-
Bug
-
Resolution: Unresolved
-
 Undefined
Undefined
-
OpenShift 4.15, OpenShift 4.16, OpenShift 4.17, OpenShift 4.18, openshift-4.19
-
None
-
None
-
Quality / Stability / Reliability
-
False
-
-
1
-
None
-
None
-
None
-
Sprint 270
-
None
-
None
-
None
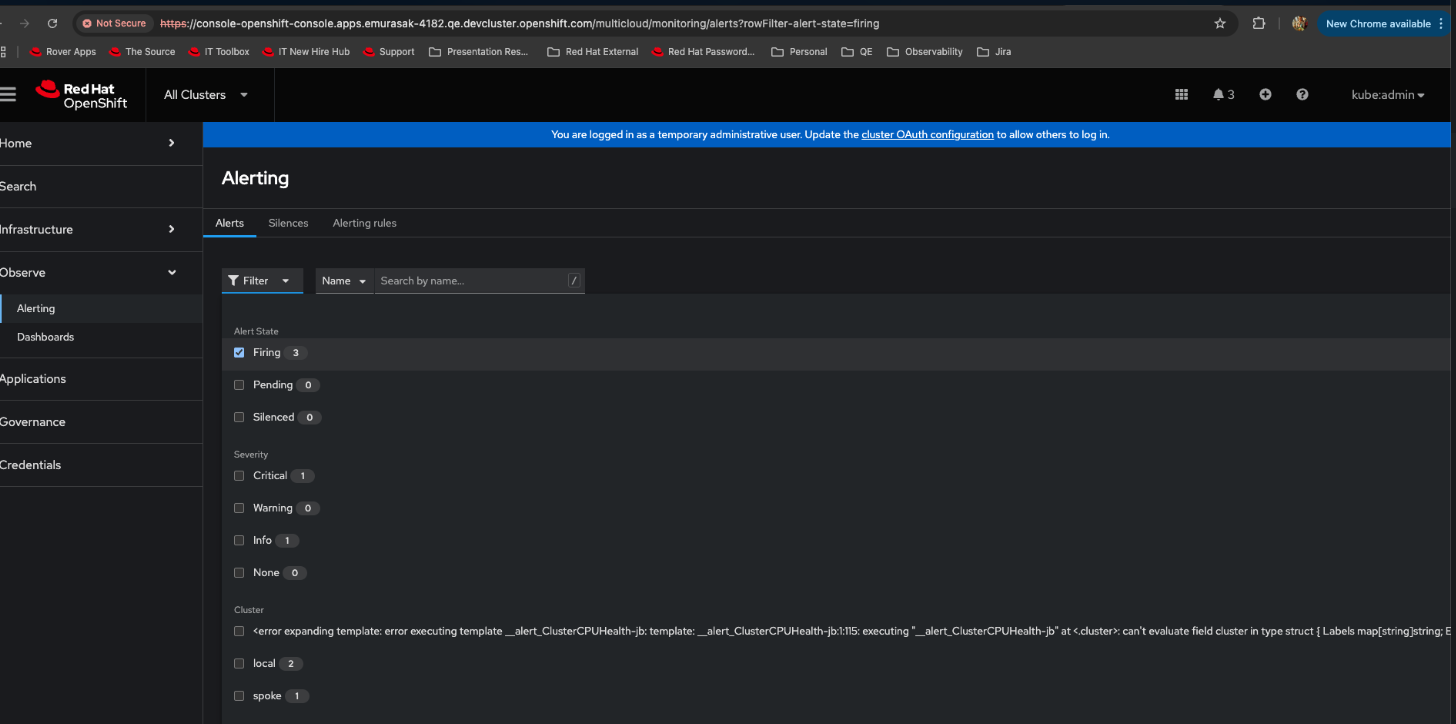
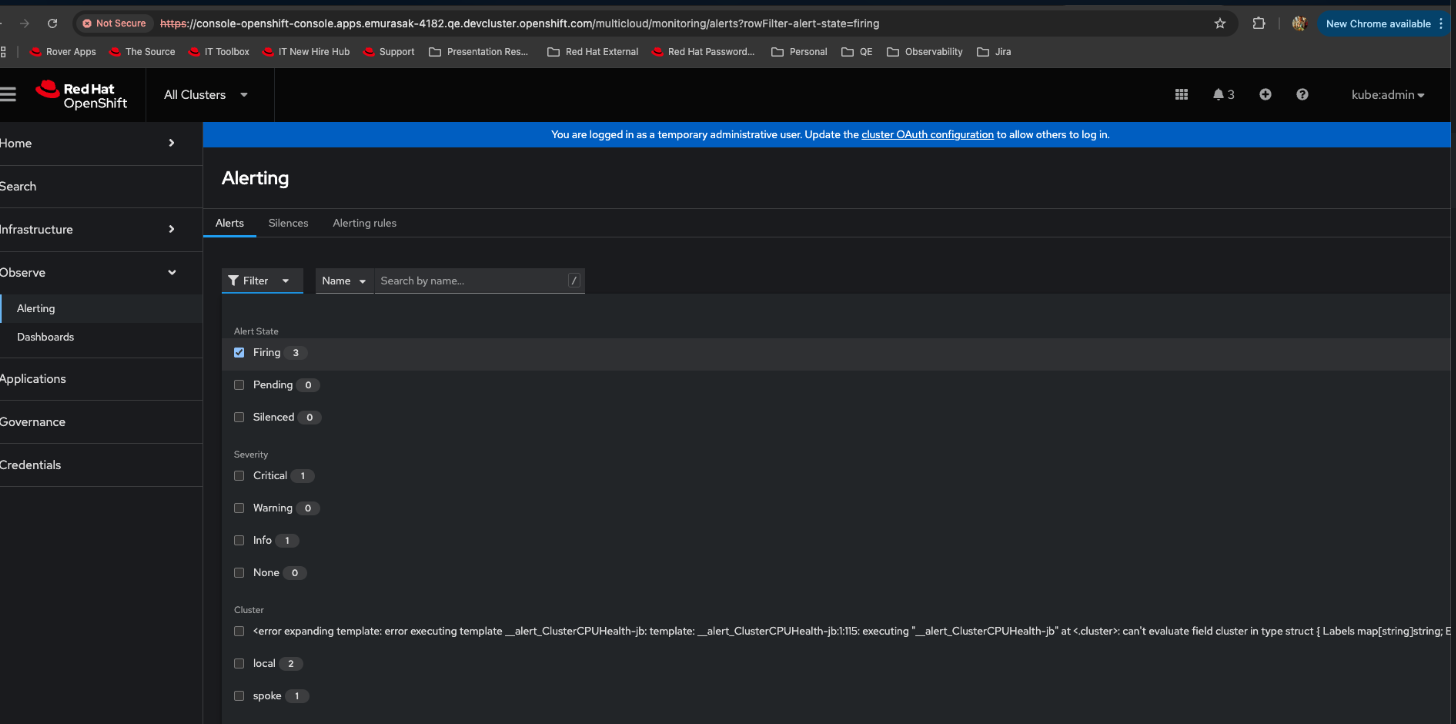
Problem:
In case we have an issue in the cluster-name, as the example in the YAML file, it is showing a huge cluster name, not really parsed / truncated.
oc apply -f - <<EOF
apiVersion: v1
data:
custom_rules.yaml: |
groups:
- name: alertrule-testing
rules:
- alert: Watchdog
annotations:
summary: An alert that should always be firing to certify that Alertmanager is working properly.
description: This is an alert meant to ensure that the entire alerting pipeline is functional.
expr: vector(1)
labels:
instance: "local"
cluster: "local"
clusterID: "111111111"
severity: info
- alert: Watchdog-spoke
annotations:
summary: An alert that should always be firing to certify that Alertmanager is working properly.
description: This is an alert meant to ensure that the entire alerting pipeline is functional.
