-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
None
-
None
-
None
-
False
-
-
False
-
en-US (English)
-
Critical
-
Customer Facing, Customer Reported
Please fill in the following information:
| URL: | . |
| Reporter RHNID: | pperaltads |
| Section Title: | - |
Issue description
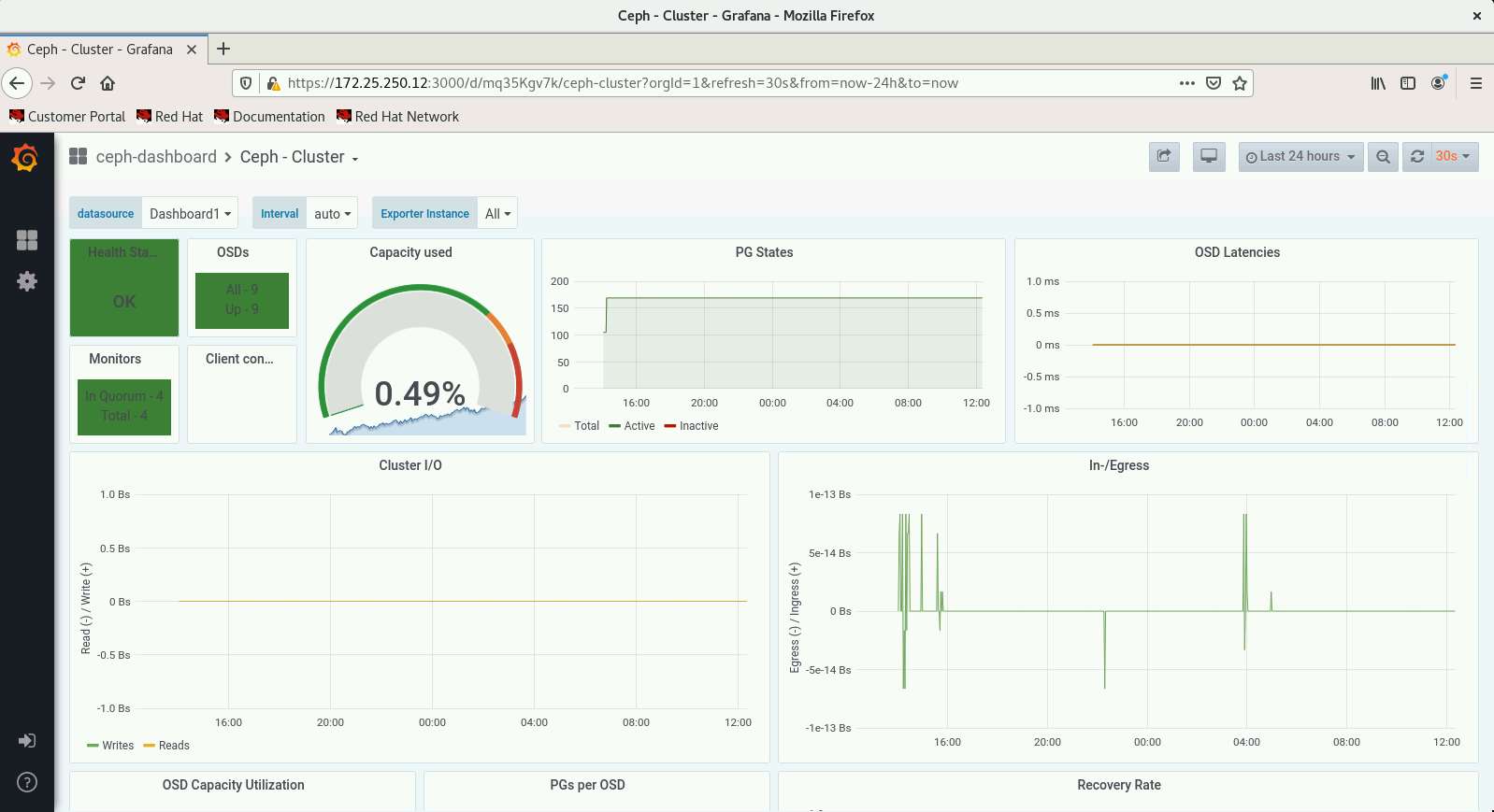
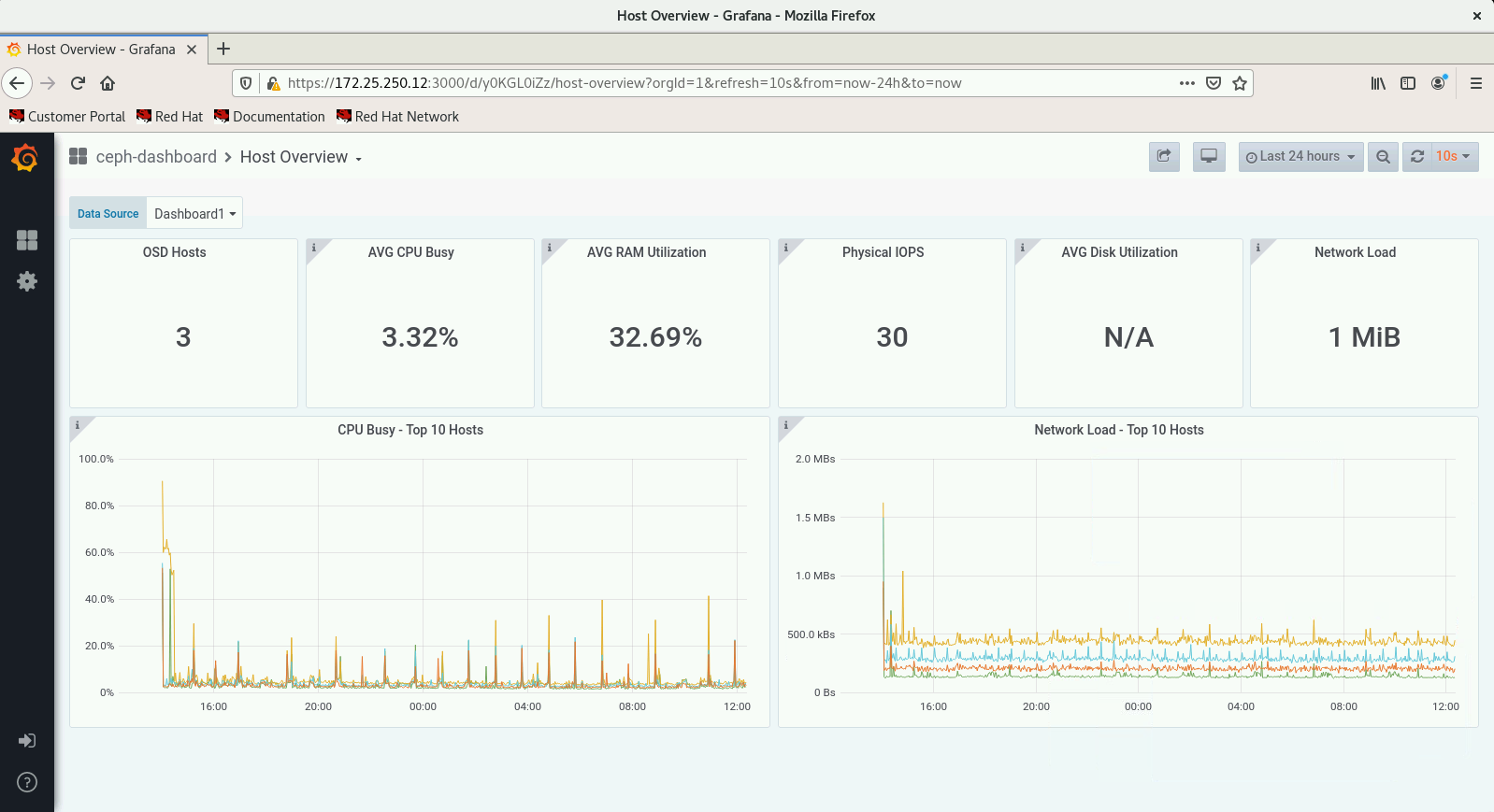
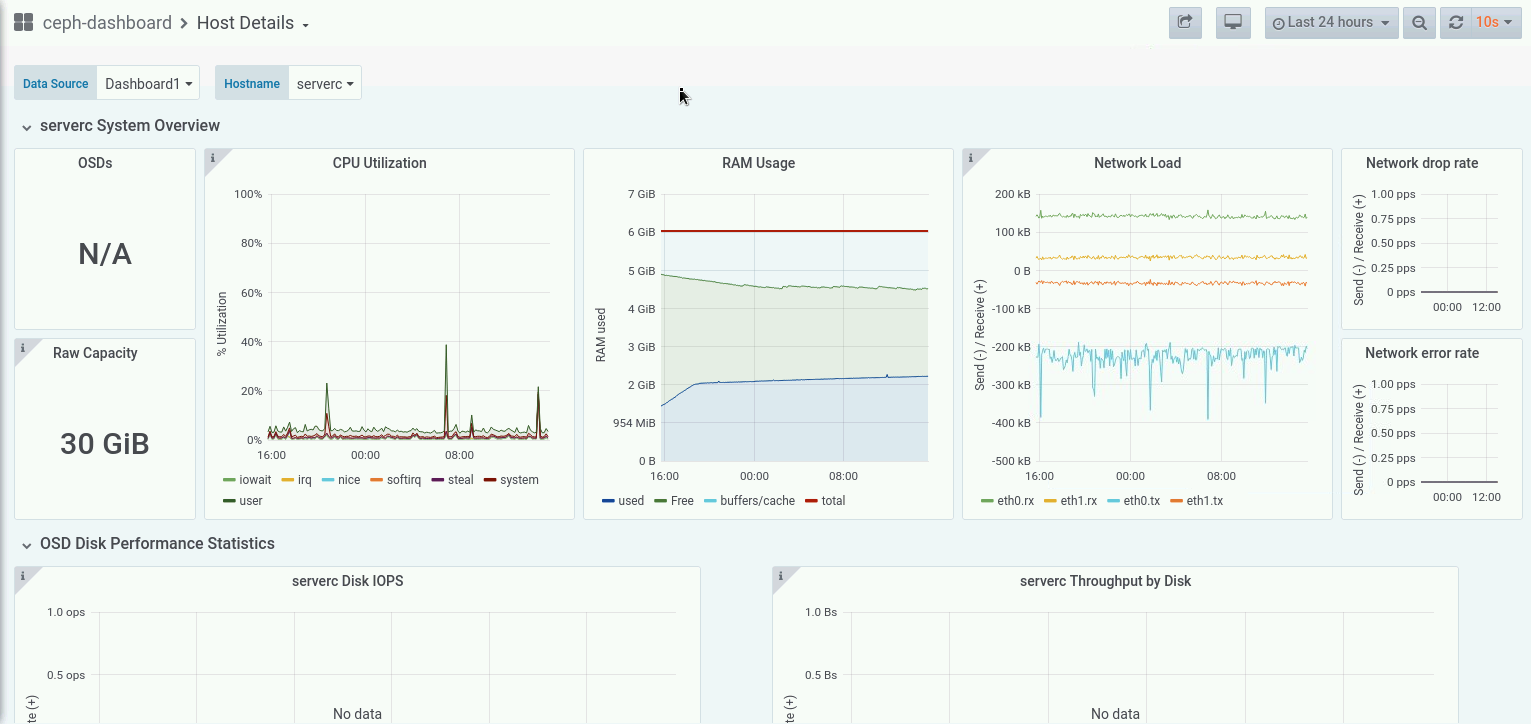
