-
Feature
-
Resolution: Done
-
 Critical
Critical
-
None
-
Product / Portfolio Work
-
None
-
0% To Do, 0% In Progress, 100% Done
-
False
-
None
-
False
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Overview
HyperShift came to life to serve multiple goals, some are main near-term, some are secondary that serve well long-term.
Main Goals for hosted control planes (HyperShift)
- Optimize OpenShift for Cost/footprint/ which improves our competitive stance against the *KSes
- Establish separation of concerns which makes it more resilient for SRE to manage their workload clusters (be it security, configuration management, etc).
- Simplify and enhance multi-cluster management experience especially since multi-cluster is becoming an industry need nowadays.
Secondary Goals
HyperShift opens up doors to penetrate the market. HyperShift enables true hybrid (CP and Workers decoupled, mixed IaaS, mixed Arch,...). An architecture that opens up more options to target new opportunities in the cloud space. For more details on this one check: Hosted Control Planes (aka HyperShift) Strategy [Live Document]
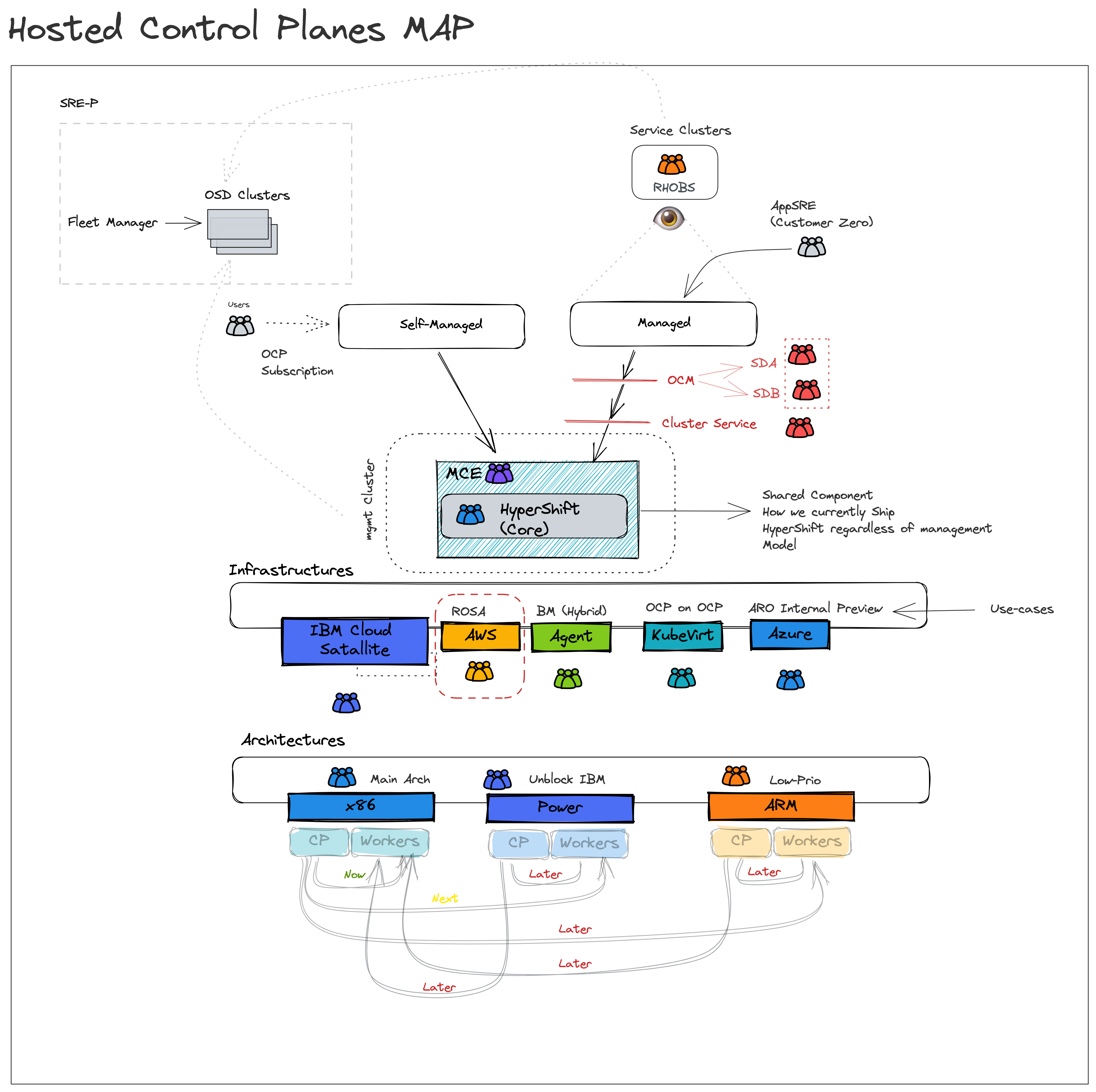
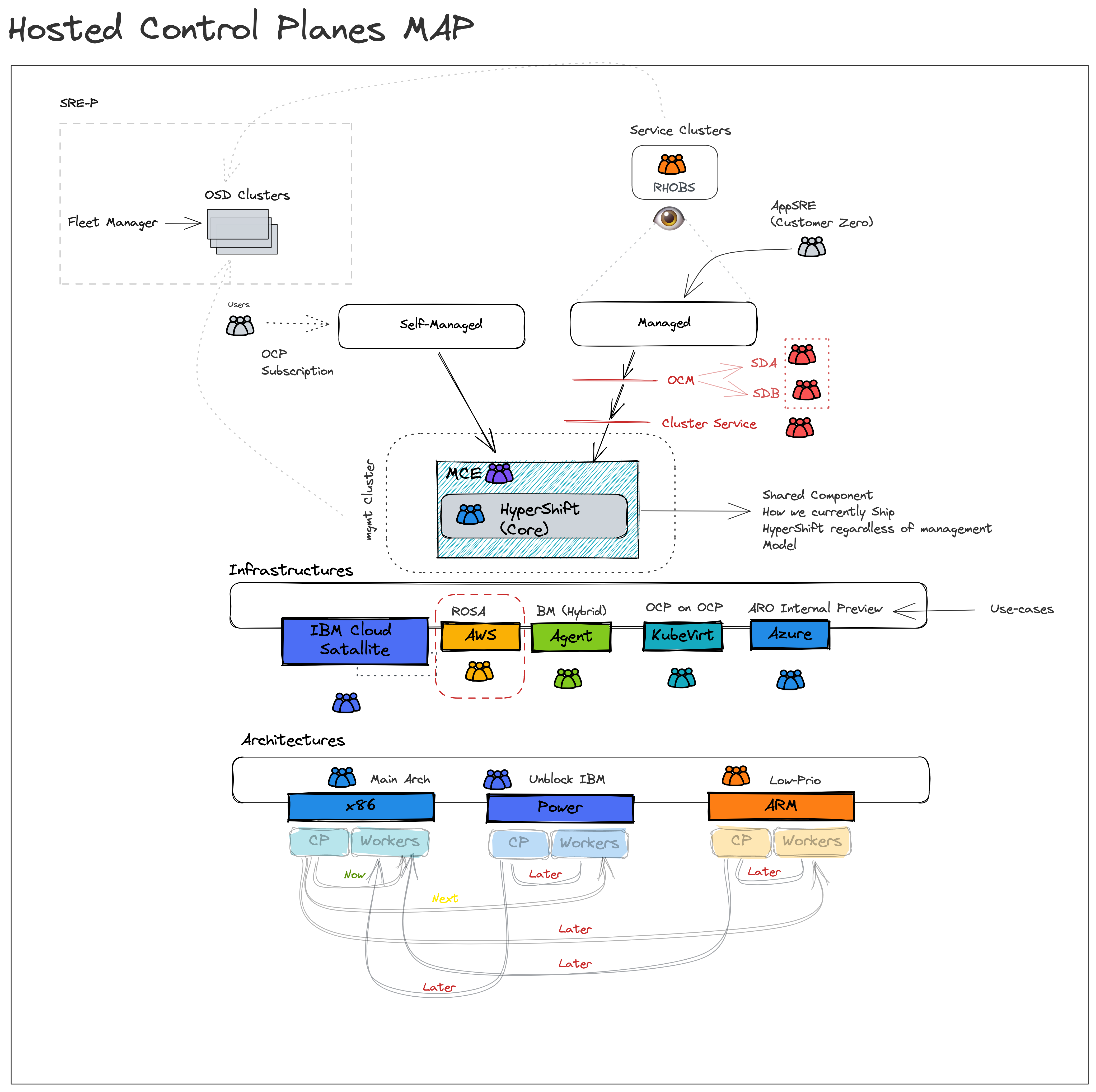
Hosted Control Planes (HyperShift) Map
