-
Bug
-
Resolution: Can't Do
-
 Undefined
Undefined
-
None
-
4.14.0
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
No
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
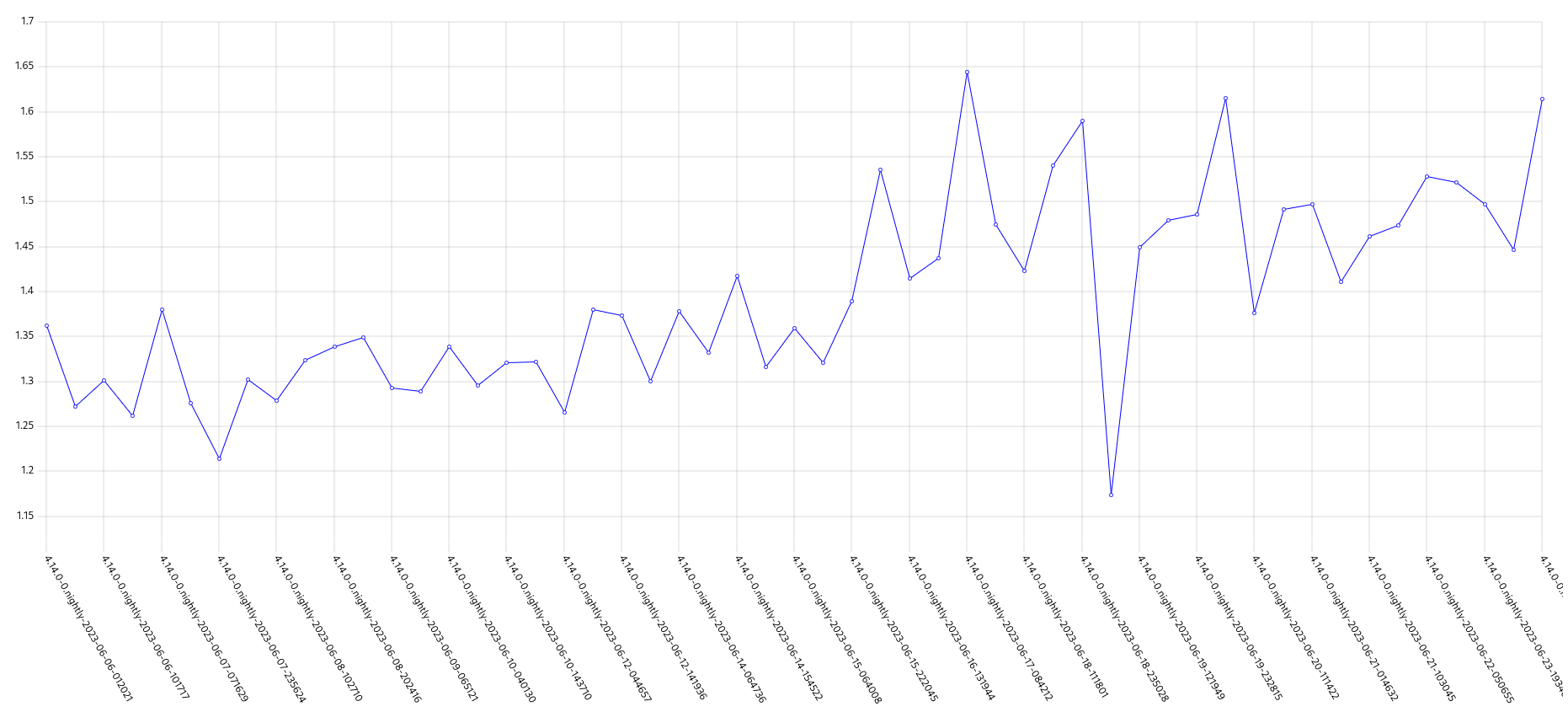
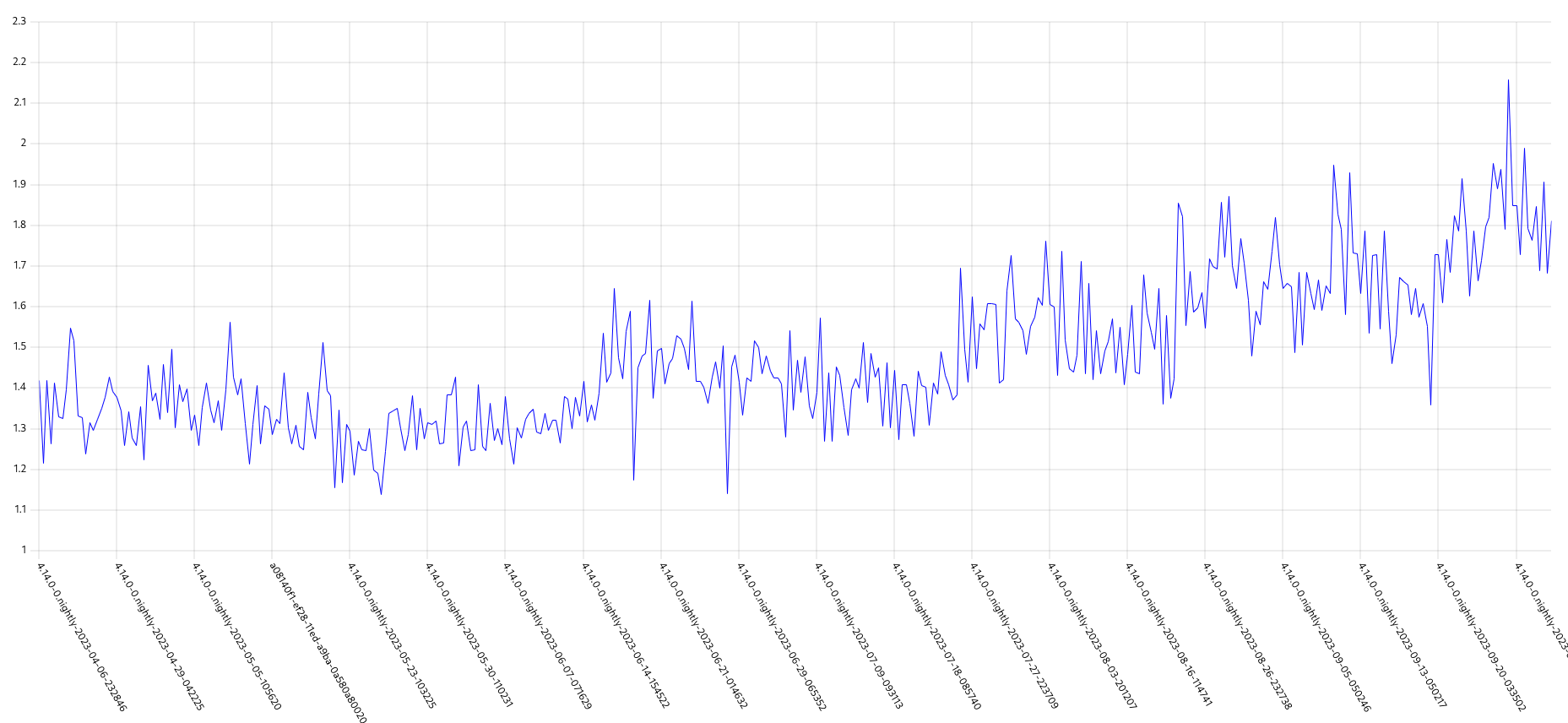
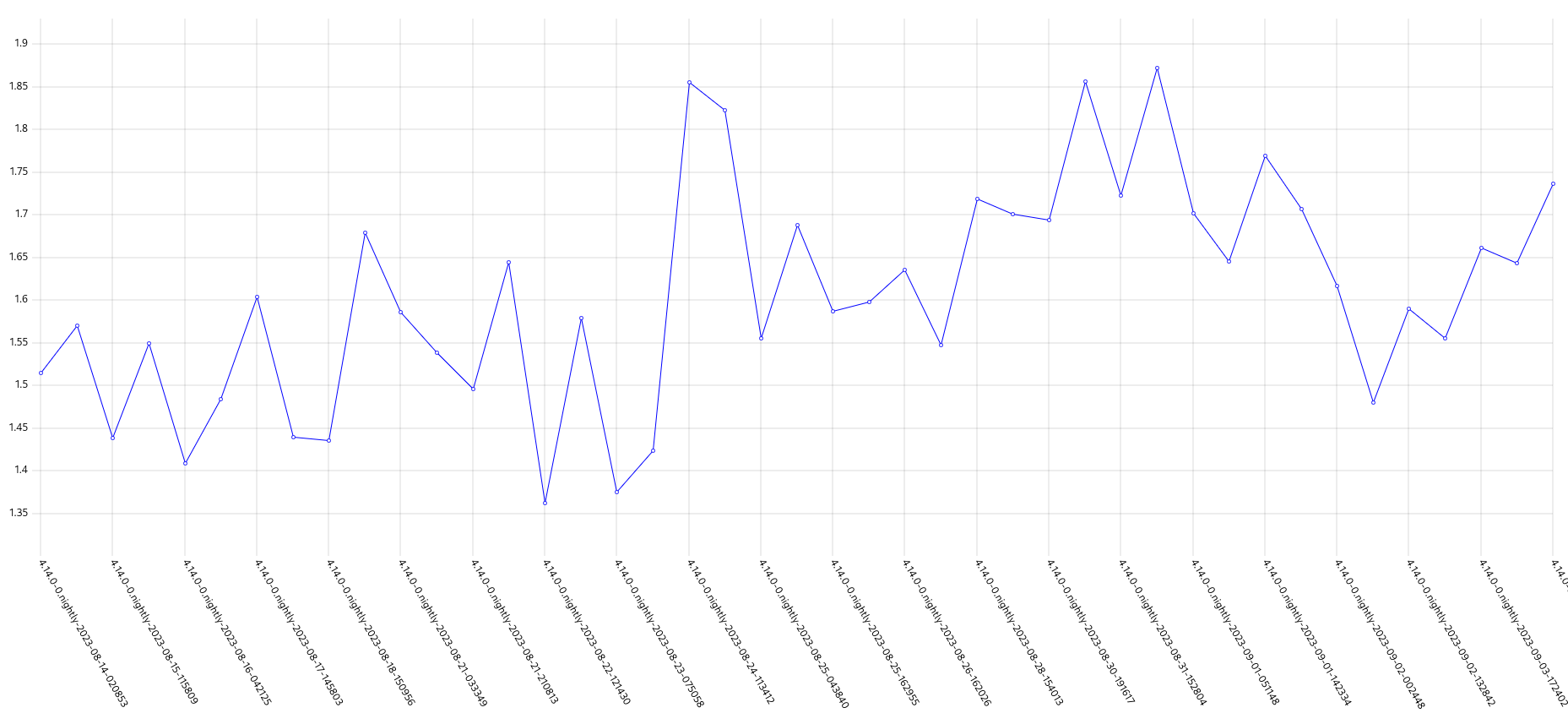
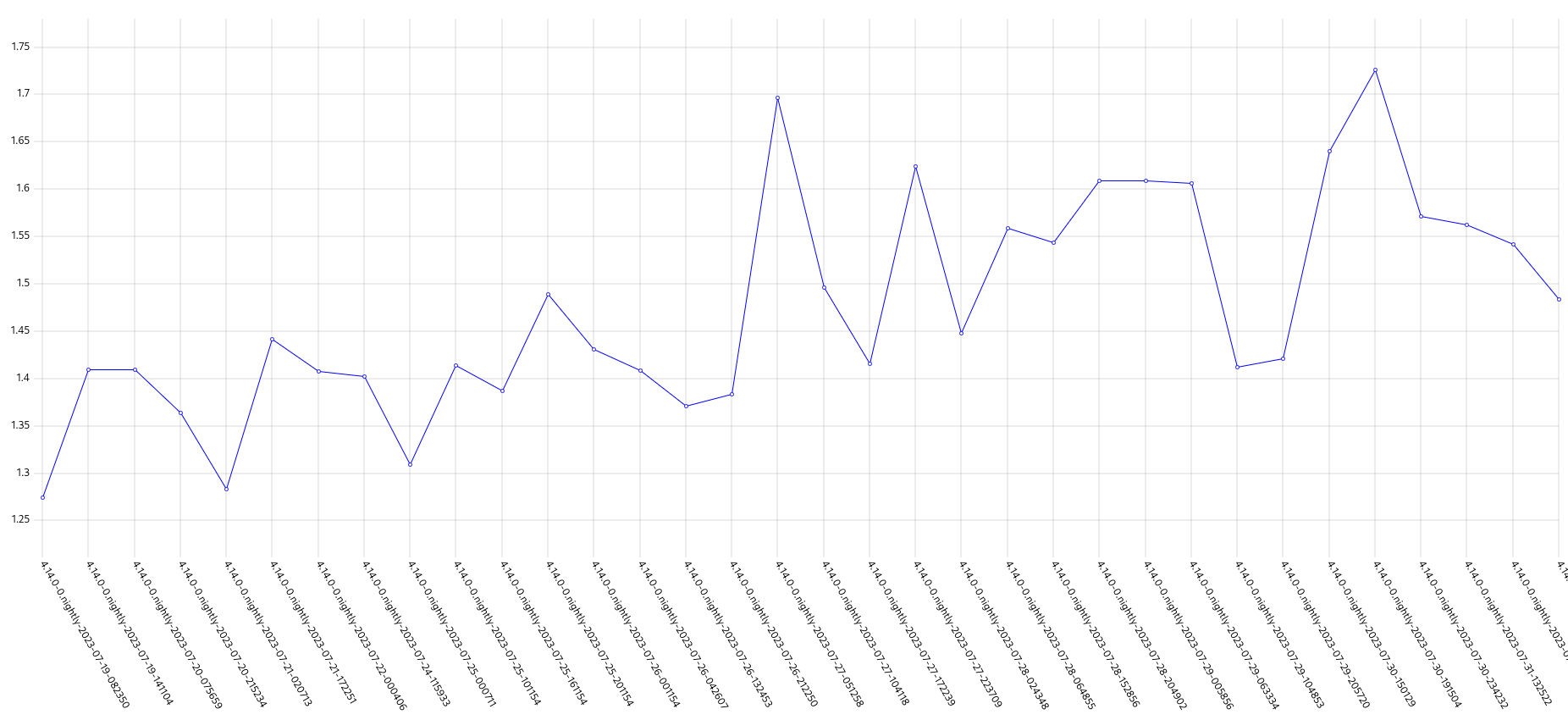
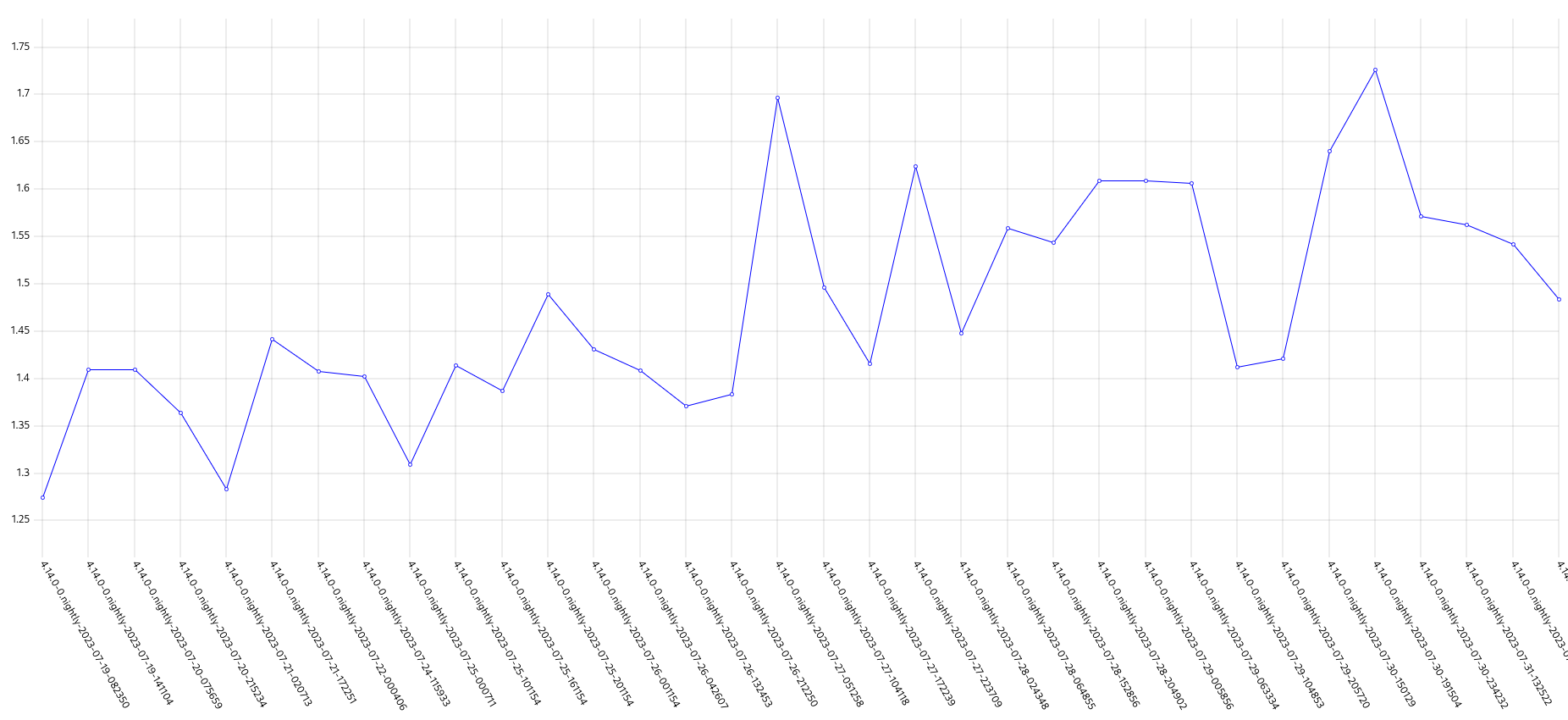