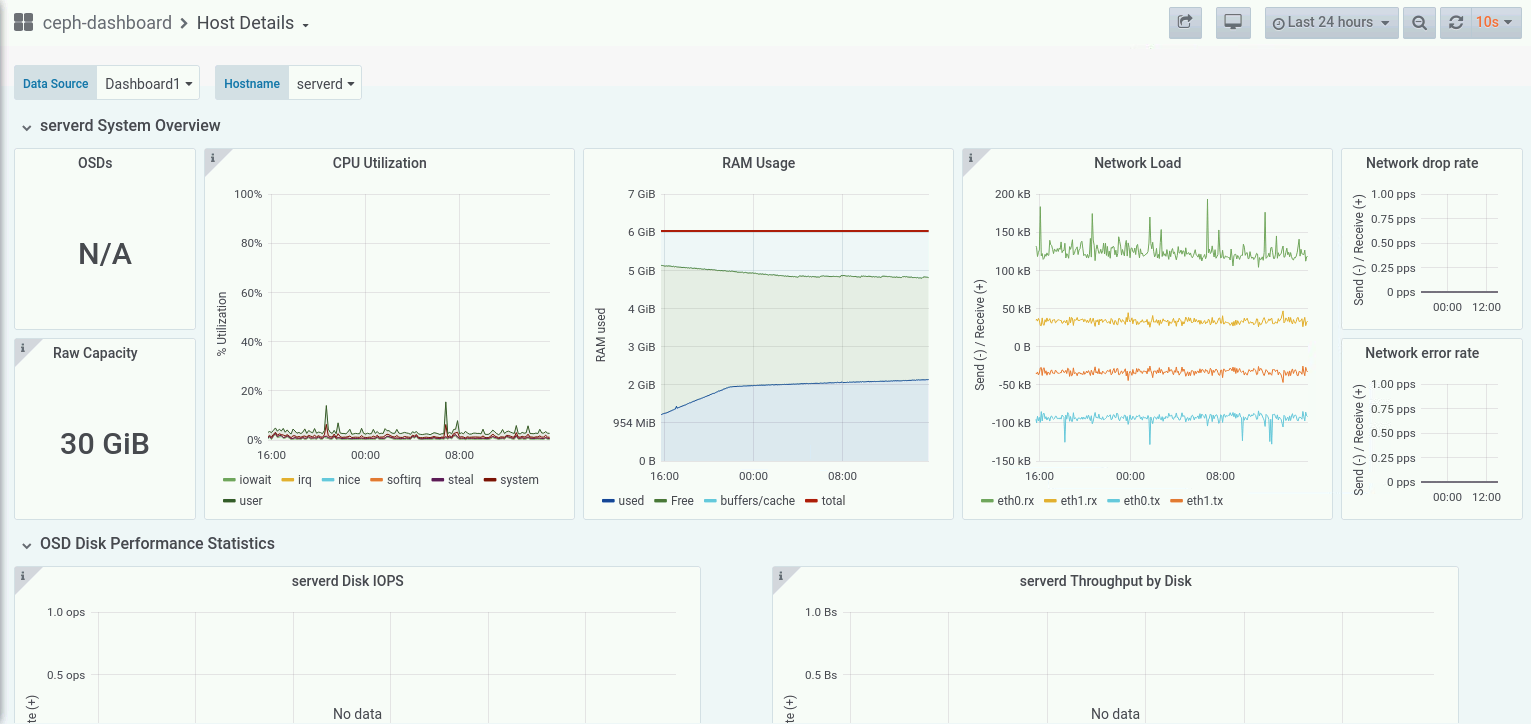
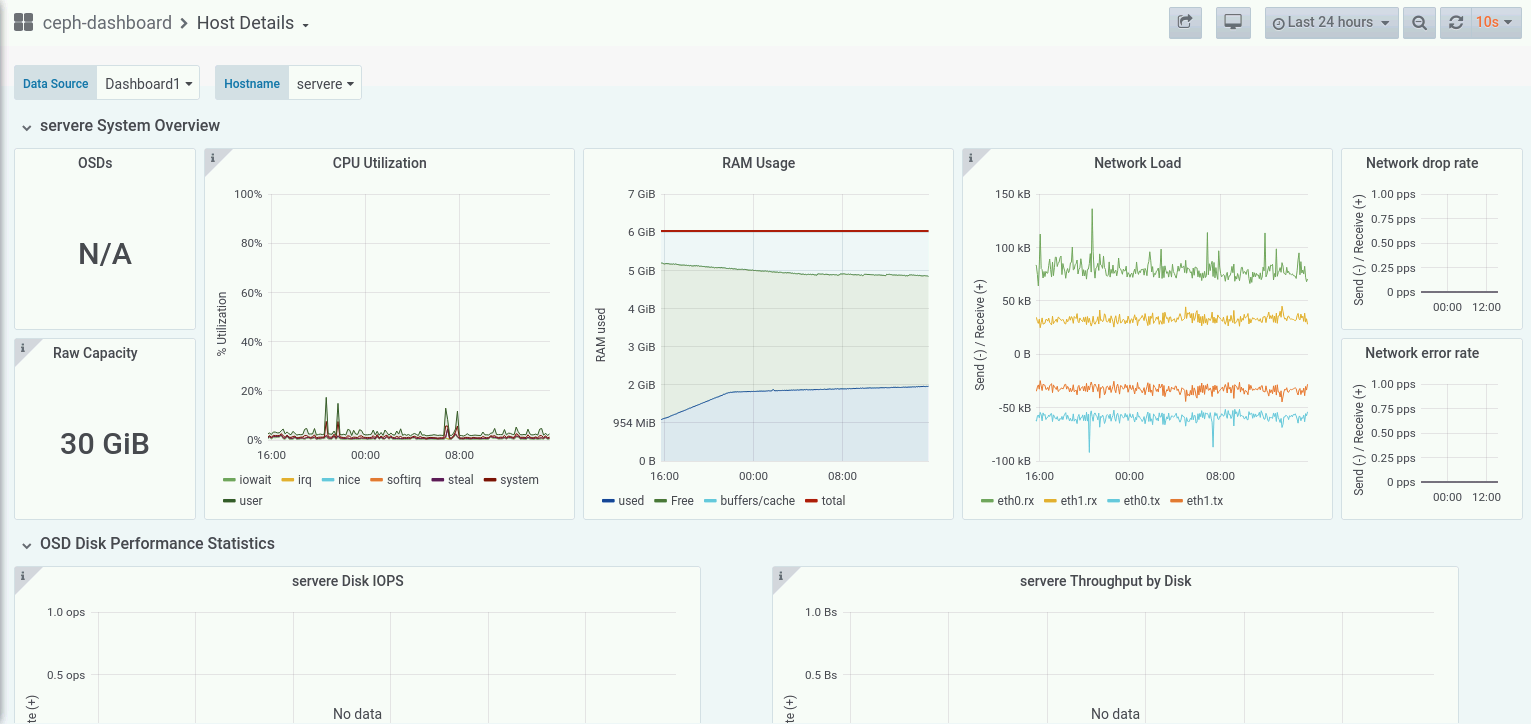
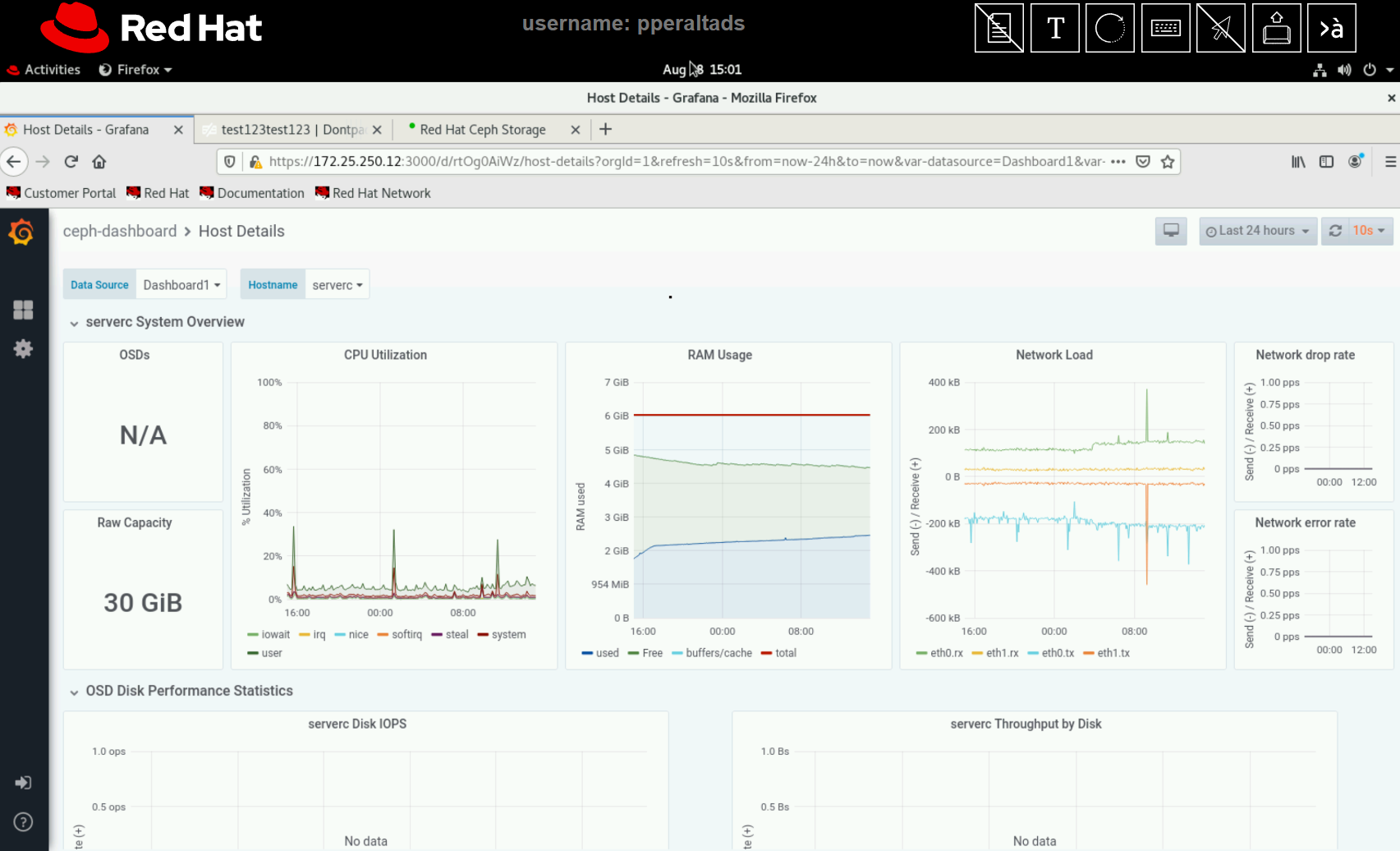
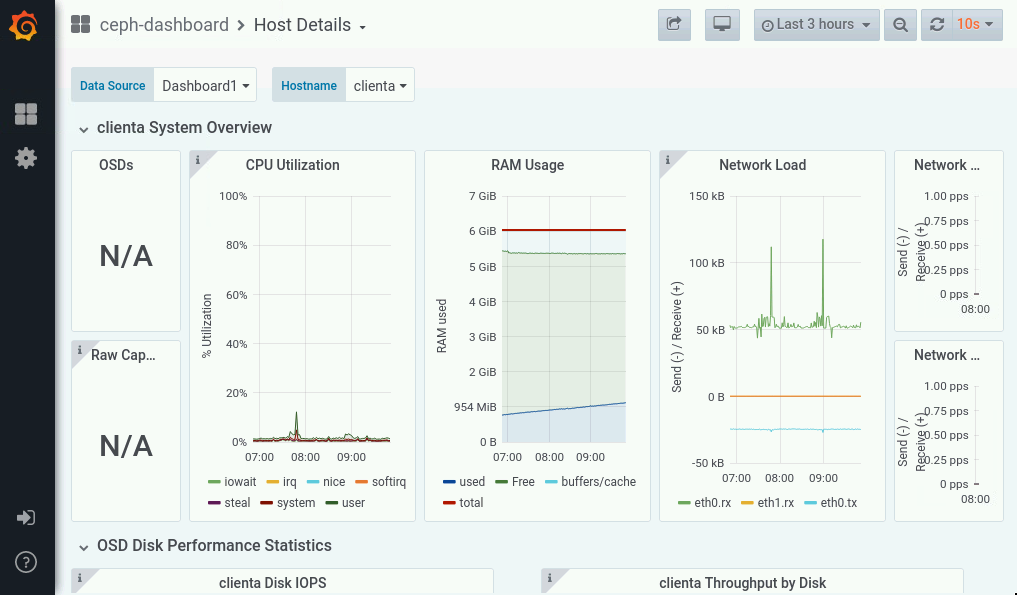
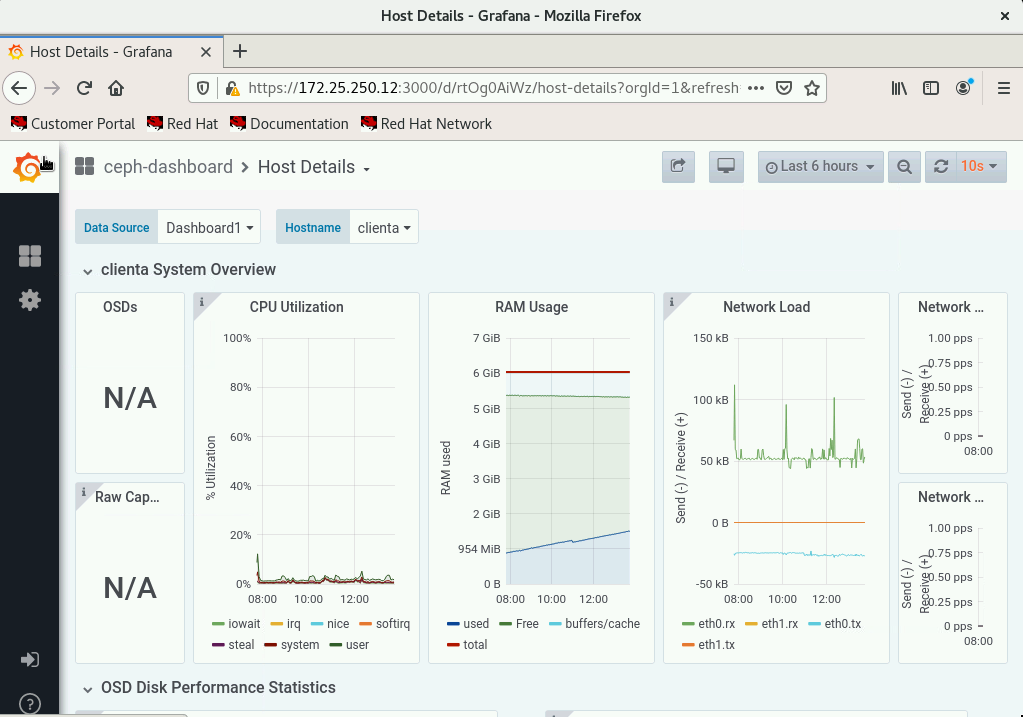
