-
Bug
-
Resolution: Done
-
 Normal
Normal
-
4.12
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
None
-
None
-
None
-
Sprint 224
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Searching recent 4.12 CI, there are a number of failures in the clusteroperator/machine-config should not change condition/Available test case:
$ w3m -dump -cols 200 'https://search.ci.openshift.org/?search=clusteroperator%2Fmachine-config+should+not+change+condition%2FAvailable&maxAge=48h&type=junit' | grep '4[.]12.*failures match' | sort
periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade (all) - 129 runs, 53% failed, 6% of failures match = 3% impact
periodic-ci-openshift-release-master-ci-4.12-e2e-aws-sdn-techpreview-serial (all) - 6 runs, 50% failed, 67% of failures match = 33% impact
periodic-ci-openshift-release-master-ci-4.12-e2e-azure-ovn-upgrade (all) - 60 runs, 50% failed, 3% of failures match = 2% impact
periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade (all) - 129 runs, 56% failed, 8% of failures match = 5% impact
periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-azure-sdn-upgrade (all) - 129 runs, 69% failed, 12% of failures match = 9% impact
periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-gcp-ovn-rt-upgrade (all) - 8 runs, 38% failed, 67% of failures match = 25% impact
periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-gcp-ovn-upgrade (all) - 60 runs, 57% failed, 6% of failures match = 3% impact
periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-gcp-sdn-upgrade (all) - 12 runs, 42% failed, 20% of failures match = 8% impact
periodic-ci-openshift-release-master-nightly-4.12-e2e-aws-sdn-upgrade (all) - 60 runs, 40% failed, 4% of failures match = 2% impact
periodic-ci-openshift-release-master-nightly-4.12-e2e-metal-ipi-sdn-serial-virtualmedia (all) - 6 runs, 100% failed, 17% of failures match = 17% impact
periodic-ci-openshift-release-master-nightly-4.12-e2e-metal-ipi-sdn-upgrade (all) - 6 runs, 67% failed, 25% of failures match = 17% impact
periodic-ci-openshift-release-master-nightly-4.12-e2e-metal-ipi-serial-ovn-dualstack (all) - 6 runs, 67% failed, 25% of failures match = 17% impact
periodic-ci-openshift-release-master-nightly-4.12-e2e-vsphere-ovn-techpreview-serial (all) - 9 runs, 56% failed, 20% of failures match = 11% impact
periodic-ci-openshift-release-master-nightly-4.12-upgrade-from-stable-4.11-e2e-metal-ipi-upgrade (all) - 6 runs, 100% failed, 17% of failures match = 17% impact
periodic-ci-openshift-release-master-nightly-4.12-upgrade-from-stable-4.11-e2e-metal-ipi-upgrade-ovn-ipv6 (all) - 6 runs, 83% failed, 20% of failures match = 17% impact
periodic-ci-openshift-release-master-okd-4.12-e2e-vsphere (all) - 25 runs, 100% failed, 4% of failures match = 4% impact
release-openshift-ocp-installer-e2e-gcp-serial-4.12 (all) - 6 runs, 83% failed, 20% of failures match = 17% impact