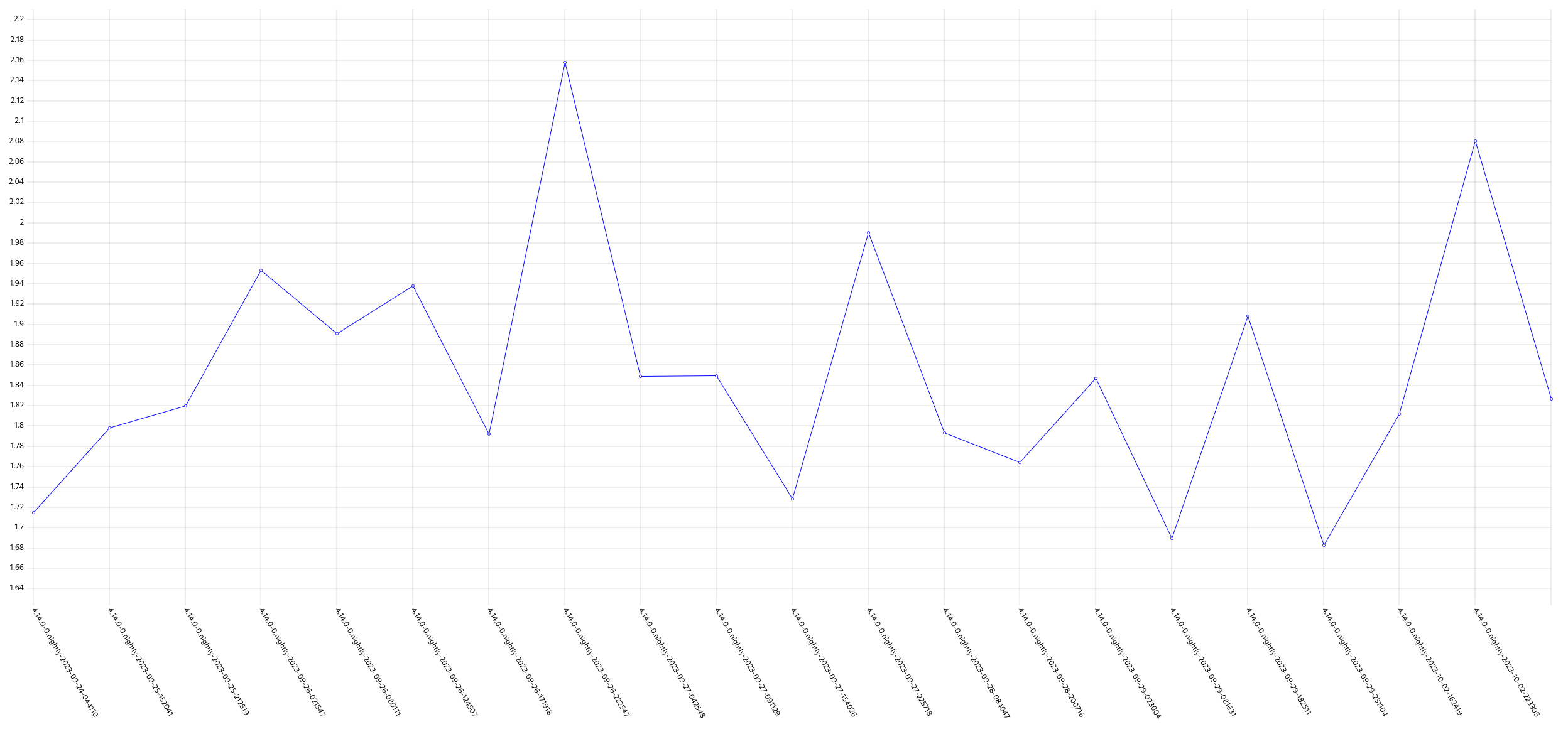
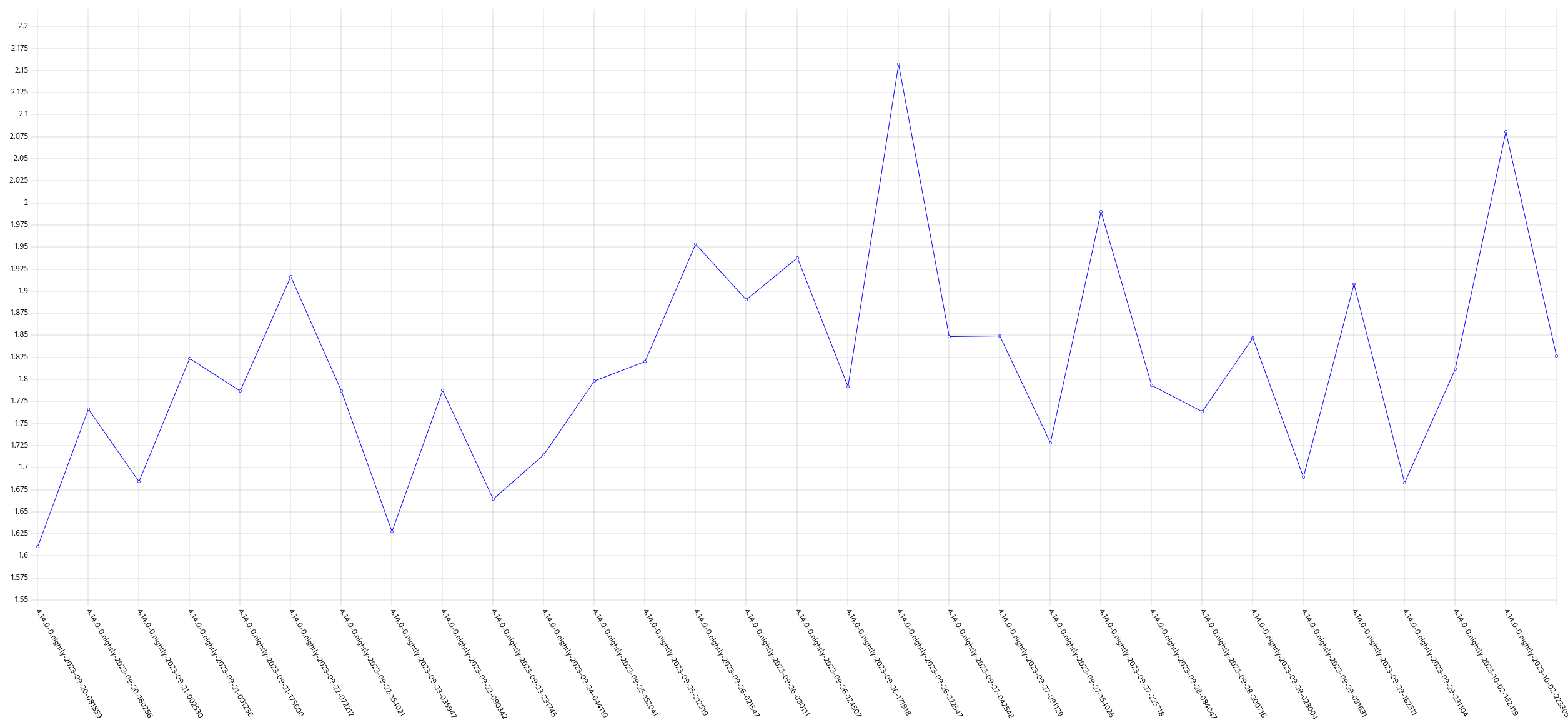
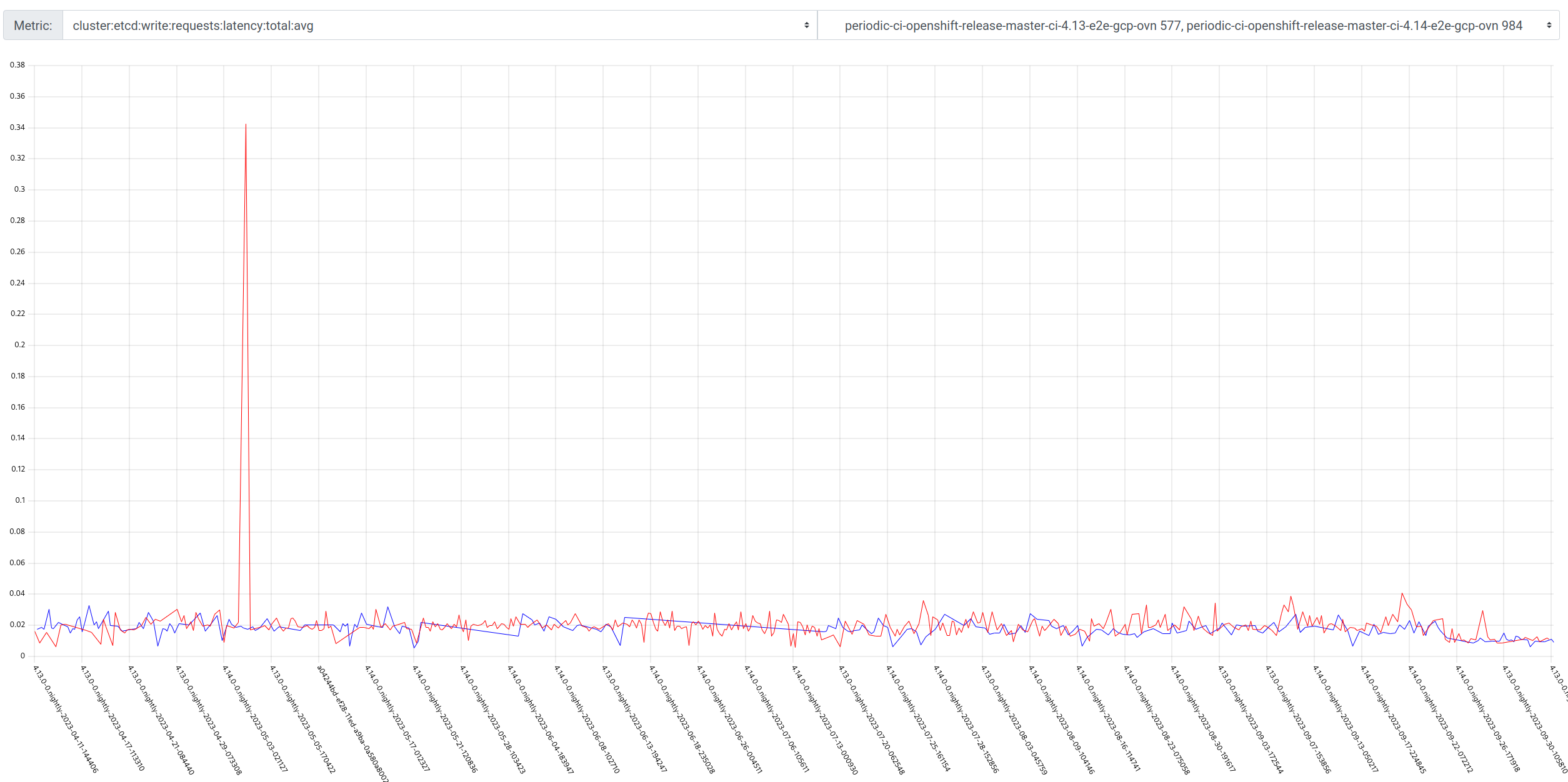
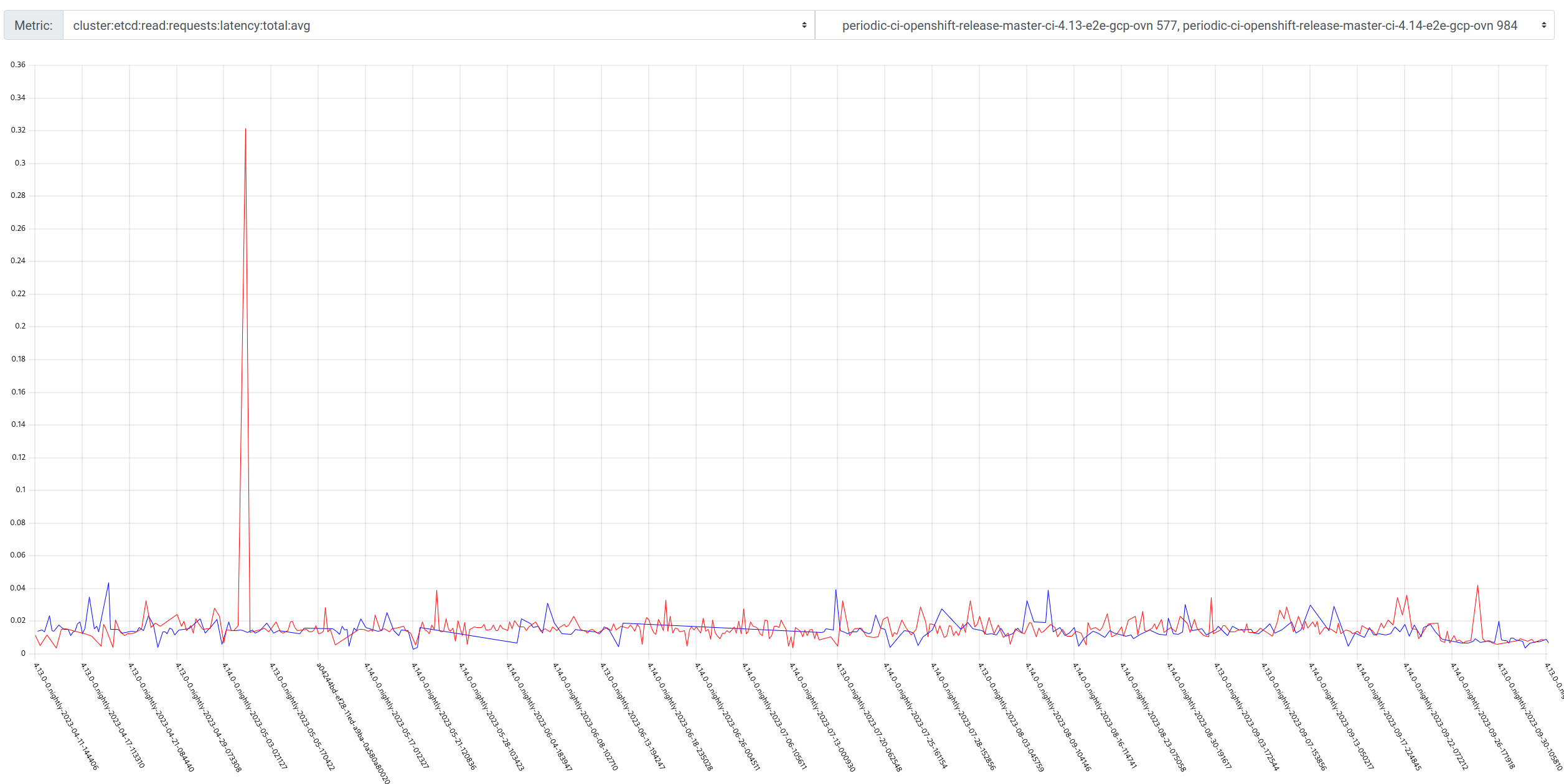
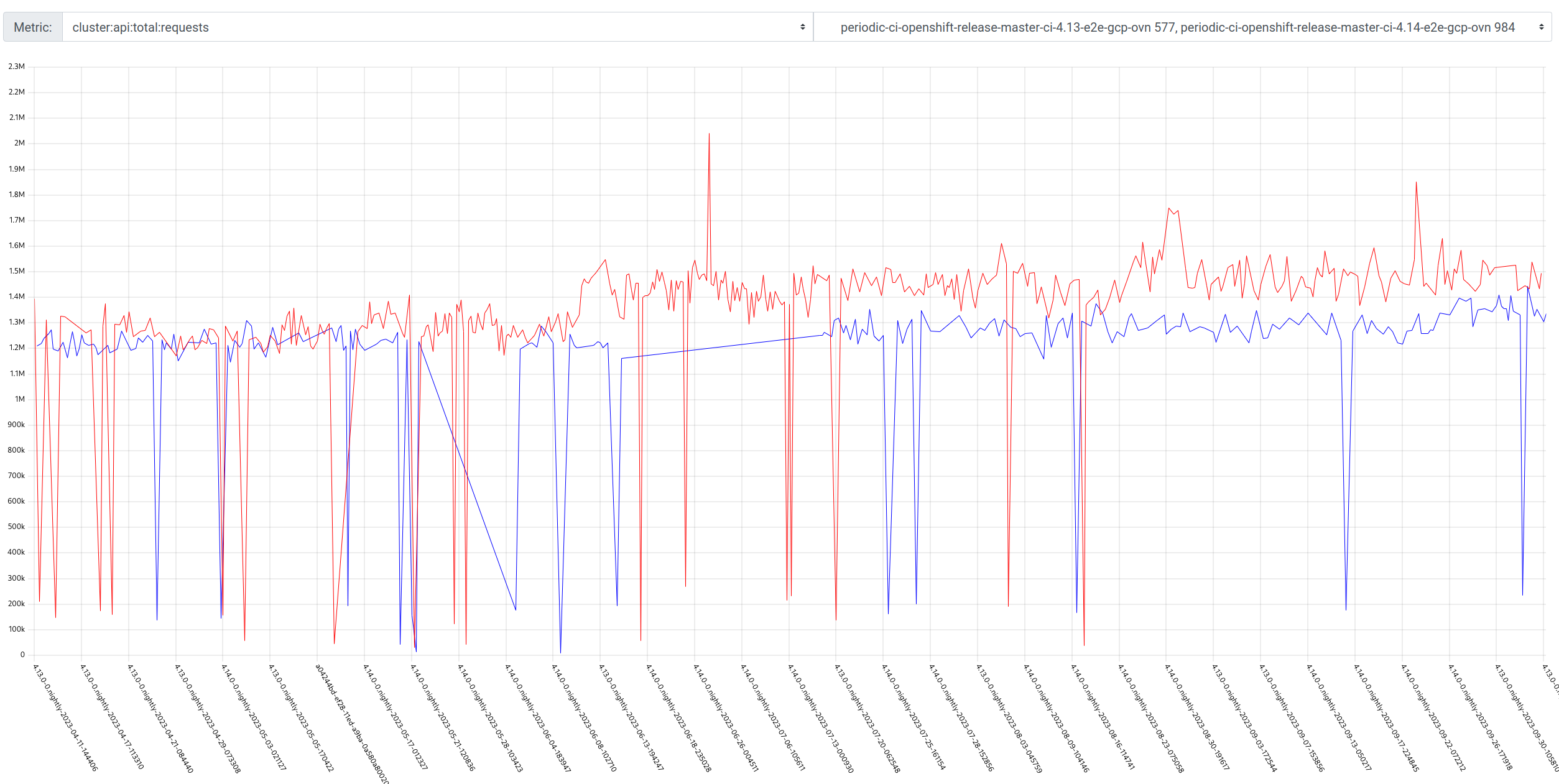
