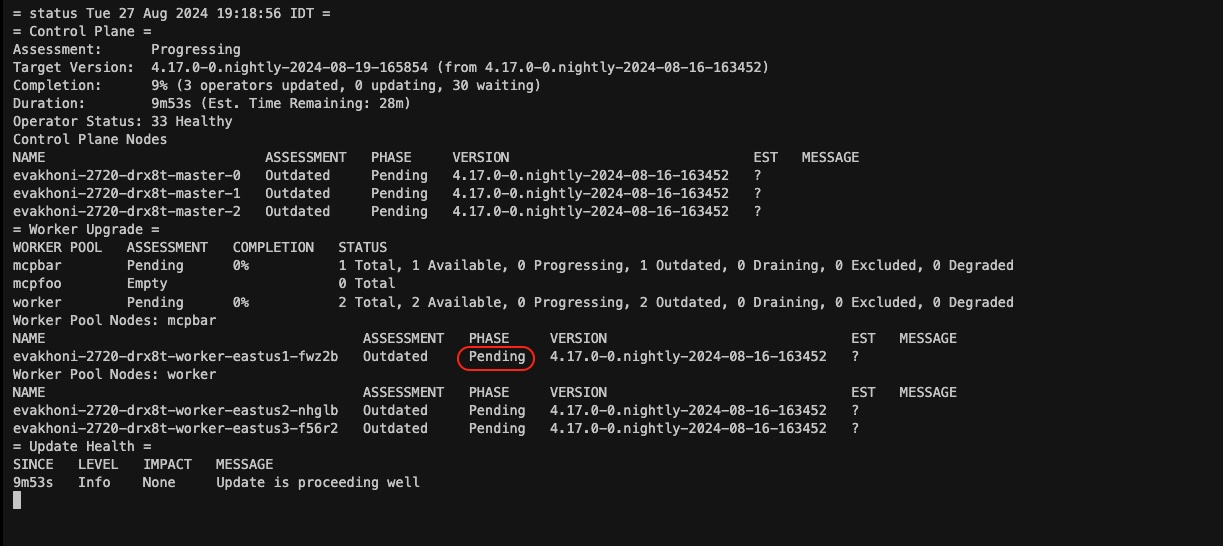
Discovered by evakhoni@redhat.com during OTA-1245, the 4.16 code did not take nodes that are members of multiple pools into account. This surfaced in several ways:
Duplicate insights (=we iterate over nodes over pools, so we see problematic edges in each pool it is a member of):
= Update Health = SINCE LEVEL IMPACT MESSAGE - Error Update Stalled Node ip-10-0-26-198.us-east-2.compute.internal is degraded - Error Update Stalled Node ip-10-0-26-198.us-east-2.compute.internal is degraded
Such node is present in all pool listings, and in some cases such as paused pools the output is confusing (paused-ness is a property of a pool, so we list a node as paused in one pool but outdated pending in another):
= Worker Pool = Worker Pool: mcpfoo Assessment: Excluded ... Worker Pool Node NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-26-198.us-east-2.compute.internal Excluded Paused 4.15.12 - = Worker Pool = Worker Pool: worker ... Worker Pool Nodes NAME ASSESSMENT PHASE VERSION EST MESSAGE ip-10-0-26-198.us-east-2.compute.internal Outdated Pending 4.15.12 ?
It is not clear to me what would be the correct presentation of this case. Because this is an update status (and not node or cluster status) command, and only a single pool drives an update of a node, I'm thinking that maybe the best course of action would be to show only nodes whose version is driven by a given pool, or maybe come up with a "externally driven"-like assessment or whatever.
{kind=link}
- incorporates
-
OCPBUGS-37169 worker pool status should reflect the correct number of nodes
-

- Closed
-
- is related to
-
OTA-1309 Ensure the node in a single-node cluster is handled correctly
-
- Closed
-
- split from
-
OTA-1245 post-merge testing: OTA-1165 - worker node status
-
- Closed
-
- links to