Doesn't seem like reason is getting set?
$ curl -s 'https://search.ci.openshift.org/search?name=periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade&search=clusteroperator%2Fmachine-config+should+not+change+condition%2FAvailable&maxAge=48h&type=junit&context=15' | jq -r 'to_entries[].value | to_entries[].value[].context[]' | grep 'clusteroperator/machine-config condition/Available status/False reason' Aug 31 01:13:56.724 - 698s E clusteroperator/machine-config condition/Available status/False reason/Cluster not available for [{operator 4.12.0-0.ci-2022-08-30-194744}] Aug 31 09:09:15.460 - 1078s E clusteroperator/machine-config condition/Available status/False reason/Cluster not available for [{operator 4.12.0-0.ci-2022-08-30-194744}] Sep 01 03:31:24.808 - 1131s E clusteroperator/machine-config condition/Available status/False reason/Cluster not available for [{operator 4.12.0-0.ci-2022-08-31-111359}] Sep 01 07:15:58.029 - 1085s E clusteroperator/machine-config condition/Available status/False reason/Cluster not available for [{operator 4.12.0-0.ci-2022-08-31-111359}]
Example runs in the job I've randomly selected to drill into:
$ curl -s 'https://search.ci.openshift.org/search?name=periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade&search=clusteroperator%2Fmachine-config+should+not+change+condition%2FAvailable&maxAge=48h&type=junit' | jq -r 'keys[]' https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade/1564757706458271744 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade/1564879945233076224 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade/1565158084484009984 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade/1565212566194491392
Drilling into that last run, the Available=False was the whole pool-update phase:

And details from the origin's monitor:
$ curl -s https://gcsweb-ci.apps.ci.l2s4.p1.openshiftapps.com/gcs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-e2e-aws-ovn-upgrade/1565212566194491392/artifacts/e2e-aws-ovn-upgrade/openshift-e2e-test/build-log.txt | grep clusteroperator/machine-config Sep 01 07:15:57.629 E clusteroperator/machine-config condition/Degraded status/True reason/RenderConfigFailed changed: Failed to resync 4.12.0-0.ci-2022-08-31-111359 because: refusing to read osImageURL version "4.12.0-0.ci-2022-09-01-053740", operator version "4.12.0-0.ci-2022-08-31-111359" Sep 01 07:15:57.629 - 49s E clusteroperator/machine-config condition/Degraded status/True reason/Failed to resync 4.12.0-0.ci-2022-08-31-111359 because: refusing to read osImageURL version "4.12.0-0.ci-2022-09-01-053740", operator version "4.12.0-0.ci-2022-08-31-111359" Sep 01 07:15:58.029 E clusteroperator/machine-config condition/Available status/False changed: Cluster not available for [{operator 4.12.0-0.ci-2022-08-31-111359}] Sep 01 07:15:58.029 - 1085s E clusteroperator/machine-config condition/Available status/False