-
Bug
-
Resolution: Done-Errata
-
 Normal
Normal
-
4.13, 4.12.z, 4.14
-
Quality / Stability / Reliability
-
False
-
-
3
-
Moderate
-
None
-
None
-
None
-
MCO Sprint 235, MCO Sprint 237, MCO Sprint 238
-
3
-
None
-
None
-
None
-
None
-
None
-
None
-
None
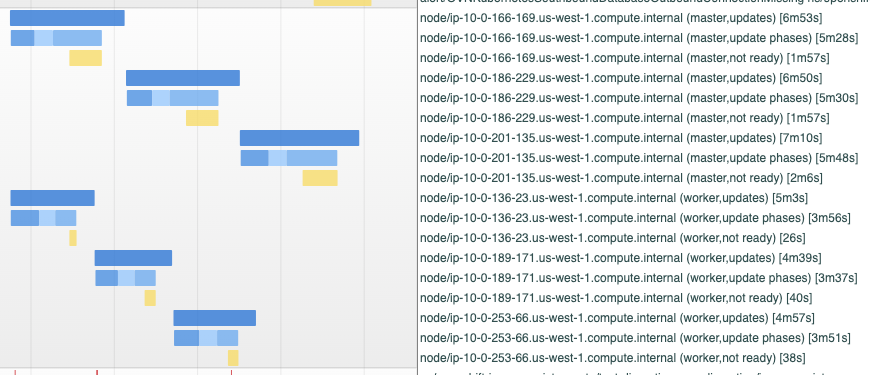
During upgrade tests, the MCO will become temporarily degraded with the following events showing up in the event log:
Dec 13 17:34:58.478 E clusteroperator/machine-config condition/Degraded status/True reason/RequiredPoolsFailed changed: Unable to apply 4.11.0-0.ci-2022-12-13-153933: error during syncRequiredMachineConfigPools: [timed out waiting for the condition, pool master has not progressed to latest configuration: controller version mismatch for rendered-master-3c738a0c86e7fdea3b5305265f2a2cdb expected 92012a837e2ed0ed3c9e61c715579ac82ad0a464 has 768f73110bc6d21c79a2585a1ee678d5d9902ad5: 2 (ready 2) out of 3 nodes are updating to latest configuration rendered-master-61c5ab699262647bf12ea16ea08f5782, retrying]
This seems to be occurring with some frequency as indicated by its prevalence in CI search:
$ curl -s 'https://search.ci.openshift.org/search?search=clusteroperator%2Fmachine-config+condition%2FDegraded+status%2FTrue+reason%2F.*controller+version+mismatch&maxAge=48h&context=1&type=bug%2Bissue%2Bjunit&name=%5E%28periodic%7Crelease%29.*4%5C.1%5B1%2C2%5D.*&excludeName=&maxMatches=1&maxBytes=20971520&groupBy=job' | jq 'keys | length' 399
The MCO should not become degraded during an upgrade unless it cannot proceed with the upgrade. In the case of these failures, I think we're timing out at some point during node reboots as either 1 or 2 of the control plane nodes are ready, with the third being unready. The MCO eventually requeues the syncRequiredMachineConfigPools step and the remaining nodes reboot and the MCO eventually clears the Degraded status.
Indeed, looking at the event breakdown, one can see that control plane nodes take ~21 minutes to roll out their new config with OS upgrades. By comparison, the worker nodes take ~15 minutes.
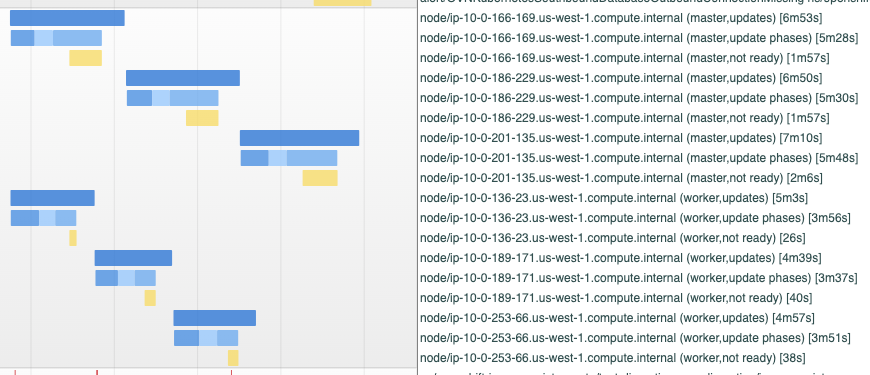
Meanwhile, the portion of the MCO which performs this sync (the syncRequiredMachineConfigPools function) has a hard-coded timeout of 10 minutes. Additionally, to my understanding, there is an additional 10 minute grace period before the MCO marks itself as degraded. Since the control plane nodes took ~21 minutes to completely reboot and roll out their new configs, we've exceeded the time needed. With this in mind, I propose a path forward:
- Figure out why control plane nodes are taking > 20 minutes for OS upgrades to be performed. My initial guess is that it has to do with etcd reestablishing quorum before proceeding onto the next control plane node whereas the worker nodes don't need to delay for that.
- If we conclude that OS upgrades just take longer to perform for control plane nodes, then maybe we could bump the timeout. Ideally, we could bump the timeout only for the control plane nodes, but that may take some refactoring to do.
- is related to
-
-
- Closed
-
-
-
- Closed
-
-
MCO-653 Investigate refactoring syncRequiredMachineConfigPools
-
- To Do
-
- links to
-
 RHEA-2023:5006
rpm
RHEA-2023:5006
rpm