Today we faced a strange issue regarding CL260 VM Labs environment. After some hours of inactivity the cluster begins to behave erraticly killing some OSDs and other Ceph cluster components in serverc, serverd and servere
Steps to reproduce:
- Spawn a fresh CL260 ROL labs
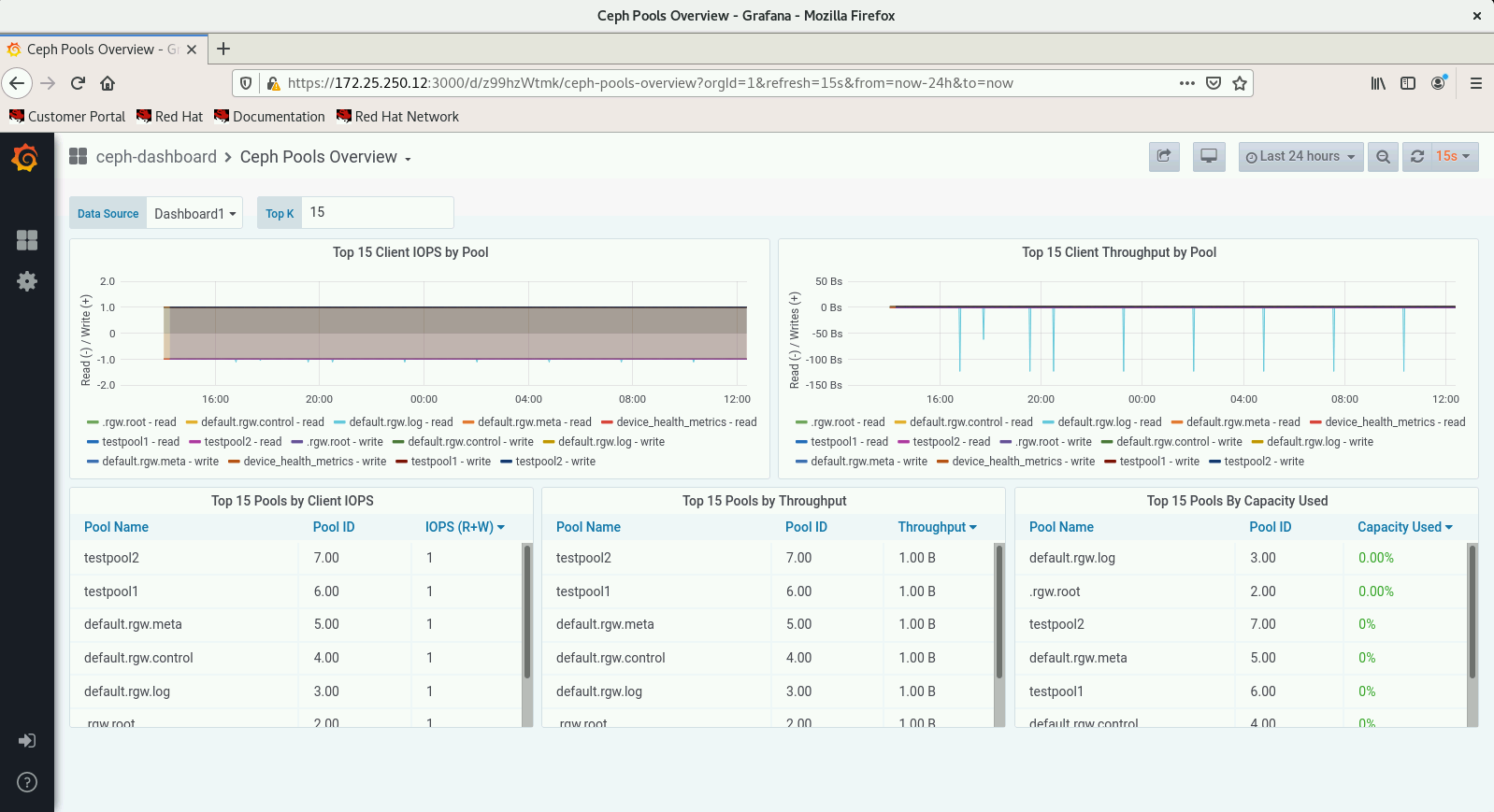
- Create some pools with
$ ssh admin@clienta $ sudo cephadm shell # ceph osd pool create testpool1 32 32 replicated # ceph osd pool create testpool2 32 32 replicated # ceph status # ceph health
- Let it sit for 2 days without shuting down the cluster or powering off the VMs.
- Verify the Ceph cluster health on clienta with
# ceph health
Workaround:
Shutdown VMs at the end of the class, start them up at the beginning of the class. If OOM crashed the cluster, the only solution is to delete and recreate the labs.
Expected result:
VMs do not need to be rebooted, deleted or stopped in any way during class, like other Red Hat Courses.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}