-
Bug
-
Resolution: Done-Errata
-
 Major
Major
-
quay-v3.9.2
-
False
-
-
False
-
Documentation (Ref Guide, User Guide, etc.), Compatibility/Configuration, User Experience
-
-
-
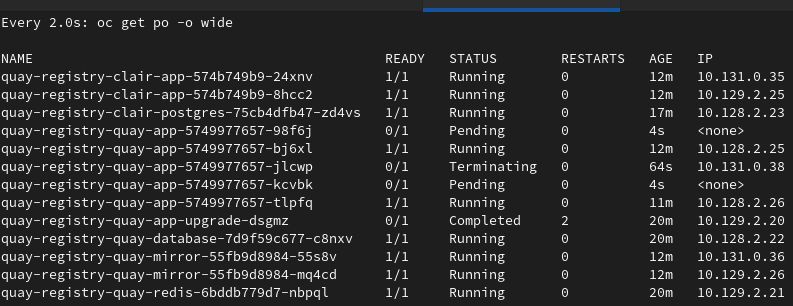
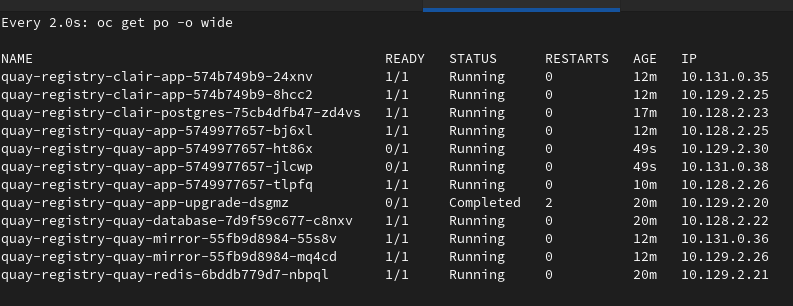
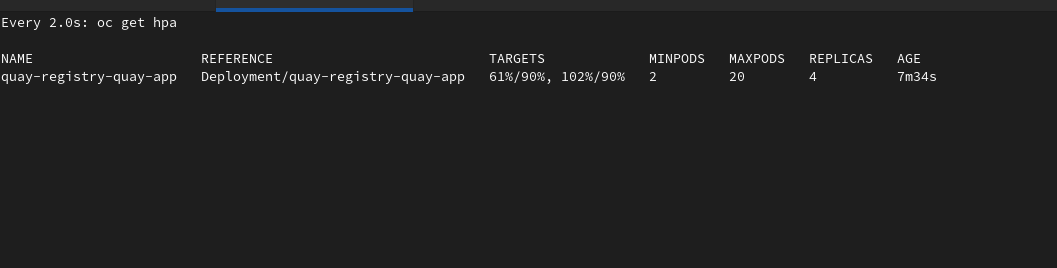
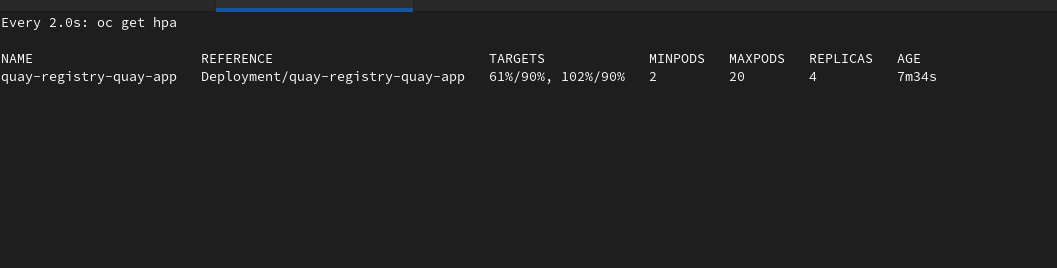
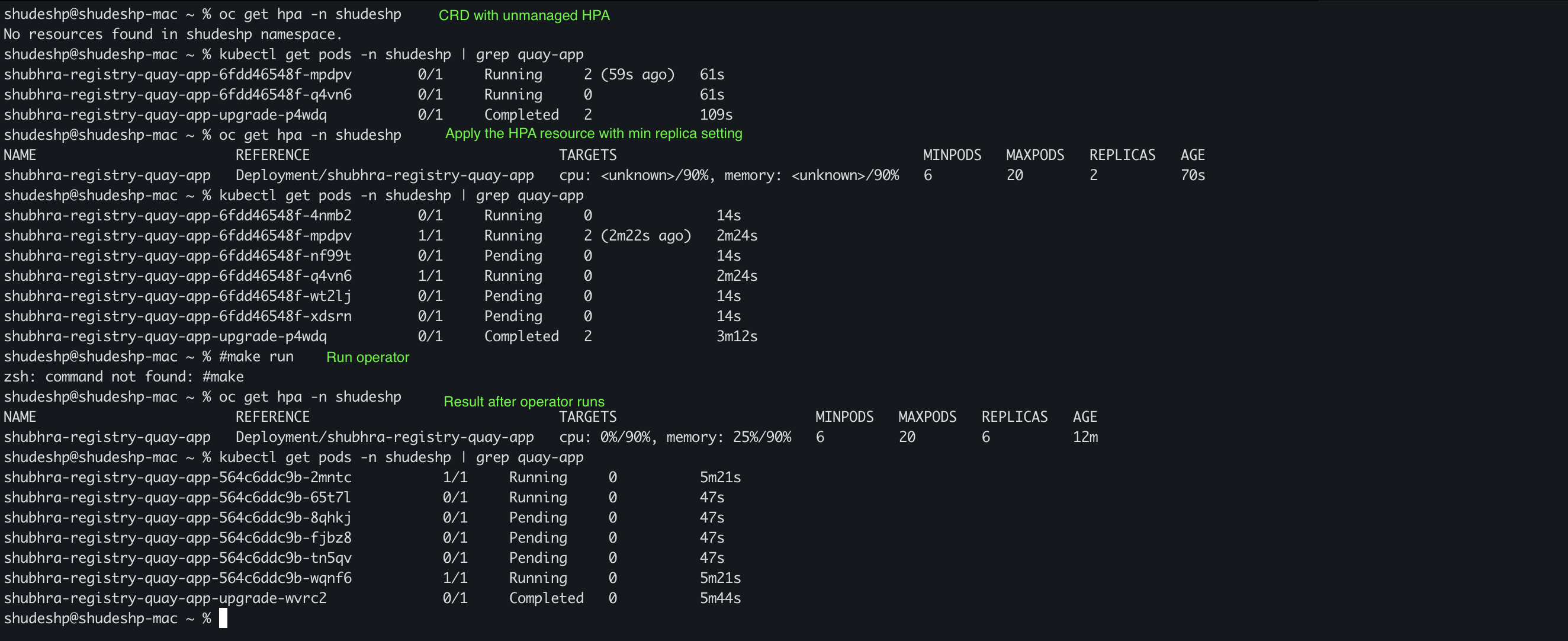
Editing the Quay CRD in order to set HPA as unmanaged and then increase the number of minReplicas in the HPA resources causes a conflict between Operator and HPA in the management of replicas.
As a consequence, new pods are created by the HPA but removed by the Operator continuously, so the HPA stops working.
This behaviour can be observed in the following scenarios:
- HPA set as unmanaged in Quay CRD, keeping the deployment as managed, and minReplicas of HPA increased
- HPA set as unmanaged in Quay CRD, keeping the deployment as managed with an override to increase the number of replicas, and minReplicas of HPA increased to the same value
- In this case, continuous pods creation and deletion start when HPA tries to scale them
It seems there is not a way to increase pod replicas while keeping the HPA properly scaling them.
- incorporates
-
RFE-4986 Allow overrides to modify Quay HPA components
-

- Approved
-
- is cloned by
-
-
- New
-
- is related to
-
-
- Closed
-
- links to
-
 RHBA-2024:143034
Red Hat Quay v3.13.2 bug fix release
RHBA-2024:143034
Red Hat Quay v3.13.2 bug fix release
- mentioned on