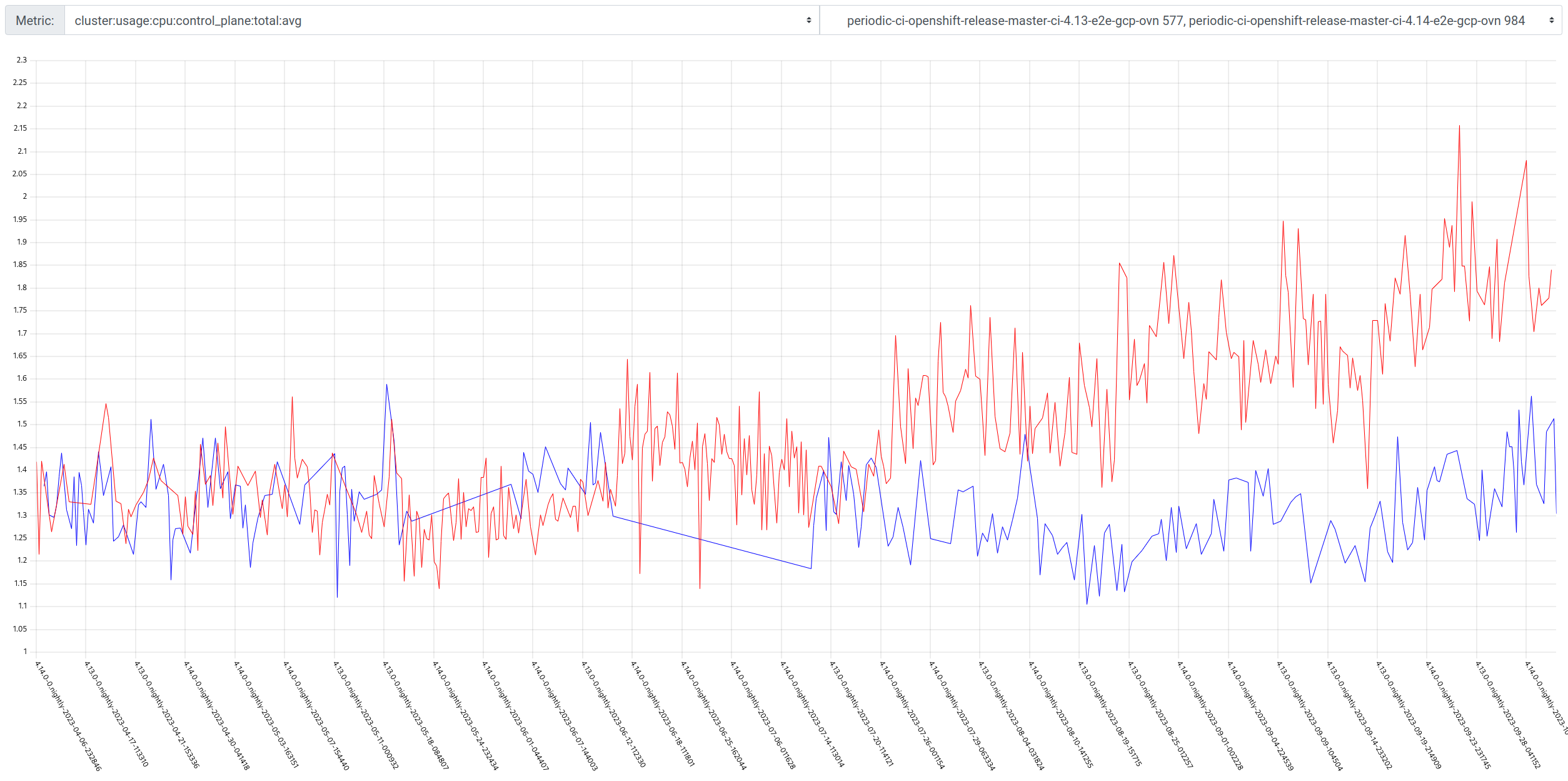
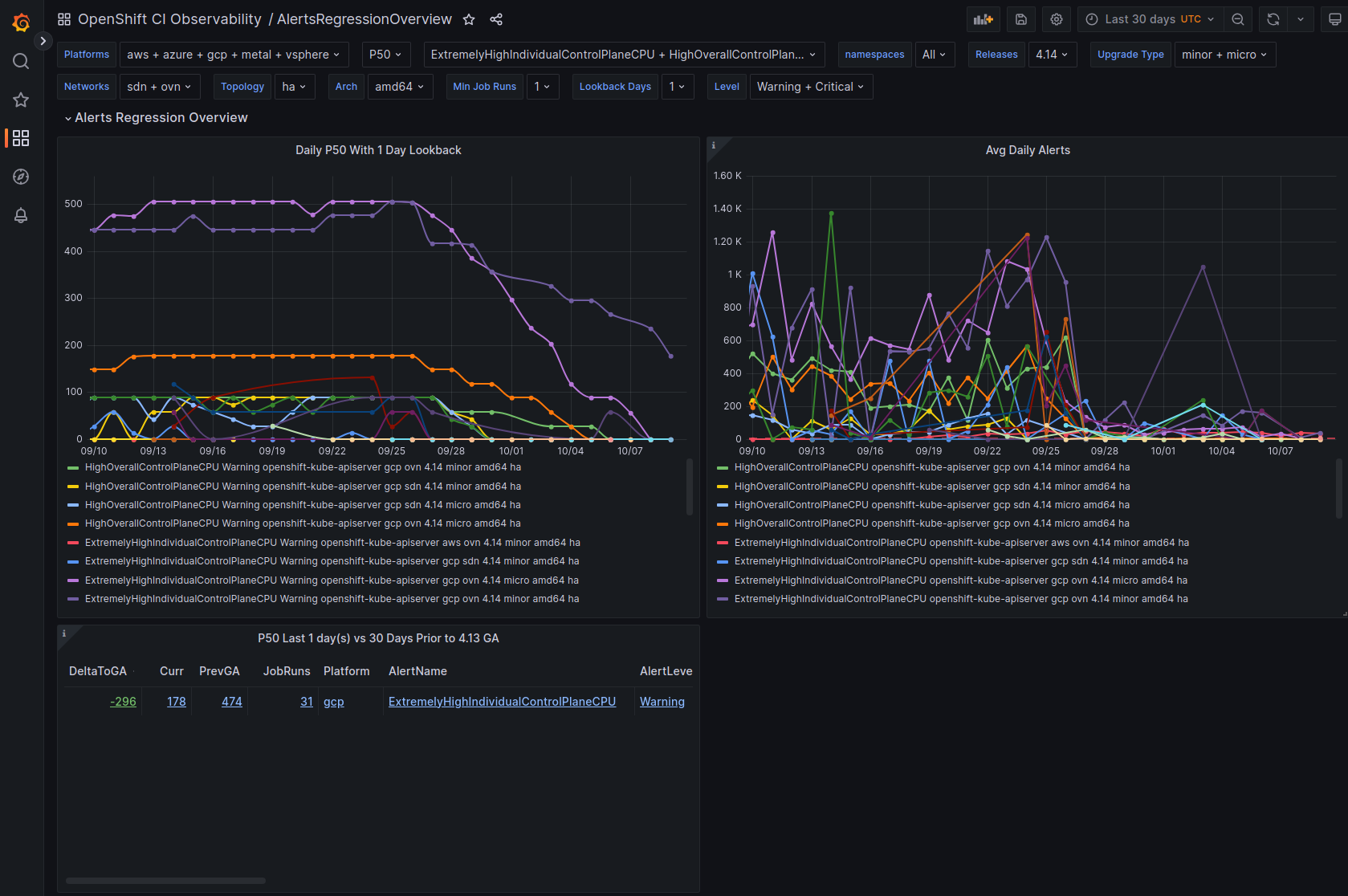
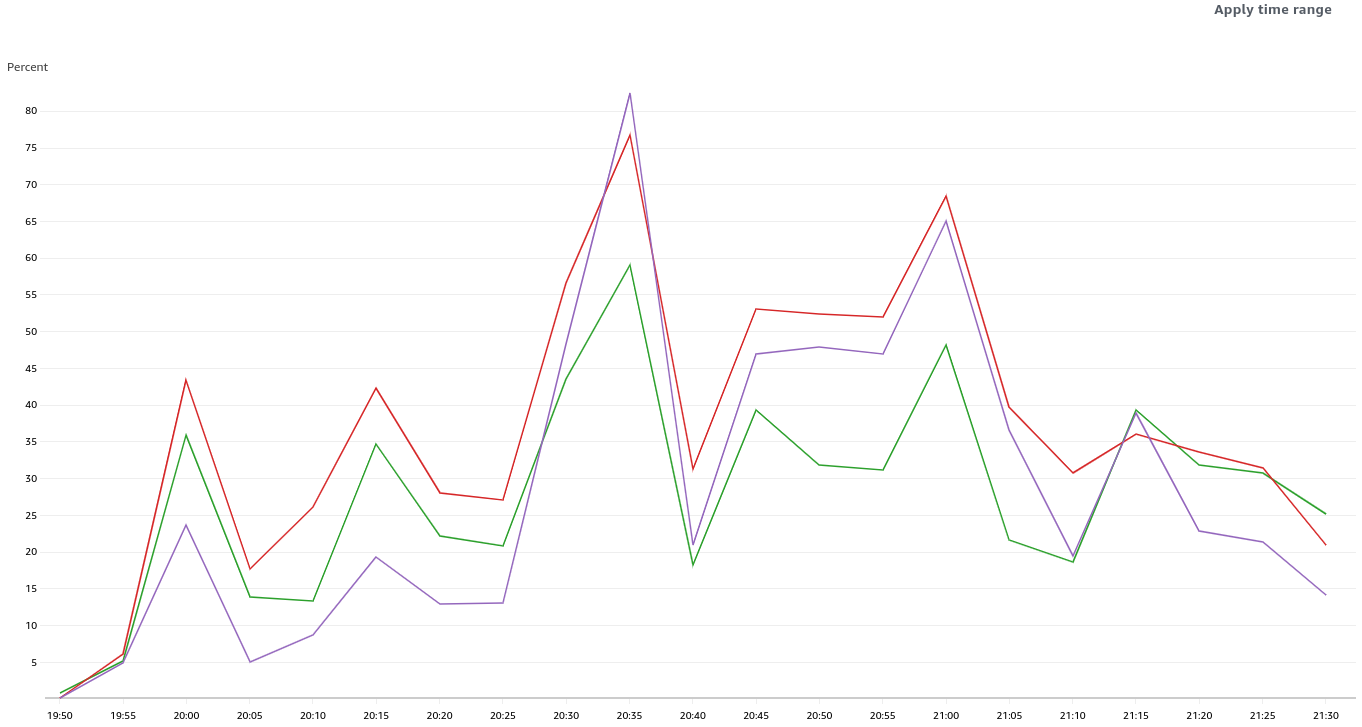
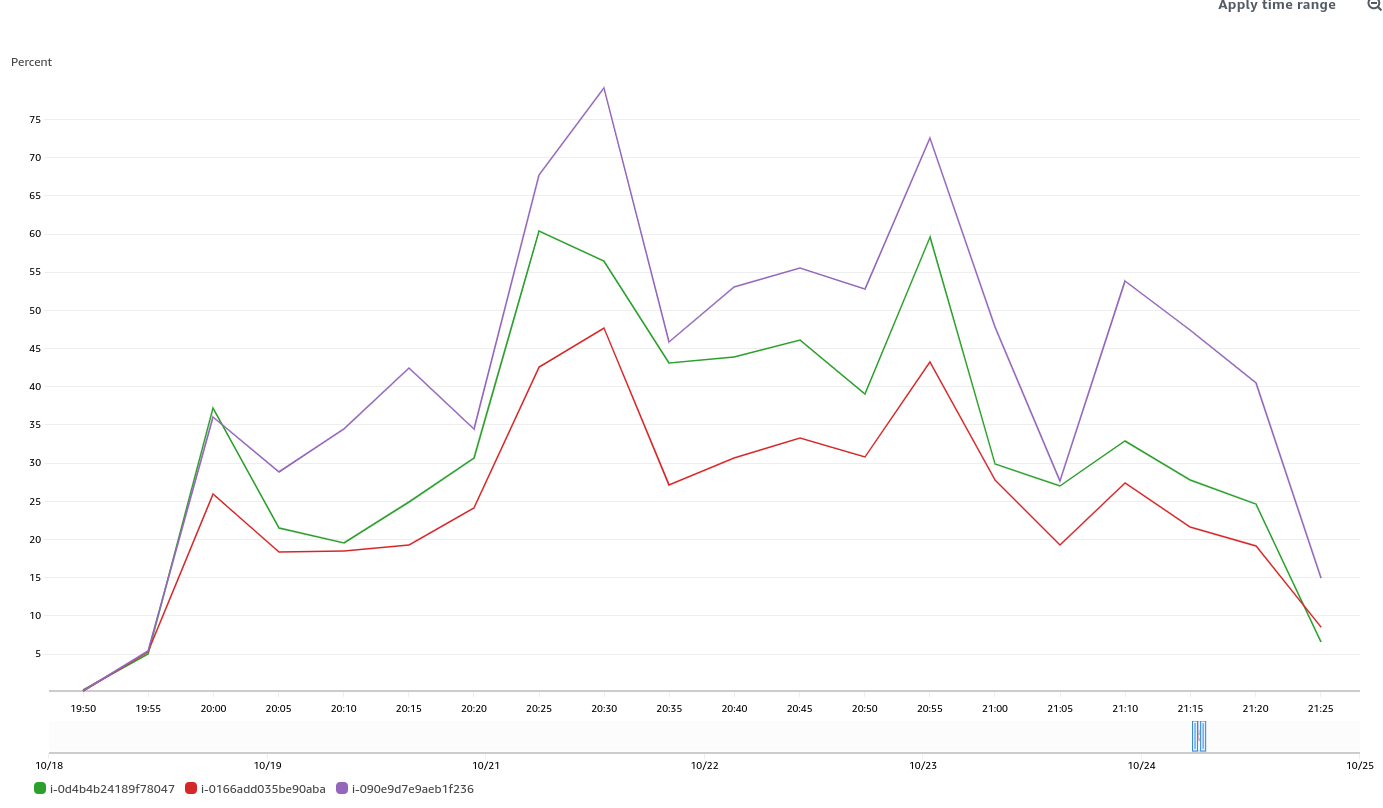
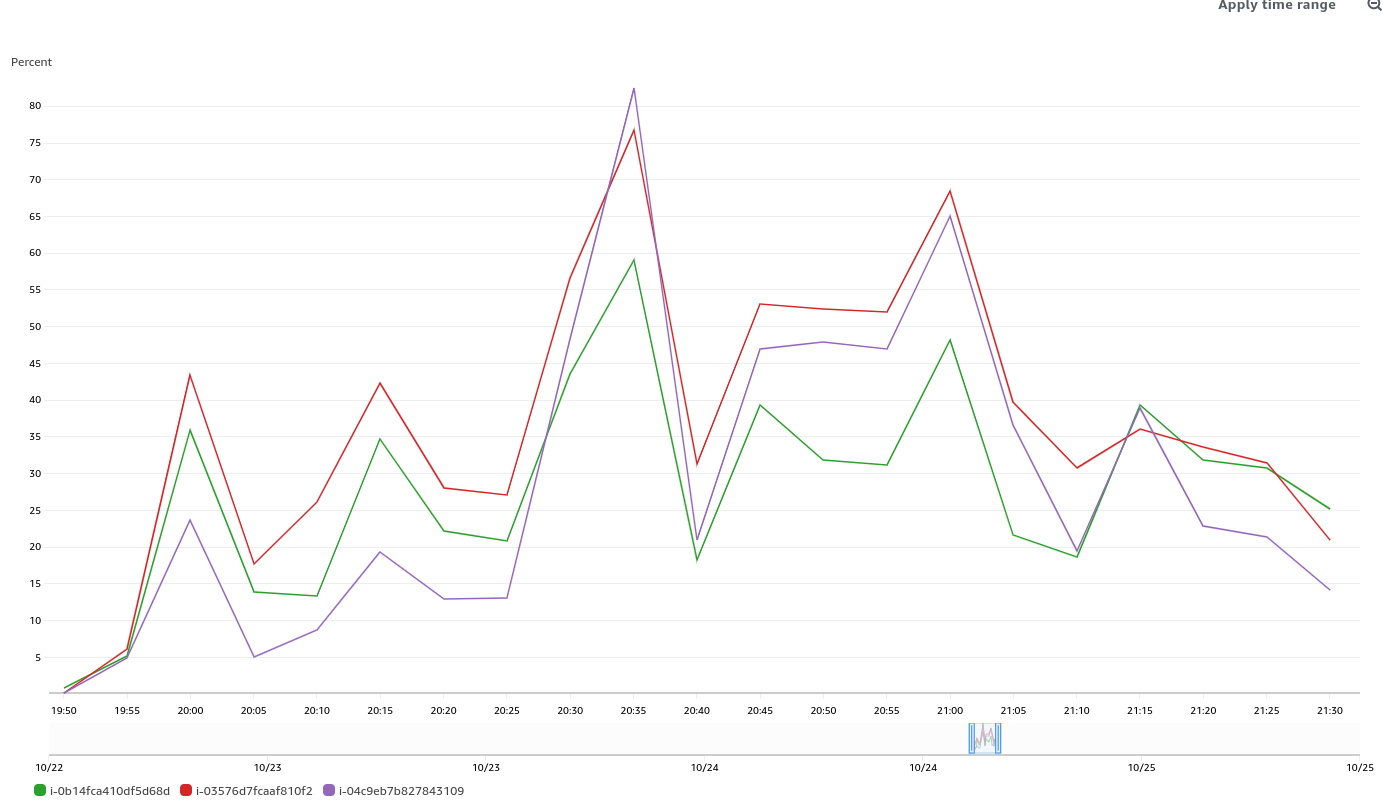