reason/Cluster not available for [{operator 4.12.0-0.ci-2022-08-31-111359}] Sep 01 07:16:47.000 I /machine-config reason/OperatorVersionChanged clusteroperator/machine-config-operator started a version change from [{operator 4.12.0-0.ci-2022-08-31-111359}] to [{operator 4.12.0-0.ci-2022-09-01-053740}] Sep 01 07:16:47.377 W clusteroperator/machine-config condition/Progressing status/True changed: Working towards 4.12.0-0.ci-2022-09-01-053740 Sep 01 07:16:47.377 - 1037s W clusteroperator/machine-config condition/Progressing status/True reason/Working towards 4.12.0-0.ci-2022-09-01-053740 Sep 01 07:16:47.405 W clusteroperator/machine-config condition/Degraded status/False changed: Sep 01 07:18:02.614 W clusteroperator/machine-config condition/Upgradeable status/False reason/PoolUpdating changed: One or more machine config pools are updating, please see `oc get mcp` for further details Sep 01 07:34:03.000 I /machine-config reason/OperatorVersionChanged clusteroperator/machine-config-operator version changed from [{operator 4.12.0-0.ci-2022-08-31-111359}] to [{operator 4.12.0-0.ci-2022-09-01-053740}] Sep 01 07:34:03.699 W clusteroperator/machine-config condition/Available status/True changed: Cluster has deployed [{operator 4.12.0-0.ci-2022-08-31-111359}] Sep 01 07:34:03.715 W clusteroperator/machine-config condition/Upgradeable status/True changed: Sep 01 07:34:04.065 I clusteroperator/machine-config versions: operator 4.12.0-0.ci-2022-08-31-111359 -> 4.12.0-0.ci-2022-09-01-053740 Sep 01 07:34:04.663 W clusteroperator/machine-config condition/Progressing status/False changed: Cluster version is 4.12.0-0.ci-2022-09-01-053740 [bz-Machine Config Operator] clusteroperator/machine-config should not change condition/Available [bz-Machine Config Operator] clusteroperator/machine-config should not change condition/Degraded
No idea if whatever was happening there is the same thing that was happening in other runs, and I haven't checked 4.11 and earlier either. The test-case is non-fatal, so it doesn't break CI, but it can cause noise like ClusterOperatorDown if it continues for 10 or more minutes. Whic PromeCIeus says actually fired in this run, although apparently the origin monitors didn't notice to complain:
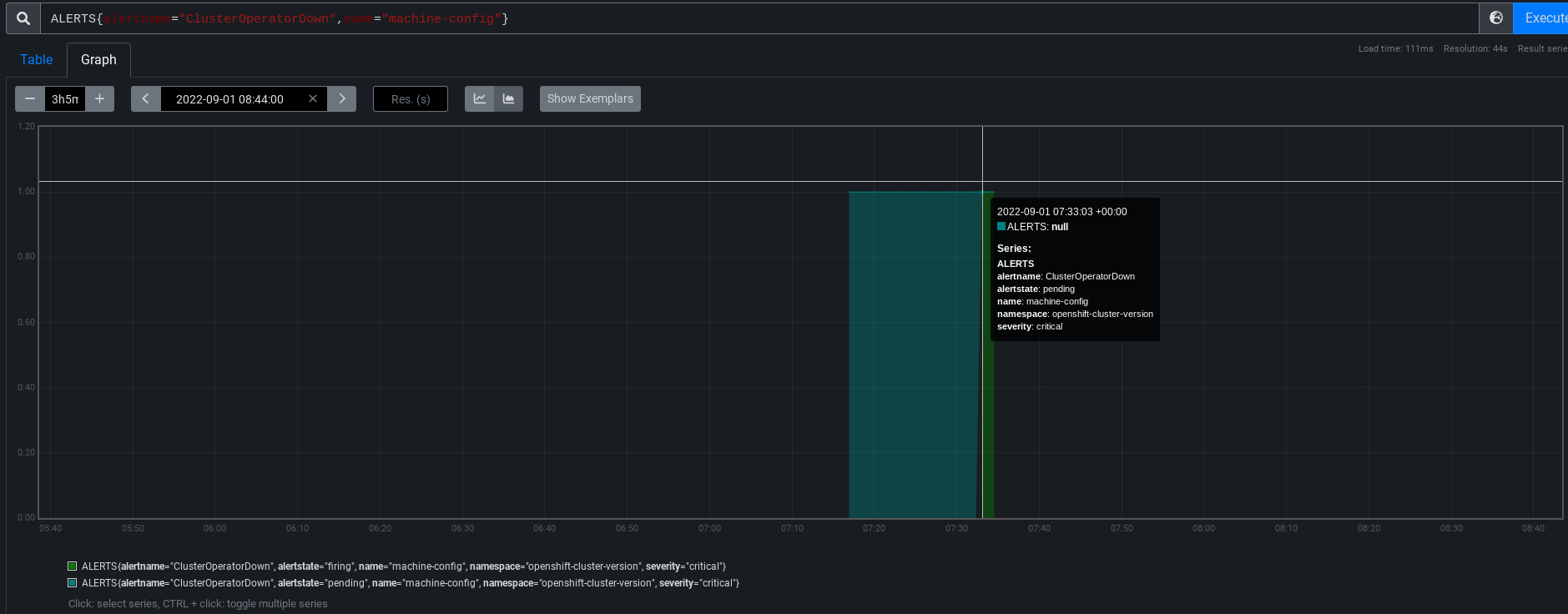
So parallel asks (and I'm happy to shard into separate bugs, if that's helpful):
- Set a reason when you go Available=False, so Telemetry can collect information to aggregate and hunt for frequent reasons to prioritize improvements.
- Figure out at least one reason why we're going Available=False in apparently healthy CI runs. If we find and fix one reason, we can circle back later to see if there are more that remain unfixed.

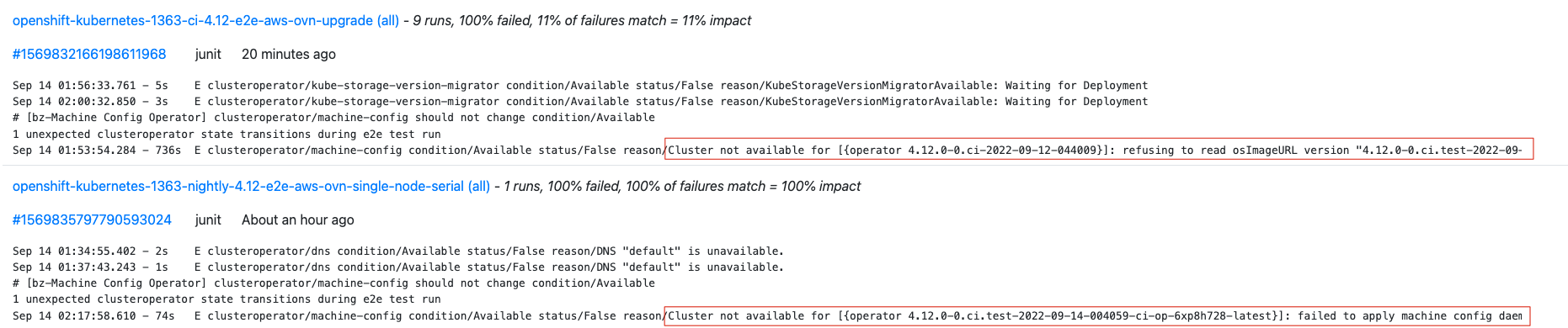

- relates to
-
OTA-362 CI: fail update suite if any ClusterOperator go Available=False
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- links to