To bring hosted control planes to our customers, we need the means to ship it. Today MCE is how HyperShift shipped, and installed so that customers can use it. There are two main customers for hosted-control-planes:
- Self-managed: In that case, Red Hat would provide hosted control planes as a service that is managed and SREed by the customer for their tenants (hence “self”-managed). In this management model, our external customers are the direct consumers of the multi-cluster control plane as a servie. Once MCE is installed, they can start to self-service dedicated control planes.
- Managed: This is OpenShift as a managed service, today we only “manage” the CP, and share the responsibility for other system components, more info here. To reduce management costs incurred by service delivery organizations which translates to operating profit (by reducing variable costs per control-plane), as well as to improve user experience, lower platform overhead (allow customers to focus mostly on writing applications and not concern themselves with infrastructure artifacts), and improve the cluster provisioning experience. HyperShift is shipped via MCE, and delivered to Red Hat managed SREs (same consumption route). However, for managed services, additional tooling needs to be refactored to support the new provisioning path. Furthermore, unlike self-managed where customers are free to bring their own observability stack, Red Hat managed SREs need to observe the managed fleet to ensure compliance with SLOs/SLIs/…
If you have noticed, MCE is the delivery mechanism for both management models. The difference between managed and self-managed is the consumer persona. For self-managed, it's the customer SRE for managed its the RH SRE.
High-level Requirements
For us to ship HyperShift in the product (as hosted control planes) in either management model, there is a necessary readiness checklist that we need to satisfy. Below are the high-level requirements needed before GA:
- Hosted control planes fits well with our multi-cluster story (with MCE)
- Hosted control planes APIs are stable for consumption
- Customers are not paying for control planes/infra components.
- Hosted control planes has an HA and a DR story
- Hosted control planes is in parity with top-level add-on operators
- Hosted control planes reports metrics on usage/adoption
- Hosted control planes is observable
- HyperShift as a backend to managed services is fully unblocked.
Please also have a look at our What are we missing in Core HyperShift for GA Readiness? doc.