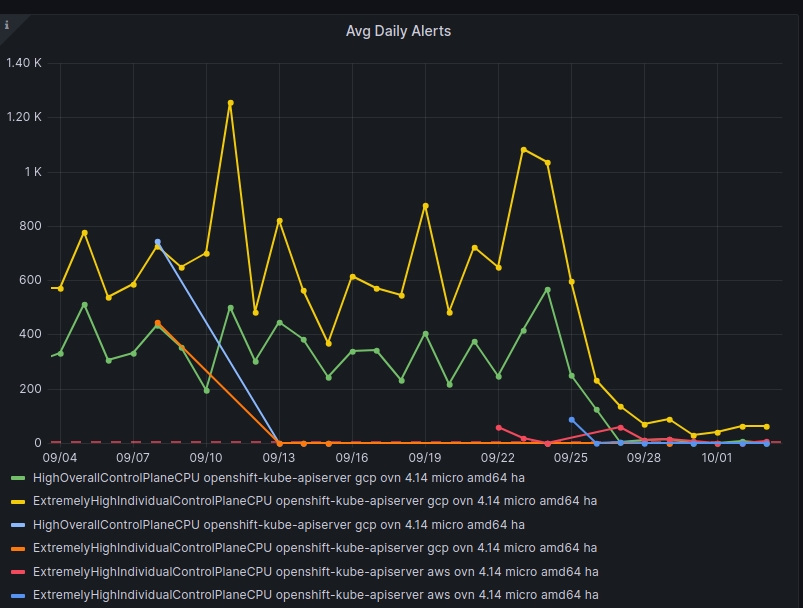
GCP is the only platform that consistently fires HighOverallControlPlaneCPU and ExtremelyHighIndividualControlPlaneCPU alerts during it's CI runs.
