Description of problem:
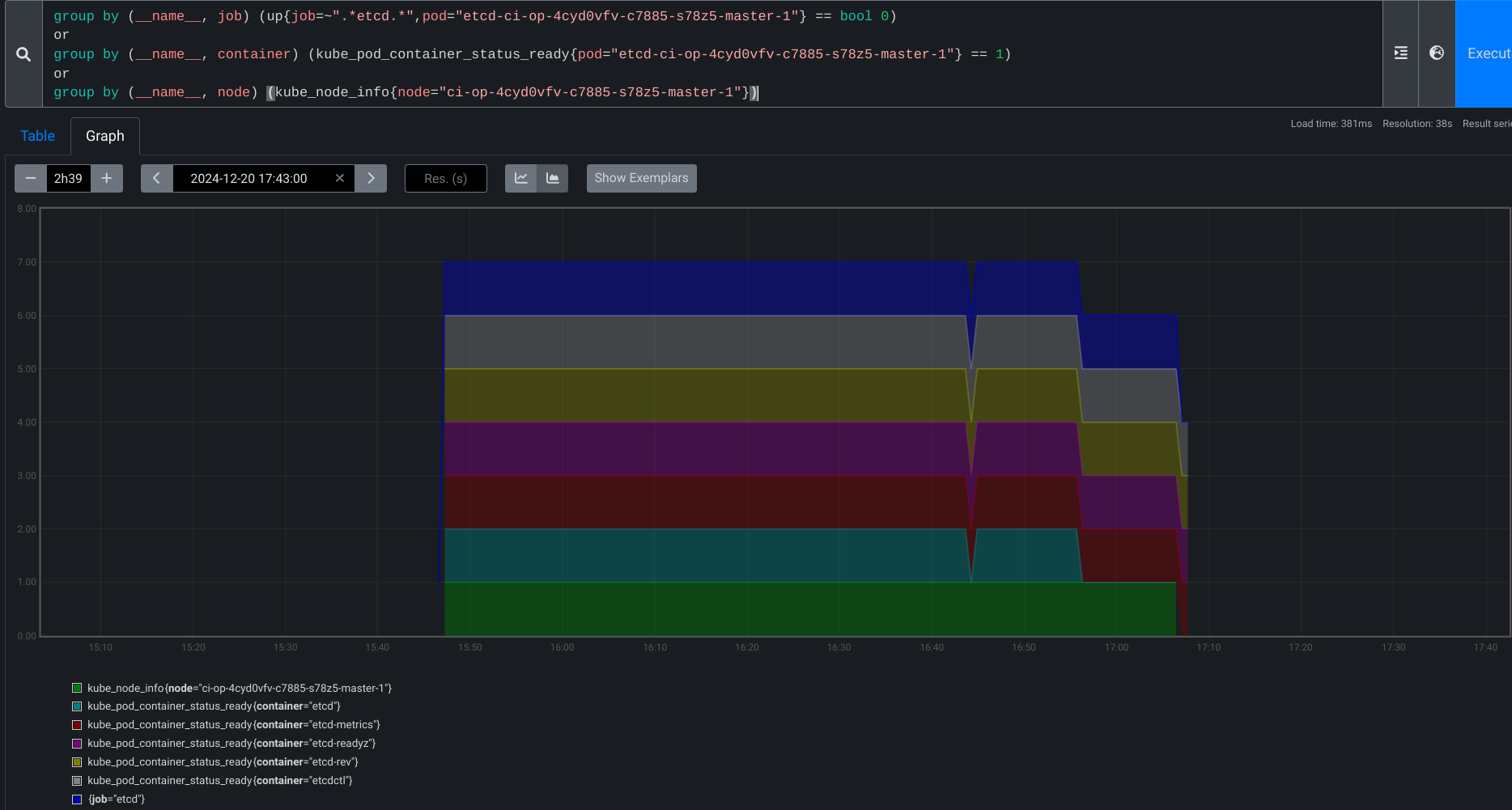
In a live 4.14.35 production cluster working through a control-plane replacement, where administrators deleted Machines, and the ControlPlaneMachineSet controller worked with the etcd operator to bring in replacement, etcdMembersDown fired for one of the outgoing instances. But that member's exit was expected, and the alarming alert firing during the healthy removal caused some concern, and manual checks to confirm that the removal was in fact proceeding without issue. We should adjust the alert to not fire in these smooth control-plane replacements, to avoid distracting future administrators.
