-
Bug
-
Resolution: Duplicate
-
 Undefined
Undefined
-
None
-
4.18
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
Yes
-
None
-
None
-
None
-
MON Sprint 263
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
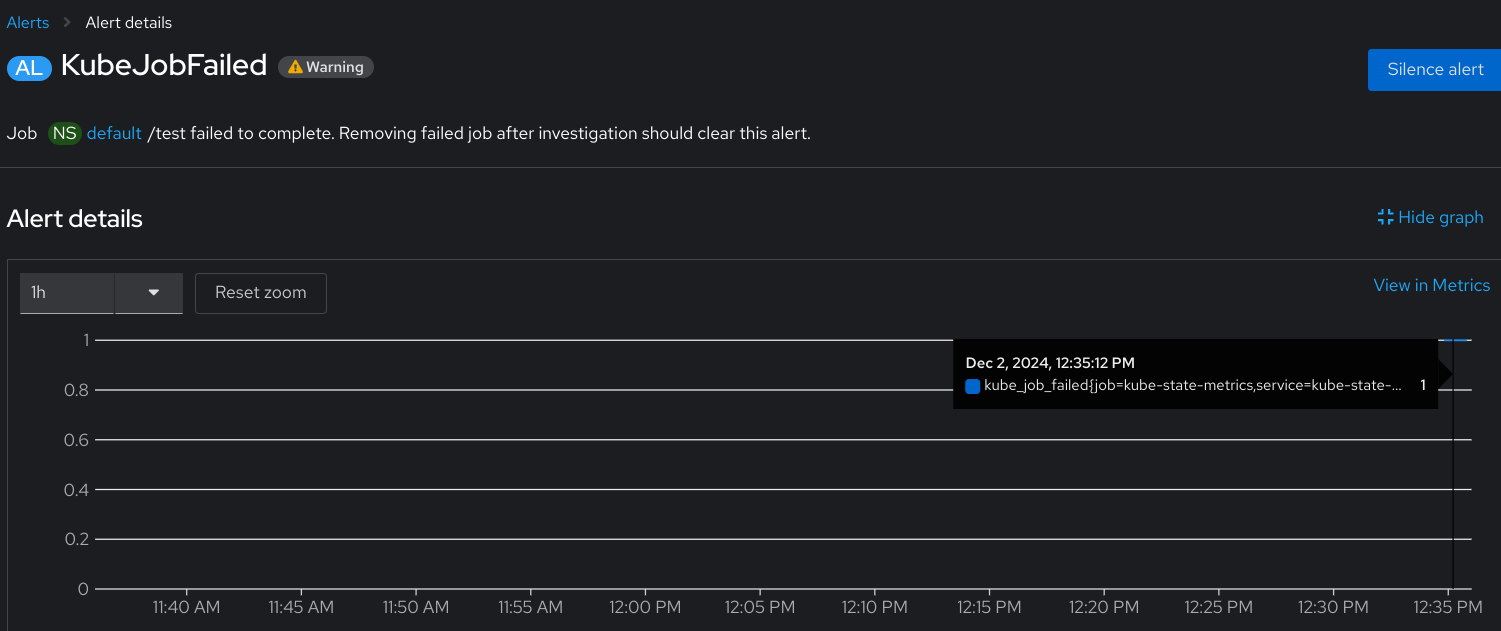
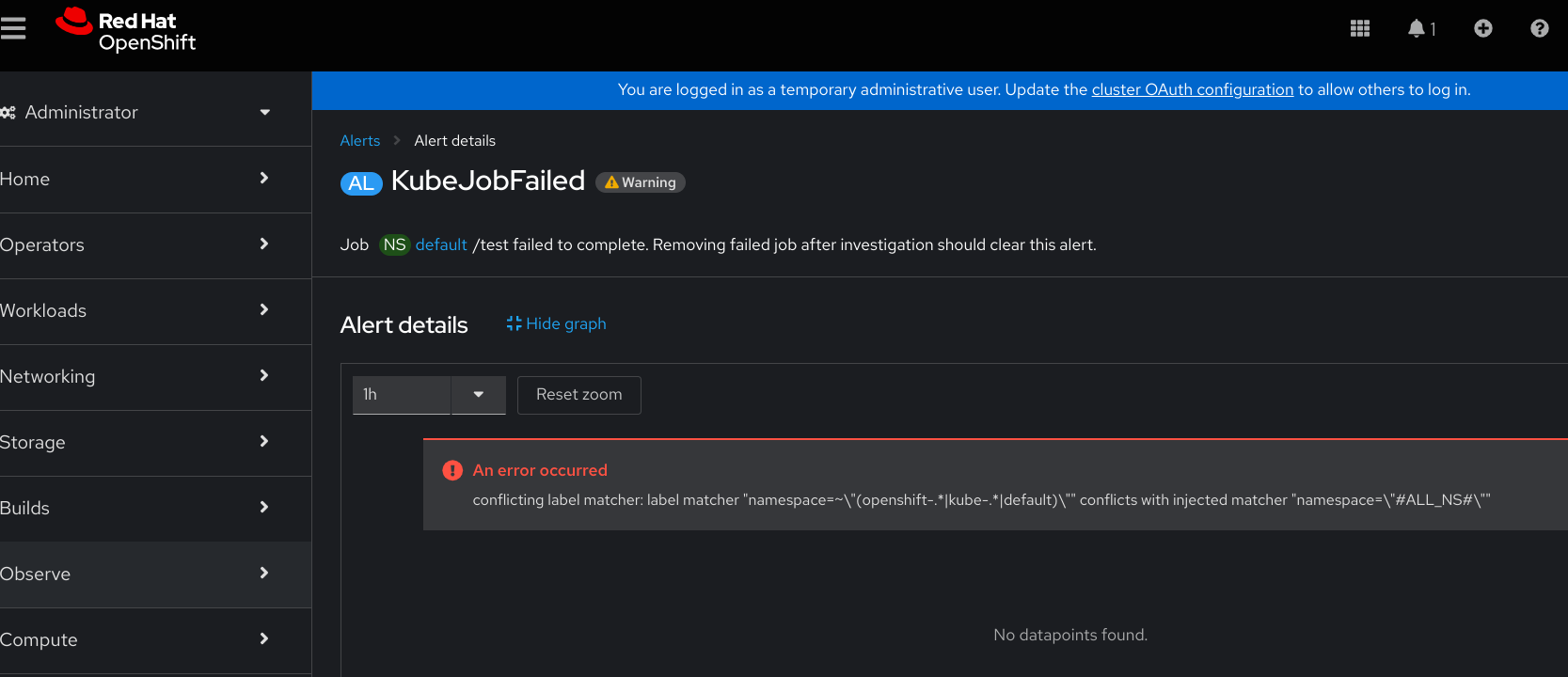
Description of problem
In 4.18, the KubeJobFailed alert page fails to display metric results, and instead displays an error from /api/prometheus-tenancy/api/v1/query_range?start=1733162830.27&end=1733166430.269&step=12&namespace=%23ALL_NS%23&query=kube_job_failed%7Bjob%3D%22kube-state-metrics%22%2Cnamespace%3D%7E%22%28openshift-.*%7Ckube-.*%7Cdefault%29%22%7D+%3E+0&timeout=60s:
An error occurred conflicting label matcher: label matcher "namespace=~\"(openshift-.*|kube-.*|default)\"" conflicts with injected matcher "namespace=\"#ALL_NS#\""
Version-Release number of selected component
I've seen the bug in 4.18.0-ec.4.
I have tested 4.17.7, and that worked, without reproducing this bug.
How reproducible
Every time.
Steps to Reproduce
- launch a ClusterBot cluster with launch 4.18.0-ec.4 gcp.
- create a broken Job (e.g. via attached YAML).
- find the pending alert page in the in-cluster web console
Actual results
The Description's conflicting label matcher message.
Expected results
Successfully evaluated metrics.
- is duplicated by
-
-

- Closed
-