expr: vector(1)
labels:
instance: "spoke"
cluster: "spoke"
clusterID: "22222222"
severity: warn
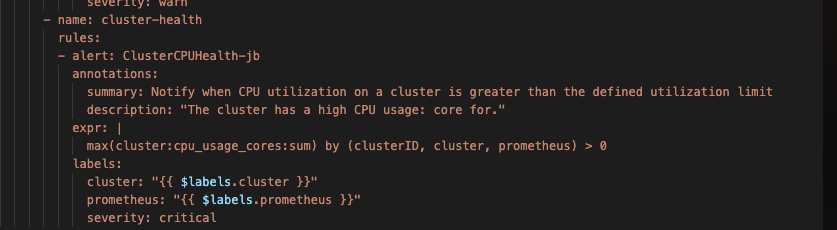
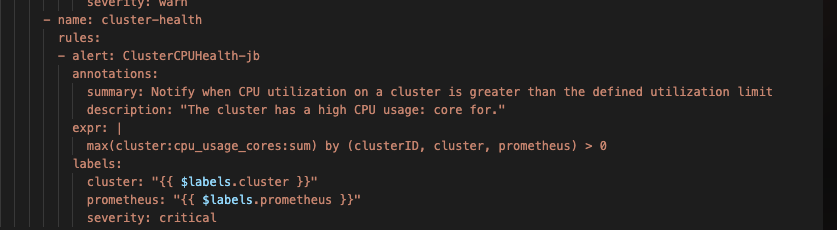
- name: cluster-health
rules:
- alert: ClusterCPUHealth-jb
annotations:
summary: Notify when CPU utilization on a cluster is greater than the defined utilization limit
description: "The cluster has a high CPU usage: core for."
expr: |
max(cluster:cpu_usage_cores:sum) by (clusterID, cluster, prometheus) > 0
labels:
cluster: "{{ $labels.cluster }}"
prometheus: "{{ $labels.prometheus }}"
severity: critical
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"custom_rules.yaml":"groups:\n - name: alertrule-testing\n rules:\n - alert: Watchdog\n annotations:\n summary: An alert that should always be firing to certify that Alertmanager is working properly.\n description: This is an alert meant to ensure that the entire alerting pipeline is functional.\n expr: vector(1)\n labels:\n instance: \"local\"\n cluster: \"local\"\n clusterID: \"111111111\"\n severity: info\n - alert: Watchdog-spoke\n annotations:\n summary: An alert that should always be firing to certify that Alertmanager is working properly.\n description: This is an alert meant to ensure that the entire alerting pipeline is functional.\n expr: vector(1)\n labels:\n instance: \"spoke\"\n cluster: \"spoke\"\n clusterID: \"22222222\"\n severity: warn\n - name: cluster-health\n rules:\n - alert: ClusterCPUHealth-jb\n annotations:\n summary: Notify when CPU utilization on a cluster is greater than the defined utilization limit\n description: \"The cluster has a high CPU usage: {{ }} core for {{ .cluster }} {{ .clusterID }}.\"\n expr: |\n max(cluster:cpu_usage_cores:sum) by (clusterID, cluster, prometheus) \u003e 0\n labels:\n cluster: \"{{ .cluster }}\"\n prometheus: \"{{ .prometheus }}\"\n severity: critical\n"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"thanos-ruler-custom-rules","namespace":"open-cluster-management-observability"}}
creationTimestamp: "2024-11-01T06:16:10Z"
labels:
cluster.open-cluster-management.io/backup: ""
name: thanos-ruler-custom-rules
namespace: open-cluster-management-observability
resourceVersion: "192432"
uid: 969bf381-0963-45fb-b1cb-11270c982ea2
EOF
Solution:
Per rh-ee-pyurkovi, We could file a bug that we should truncate the cluster-name after a certain length, but the cluster label is set to that value. So it is accurate for that to appear there.
- relates to
-
OU-660 Remove usage of console css classes
-
- Closed
-
- links to