Hosted control planes fits well with our multi-cluster story
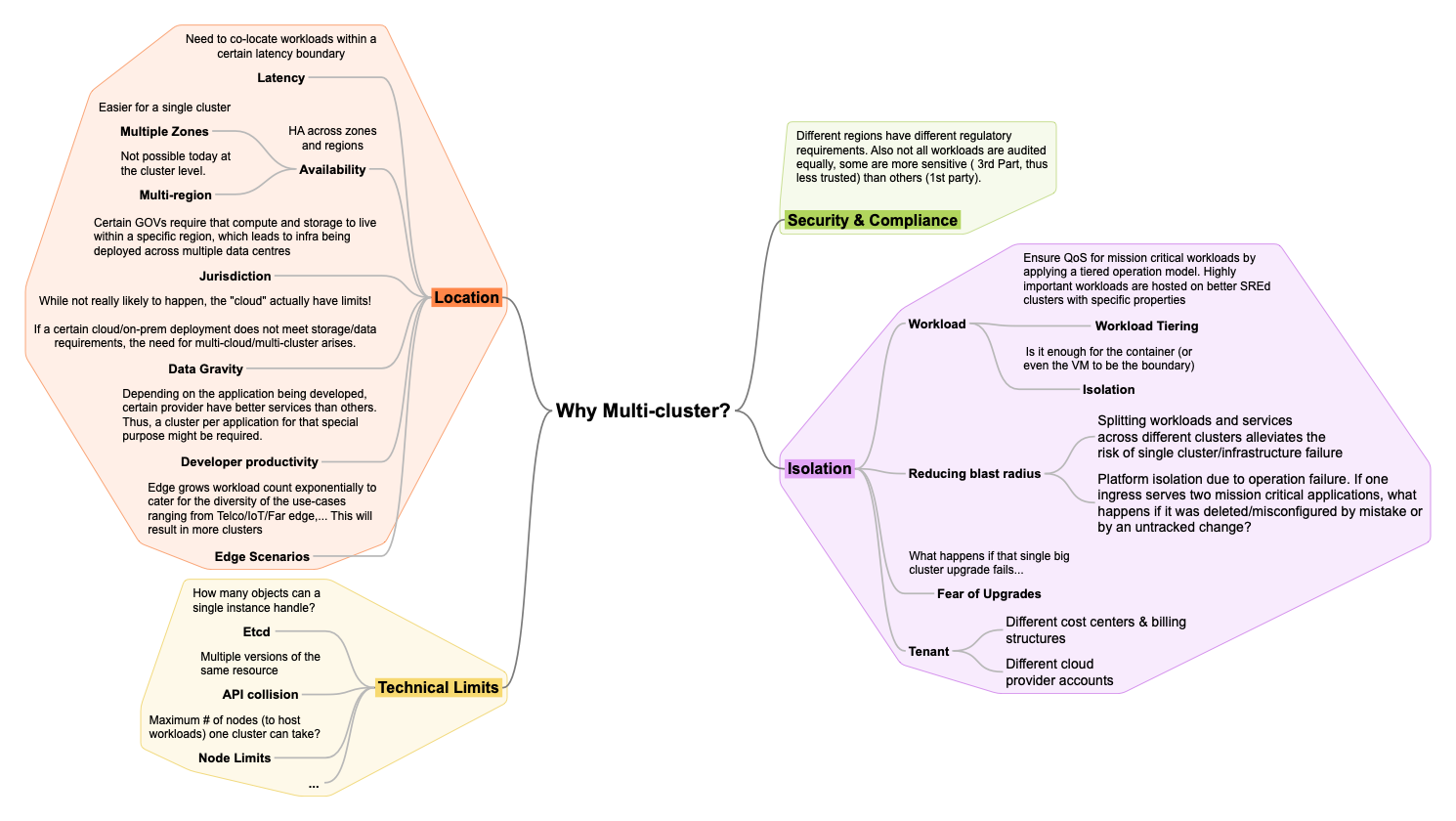
Multi-cluster is becoming an industry need today not because this is where trend is going but because it’s the only viable path today to solve for many of our customer’s use-cases. Below is some reasoning why multi-cluster is a NEED:
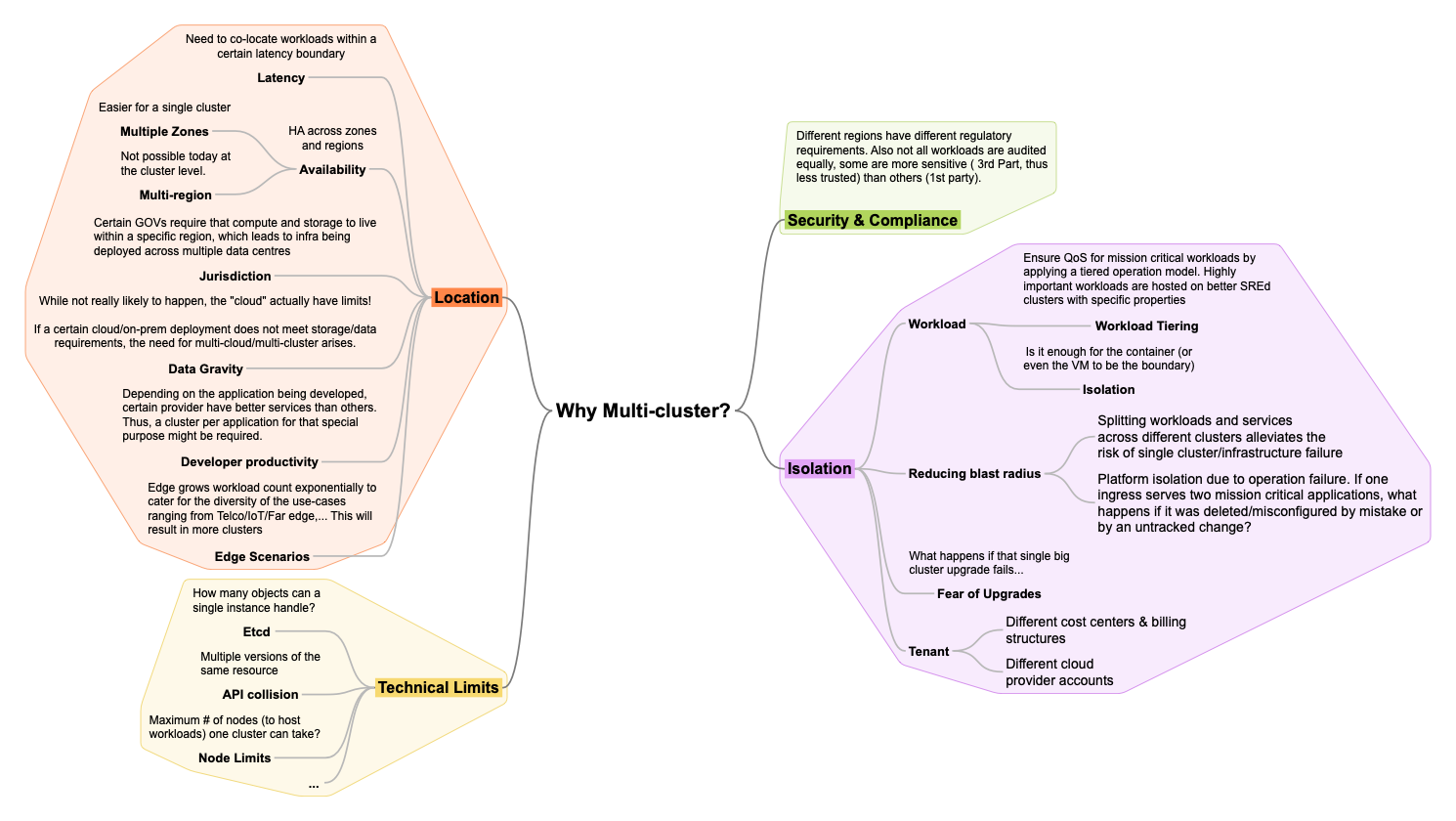
As a result, multi-cluster management is a defining category in the market where Red Hat plays a key role. Today Red Hat solves for multi-cluster via RHACM and MCE. The goal is to simplify fleet management complexity by providing a single pane of glass to observe, secure, police, govern, configure a fleet. I.e., the operand is no longer one cluster but a set, a fleet of clusters.
HyperShift logically centralized architecture, as well as native separation of concerns and superior cluster lifecyle management experience, makes it a great fit as the foundation of our multi-cluster management story.
