-
Feature
-
Resolution: Done
-
 Critical
Critical
-
None
-
Product / Portfolio Work
-
-
0% To Do, 0% In Progress, 100% Done
-
False
-
None
-
False
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
Undefined
Epic Goal
In the standalone version of OpenShift, a cluster is a collection of master and worker nodes, the master and the workers are usually co-located. With HyperShift, a cluster is divided into a hosted control plane (usually residing on a dedicated management cluster (pre-created)), and worker nodes. Together, the control plane and the worker nodes form a guest cluster.
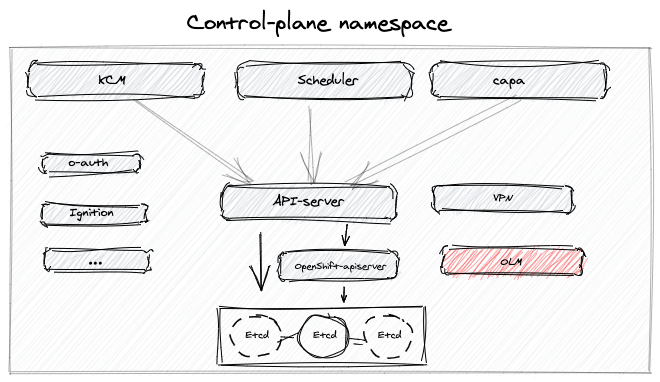
Each cluster control-plane in HyperShift gets an own dedicated namespace, this namespace will be used to host the control-plane pods, such as kube-apiserver, scheduler, kcm (and potentially OLM).
The goal of this EPIC is to investigate adding OLM as a HyperShift control-plane component residing on the hosted-cluster namespace.

Why is this important?
One of HyperShift's goals is to make clusters more focused on workloads, this is achieved by moving out all the control-plane bits (e.g., API-server, KCM, MCO, ..) to centrally controlled management cluster, and keep the guest workers focused only on running workloads. Not only does this save resources, but it makes the overall cluster less prune to human erros (i.e., users mistakenly adding, modifying, or even removing system resources).
Scenarios
- As a developer, I would like to dedicate my worker node resources only to running my workloads.
- As a cluster-admin, I would like to focus on only maintaining the developer's resources.
Acceptance Criteria
We must resolve the following impacts/needs:
- Implications for blocking upgrades based on operator compatibility (there is no CVO/ClusterOperator status object controlling upgrades). Namely, does upgradeable=false have meaning in a hypershift cluster?
Resolved items:
- do control-plane components have operators still?
No, the existing ones do not. But we did reuse the operator from some OLM components (catalog operator, olm operator)
- How does packageserver get installed on the control plane side
We abandoned the CSV that was being laid down by CVO, and instead had hypershift create the packageserver resources directly.
- Ensuring that user installed operators get deployed to a predefined nodepool (e.g. via nodeselector. only some nodes may have access to talk to the controlplane/api-server, so operator controllers need to run there)
Can set a nodeselector on the subscription today, is that sufficient for now?
- Does running in this mode have any bearing on the planned new operator api?
needs more thinking about what it means to be aware of multiple apiservers
- Does running in this mode have any bearing on the planned "descoped operators" architecture?
feels like no as long as we can assert that the operator+operand are always colocated either in the control-plane NS, or in the guest cluster.
- How could OLM install operators that run on the control-plane side (service mesh, for example)
does subscription get created in the controlplane NS, or in the guest cluster?
for now the expectation is that operators that run in the control plane side would be installed on the mgmt cluster.
- OLM reads catalog content over the pod network (grpc right now). Will we / how will we support user-provided catalogs in the guest cluster?
we are using the vpn client plus DNSmasq logic to allow olm components to resolve+talk to catalog pods in both the control plane and the guest cluster.
- How do users add additional catalogs/packages (normally done in the openshift-marketplace NS)
This remains the same. The operatorhub resource still exists in the guest cluster, the marketplace operator (in the control plane) watches it and creates catalogsources which lead to catalog pods in the control plane. Additional (user) catalogsources lead to catalog pods in the guest cluster.
components that consume the catalog pods will need to have vpn+dns configuration that allows them to talk to both the mgmt cluster and the guest cluster, since the catalog pods can be running in either location.
- If users are allowed to provide catalog content, will global catalogs live in the host or the guest? If in the host, how will admins of the guest cluster add global catalogs?
the catalogsource objects should live in the guest cluster. The catalog pods should live in the guest cluster with the exception of the marketplace catalogs which should run in the control-plane.
- What about olm operators that install apiservers? can they be installed in the guest cluster? is that allowed? what are the networking implications? (Note: we don't know of anyone except package server that does this today)
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- causes
-
OPRUN-2170 Identify ways to reduce OLM resource usage at scale
-
- Closed
-