Version-Release number of selected component
Seen in a 4.14.35 cluster, but also turns up in dev/4.19 CI:
$ w3m -dump -cols 200 'https://search.dptools.openshift.org/?search=etcdMembersDown.*firing+for+%5B%5E0%5D&maxAge=24h&type=junit' | grep 'failures match' pull-ci-openshift-cluster-control-plane-machine-set-operator-main-e2e-gcp-ovn-etcd-scaling (all) - 3 runs, 67% failed, 100% of failures match = 67% impact pull-ci-openshift-cluster-control-plane-machine-set-operator-main-e2e-vsphere-ovn-etcd-scaling (all) - 3 runs, 67% failed, 50% of failures match = 33% impact periodic-ci-openshift-release-master-nightly-4.17-e2e-aws-ovn-etcd-scaling (all) - 1 runs, 100% failed, 100% of failures match = 100% impact
How reproducible
According to my CI Search results, something like half of all etcd-scaling CI reproduce this alert issue.
Steps to Reproduce
1. Run some etcd-scaling CI.
2. Check the alert/etcdMembersDown should not be at or above info test-case.
Actual results
Sometimes the test-case passes, but about half the time it fails because the alert fires. For example, in this run:
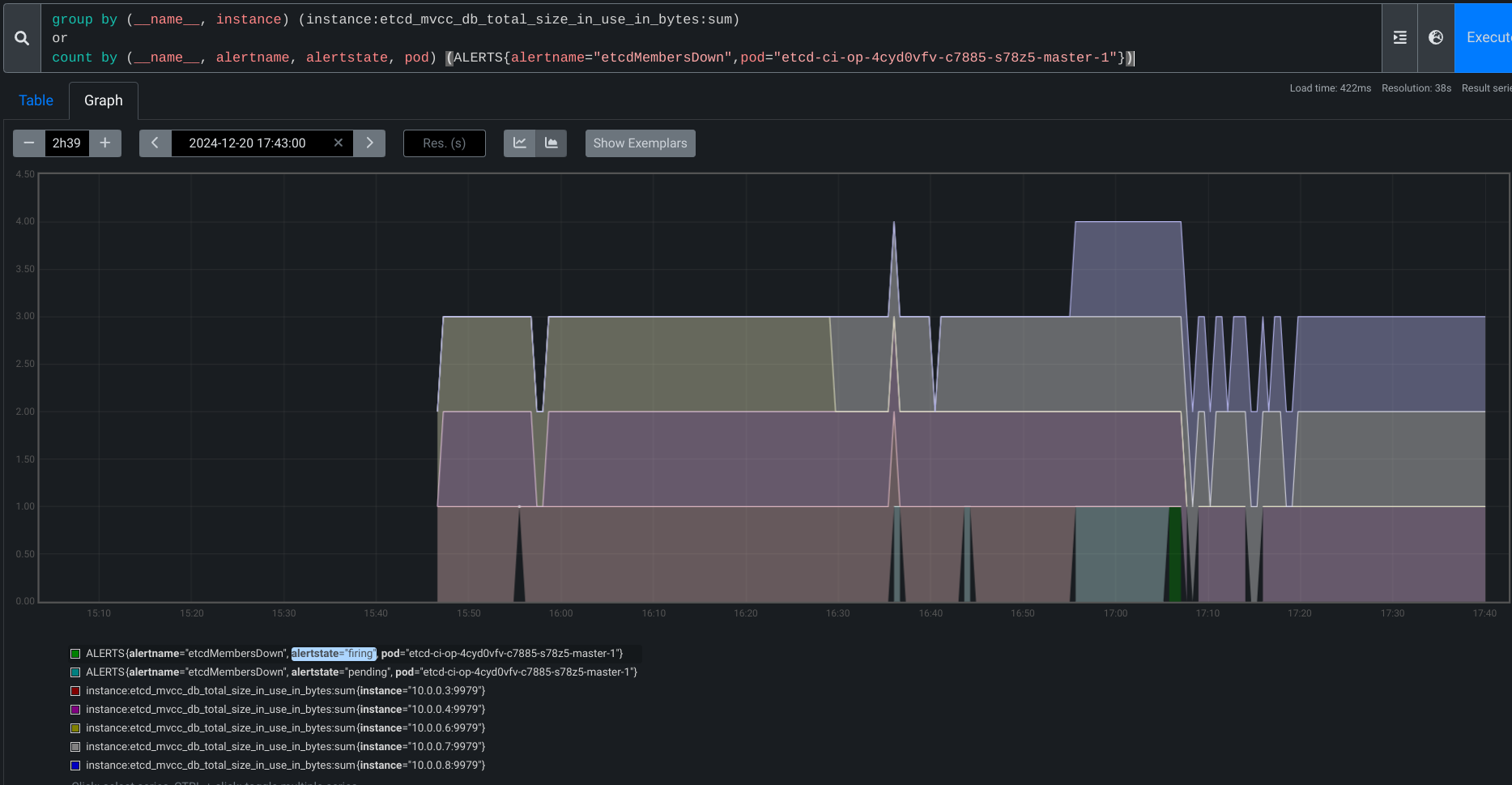
: [bz-etcd][invariant] alert/etcdMembersDown should not be at or above info expand_less 0s
{ etcdMembersDown was at or above info for at least 1m58s on platformidentification.JobType{Release:"4.19", FromRelease:"", Platform:"gcp", Architecture:"amd64", Network:"ovn", Topology:"ha"} (maxAllowed=0s): pending for 14m34s, firing for 1m58s:
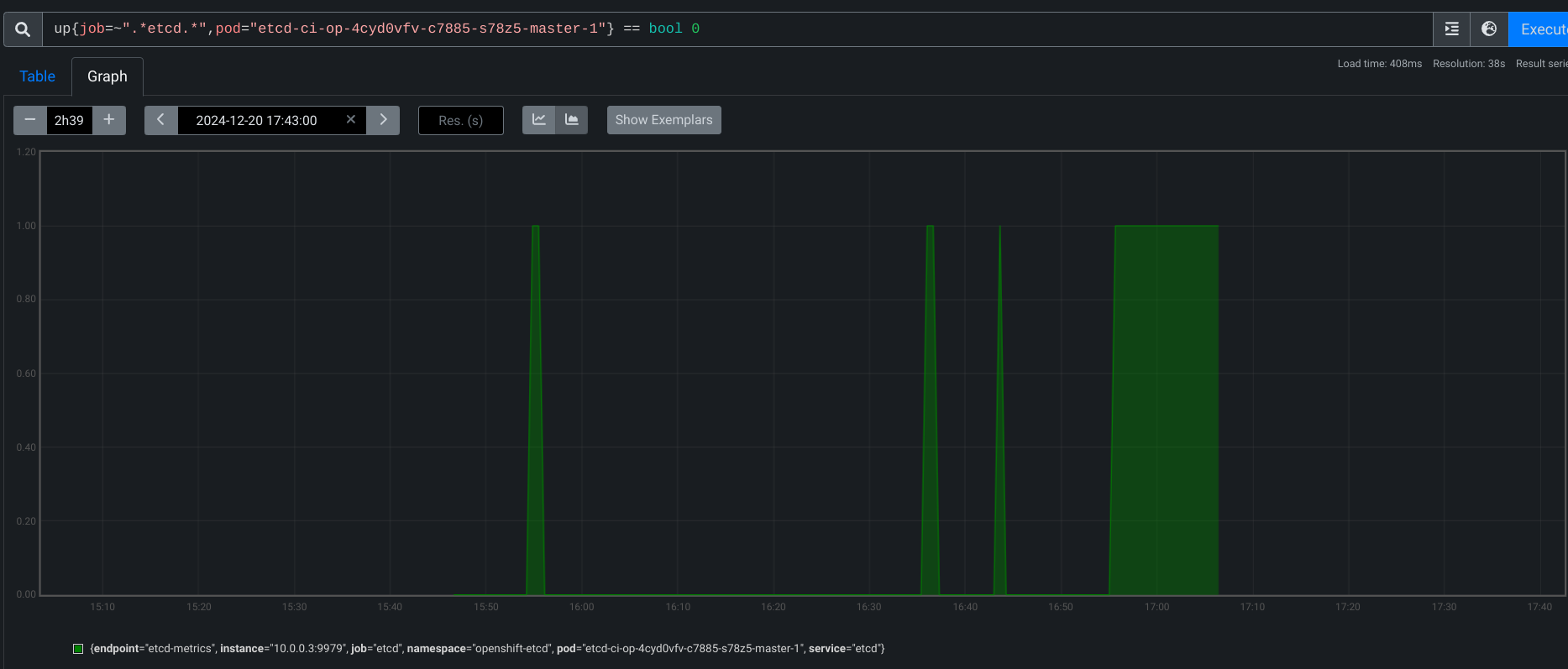
Dec 20 17:05:27.811 - 118s E namespace/openshift-etcd pod/etcd-ci-op-4cyd0vfv-c7885-s78z5-master-1 alert/etcdMembersDown alertstate/firing severity/critical ALERTS{alertname="etcdMembersDown", alertstate="firing", job="etcd", namespace="openshift-etcd", pod="etcd-ci-op-4cyd0vfv-c7885-s78z5-master-1", prometheus="openshift-monitoring/k8s", service="etcd", severity="critical"}}
Expected results
Test-case passes reliably, because the alert doesn't fire.
- is duplicated by
-
OCPBUGS-58386 etcdMembersDown firing when CPMS is replacing machines
-

- New
-

{kind=link}
{kind=link}
{kind=link}