The problem appears mainly on gcp ovn micro because this is what we have the most data for, but it appears sdn runs have similar problems but less alert firing time, and minor upgrades also.
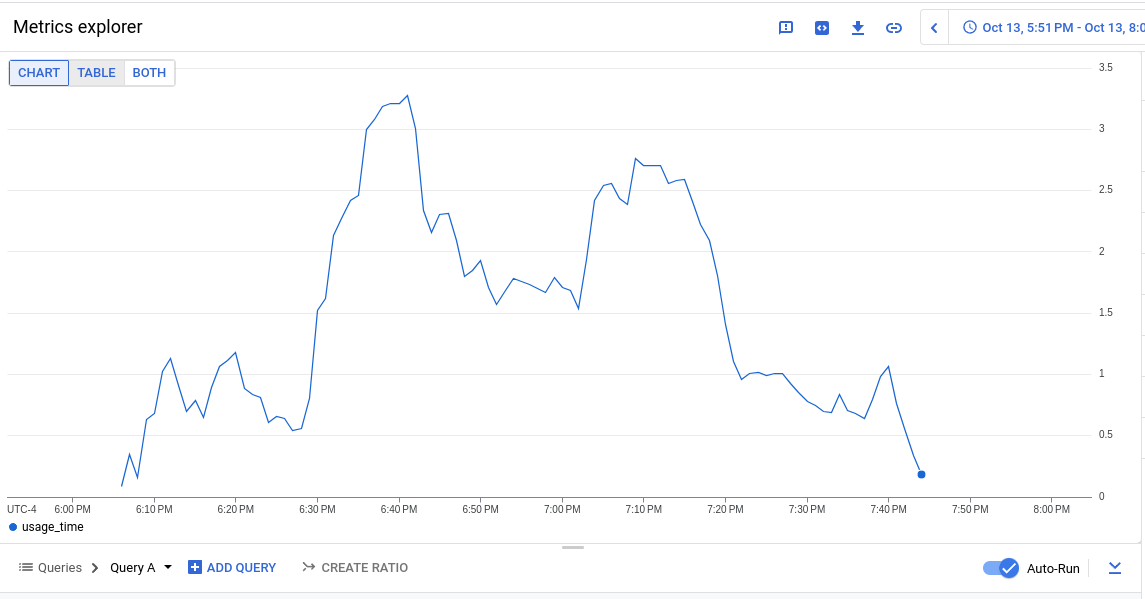
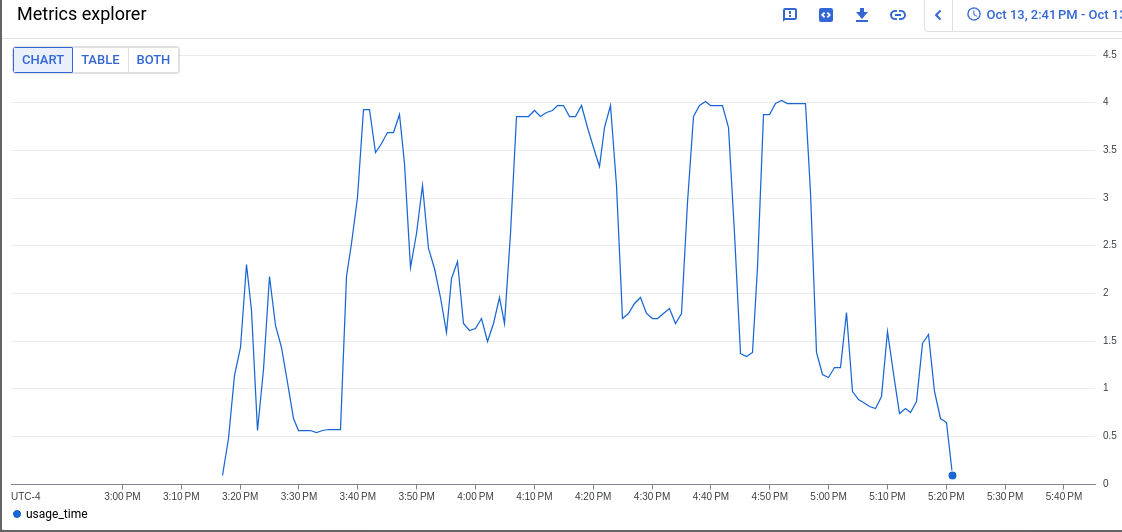
Focusing on ovn micro upgrades, the P50 for all CI clusters is around 3m of HighOverall, and 8m of ExtremelyHighIndividual.
