-
Bug
-
Resolution: Done
-
 Major
Major
-
DO380 - OCP4.14-en-1-20240220
-
None
-
False
-
-
False
-
0
-
-
-
en-US (English)
Please fill in the following information:
| URL: | https://role.rhu.redhat.com/rol-rhu/app/courses/do380-4.14/pages/pr01s02 |
| Reporter RHNID: | rhn-support-ablum |
| Section Title: | (all) |
Issue description
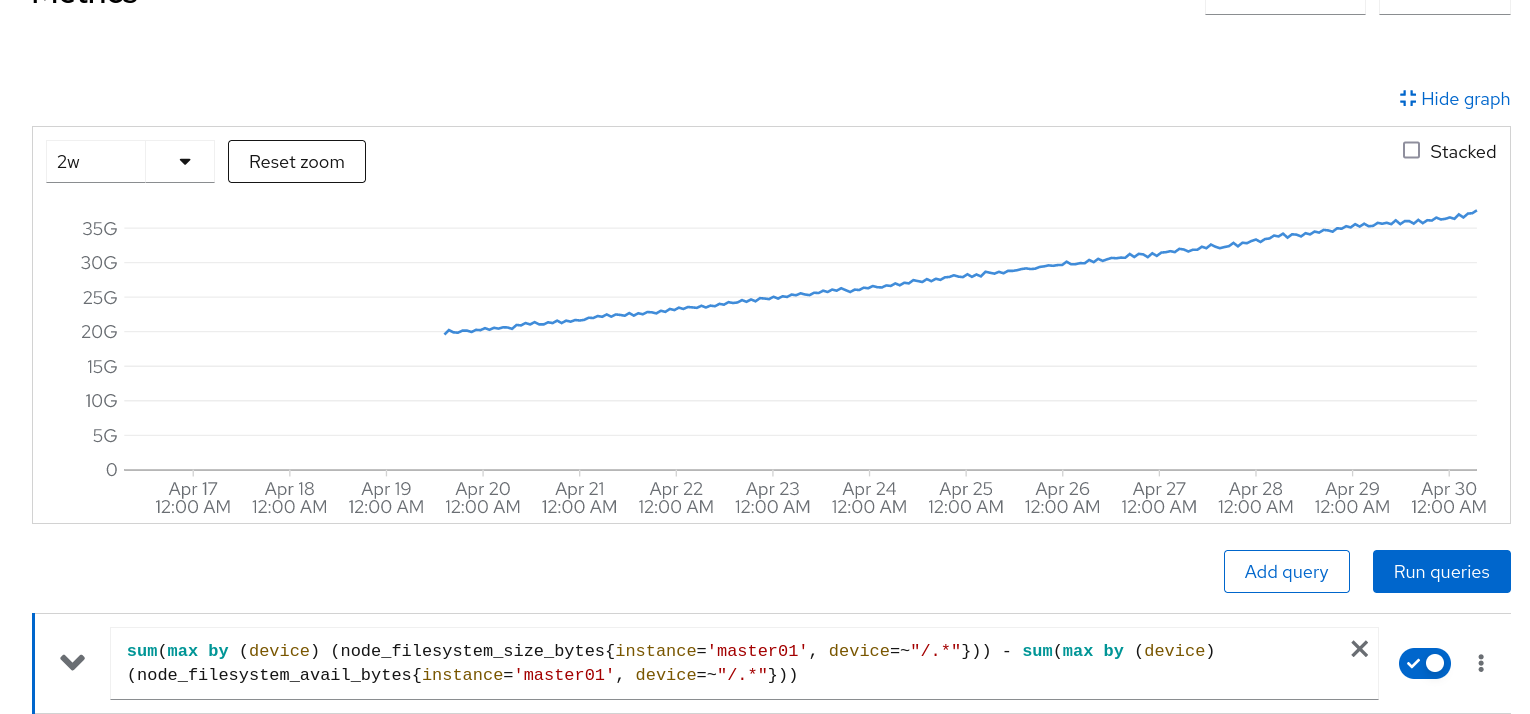
For DO380 environments running longer than 7 days, prometheus will consume enough ephemeral storage on the nodes where the prometheus-k8s-X pods run that the kubelet triggers its hard eviction to clean up space. This results in a number of issues with various cluster operators as it effectively removes two of the nodes from the cluster (via the NoSchedule key:node.kubernetes.io/disk-pressure taint).
Steps to reproduce:
Use the cluster normally for longer than 7 days. See screenshot for the metrics trendline for a node. Prometheus is using about 17G of the 40G available on the node.
Workaround:
Killing off the prometheus pods will result in them getting rescheduled to another node. This will temporarily fix the issue until the ephemeral storage is used up again later.
[student@workstation ~]$ oc scale statefulset/prometheus-k8s -n openshift-monitoring --replicas 0
NOTE: The openshift monitoring operator will automatically re-adjust the replica count here resulting in two new prometheus-k8s-X pods.

{kind=link}