-
Bug
-
Resolution: Done
-
 Major
Major
-
quay-v3.4.1
-
False
-
False
-
Undefined
-
Firstly, sorry for the vague summary. However, the problem is somewhat complicated and I couldn't fit it in there anyway. We've been receiving reports from image owners that their already graded (and therefore indexed) images are not reflecting new vulnerabilities as they are released by RH Product Security in OVAL v2 streams. We've observed that this only happens to some of the images without any obvious pattern, seemingly randomly.
On EXD side, I created CWFHEALTH-257 and spent a lot of time investigating this issue. I strongly recommend anyone working on this to go through the issue's comments, especially those ones I'm going to highlight here. Re-writing all of them here would be unnecessary duplication, but let me try to summarize my findings. I believe there are two possible reasons why notifications are lost. It might be either of them, or possibly both.
Possible root causes
1st theory. Notifier processes a big update operation. It crashes for some reason, might be OOM kill, might be whatever else. The original UO wasn't fully processed and a new one appears. The new one is processed but the previous one wasn't and here we have the data loss. See also this comment.
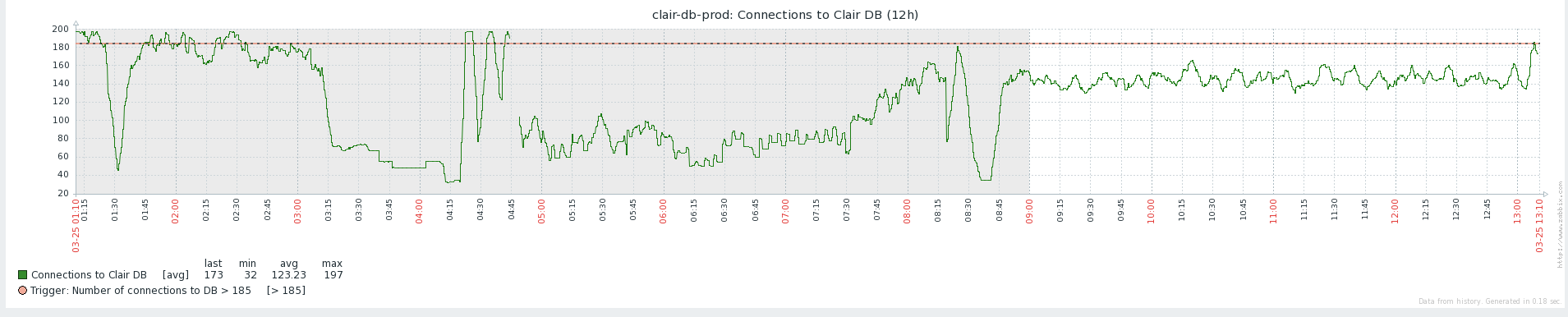
2nd theory. Notifier floods indexer with requests. Indexer eats up all of the available DB connections when causes that notifier gets error instead of proper response in some cases. See this comment and couple comments that follow.
Other considerations
Hank recently worked on PROJQUAY-1693. The impetus for this work came from the GH issue I originally reported here: https://github.com/quay/clair/issues/1186. While this definitely helps with notifier crashing because of runnnig out of memory, it doesn't solve the core of the issue. Notifications still might get lost because:
a. Notifier may crash for whatever other reason than memory
b. Indexer may still eat up all the DB connections
As for the DB connections, it seems that the problem might have started with this PR: https://github.com/quay/claircore/pull/266. From mine and Ales' experience, we haven't see it before. I reported this in GH: https://github.com/quay/claircore/issues/308 I also prepared PR (https://github.com/quay/claircore/pull/310) which helped somewhat, but ultimately didn't fix the problem.

{kind=link}
{kind=link}
{kind=link}