Thus the following stories are important for HyperShift:
- When lifecycling OpenShift clusters (for any OpenShift form factor) on any of the supported providers from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin):
- I want to be able to use a consistent UI so I can manage and operate (observe, govern,...) a fleet of clusters.
- I want to specify HA constraints (e.g., deploy my clusters in different regions) while ensuring acceptable QoS (e.g., latency boundaries) to ensure/reduce any potential downtime for my workloads.
- When operating OpenShift clusters (for any OpenShift form factor) on any of the supported provider from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin):
- I want to be able to backup any critical data so I am able to restore them in case of hosting service cluster (management cluster) failure.
Refs:
- Agenda/Notes - HyperShift/ACM UX Sync
- https://coreos.slack.com/archives/C02TPGYJ6NN/p1657117542026339
- AWS UI and Agent Provisioning UI mocks
Hosted control planes APIs are stable for consumption.
HyperShift is the core engine that will be used to provide hosted control-planes for consumption in managed and self-managed.
Main user story: When life cycling clusters as a cluster service consumer via HyperShift core APIs, I want to use a stable/backward compatible API that is less susceptible to future changes so I can provide availability guarantees.
Ref: What are we missing in Core HyperShift for GA Readiness?
Customers are not paying for control planes/infra components.
Customers do not pay Red Hat more to run HyperShift control planes and supporting infrastructure than Standalone control planes and supporting infrastructure.
Assumptions:
- A customer will be able to associate a cluster as “Infrastructure only”
- E.g. one option: management cluster has role=master, and role=infra nodes only, control planes are packed on role=infra nodes
- OR the entire cluster is labeled infrastructure , and node roles are ignored.
- Anything that runs on a master node by default in Standalone that is present in HyperShift MUST be hosted and not run on a customer worker node.
HyperShift - proposed cuts from data plane
HyperShift has an HA and a DR story
When operating OpenShift clusters (for any OpenShift form factor) from MCE/ACM/OCM/CLI as a Cluster Service Consumer (RH managed SRE, or self-manage SRE/admin) I want to be able to migrate CPs from one hosting service cluster to another:
- as means for disaster recovery in the case of total failure
- so that scaling pressures on a management cluster can be mitigated or a management cluster can be decommissioned.
More information:
Hosted control planes reports metrics on usage/adoption
To understand usage patterns and inform our decision making for the product. We need to be able to measure adoption and assess usage.
See Hosted Control Planes (aka HyperShift) Strategy [Live Document]
Hosted control plane is observable
Whether it's managed or self-managed, it’s pertinent to report health metrics to be able to create meaningful Service Level Objectives (SLOs), alert of failure to meet our availability guarantees. This is especially important for our managed services path.
HyperShift is in parity with top-level add-on operators
https://issues.redhat.com/browse/OCPPLAN-8901
Unblock HyperShift as a backend to managed services
HyperShift for managed services is a strategic company goal as it improves usability, feature, and cost competitiveness against other managed solutions, and because managed services/consumption-based cloud services is where we see the market growing (customers are looking to delegate platform overhead).
We should make sure our SD milestones are unblocked by the core team.
Note
This feature reflects HyperShift core readiness to be consumed. When all related EPICs and stories in this EPIC are complete HyperShift can be considered ready to be consumed in GA form. This does not describe a date but rather the readiness of core HyperShift to be consumed in GA form NOT the GA itself.
- GA date for self-managed will be factoring in other inputs such as adoption, customer interest/commitment, and other factors.
- GA dates for ROSA-HyperShift are on track, tracked in milestones M1-7 (have a look at https://issues.redhat.com/browse/OCPPLAN-5771)
{kind=link}
{kind=link}
- is documented by
-
ACM-4338 Designate nodes for hosting control-plane to avoid charging
-

- Closed
-
- is related to
-
HOSTEDCP-498 Support telemetry reporting for standalone HyperShift hosted clusters
-

- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
HOSTEDCP-486 Clean up in-cluster cloud resources on hostedcluster deletion
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- relates to
-
-
- Release Pending
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-