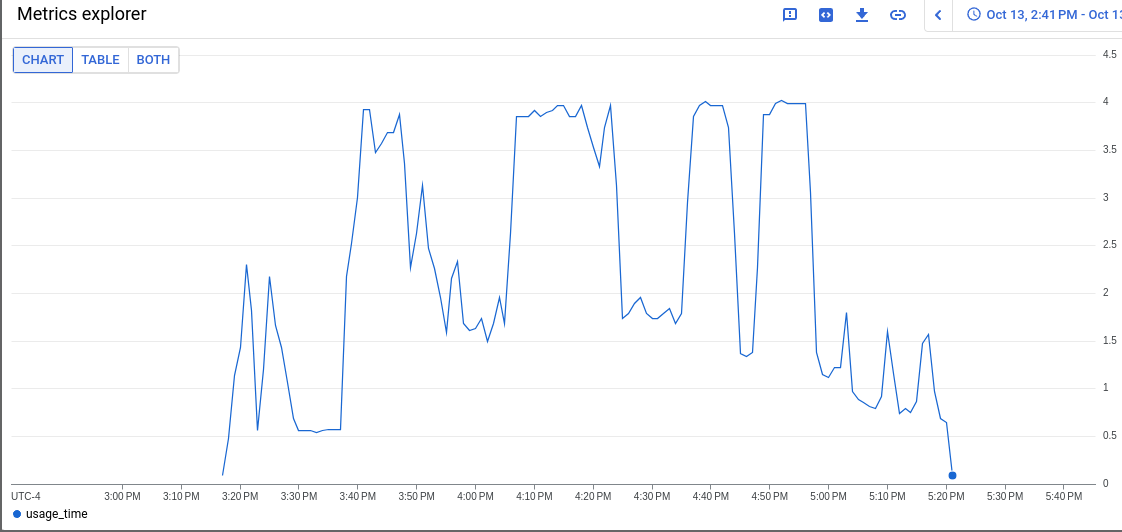
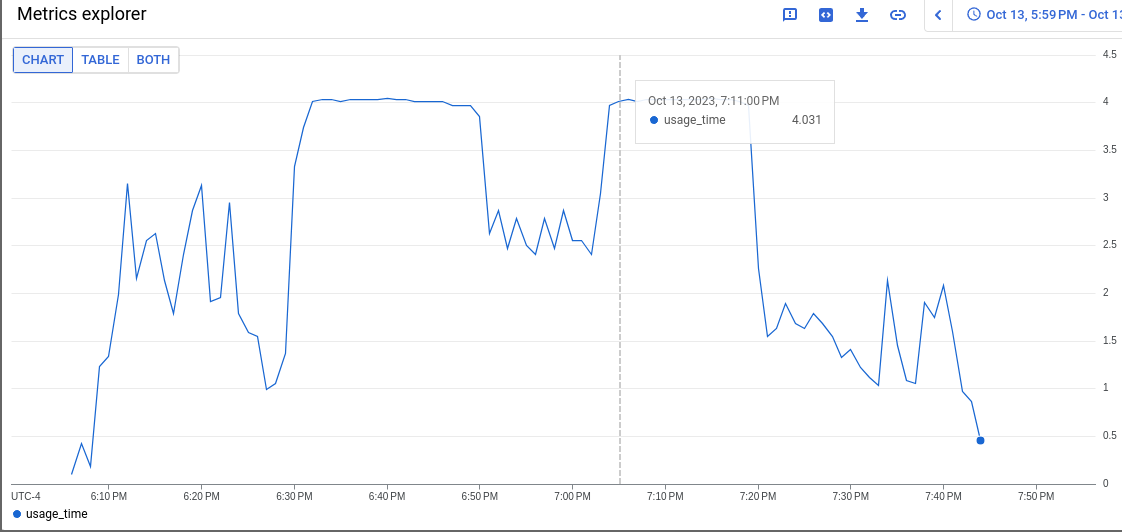
We began looking at this while chasing runs with serious disruption, that led to log statements that seemed to indicate CPU starvation.
GCP CI uses e2-standard-4 instances which are 4vcpu 16gb of RAM. This roughly matches AWS, but Azure uses 8vcpu 32gb RAM.
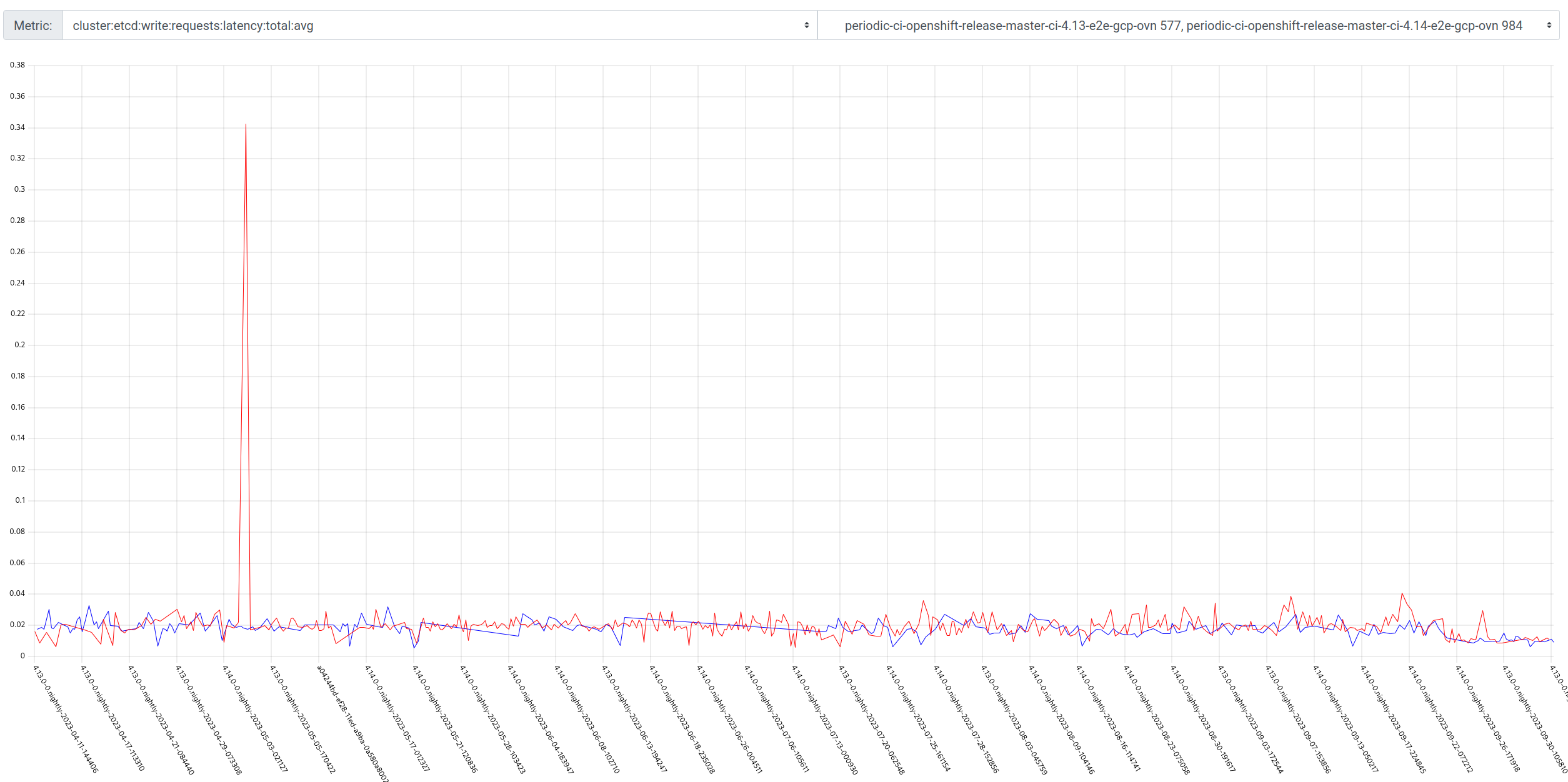
We did some investigation in the bug that started this (OCPBUGS-18544) and found that 6vcpus will drop the firing time for these alerts to almost 0, but they do enter a pending state for reasonably long periods of time. 8vcpu and the pending states are effectively gone. More vcpus helps, but for cost reasons we were asked to loop in the apiserver team for help to see if something is wrong here or not.
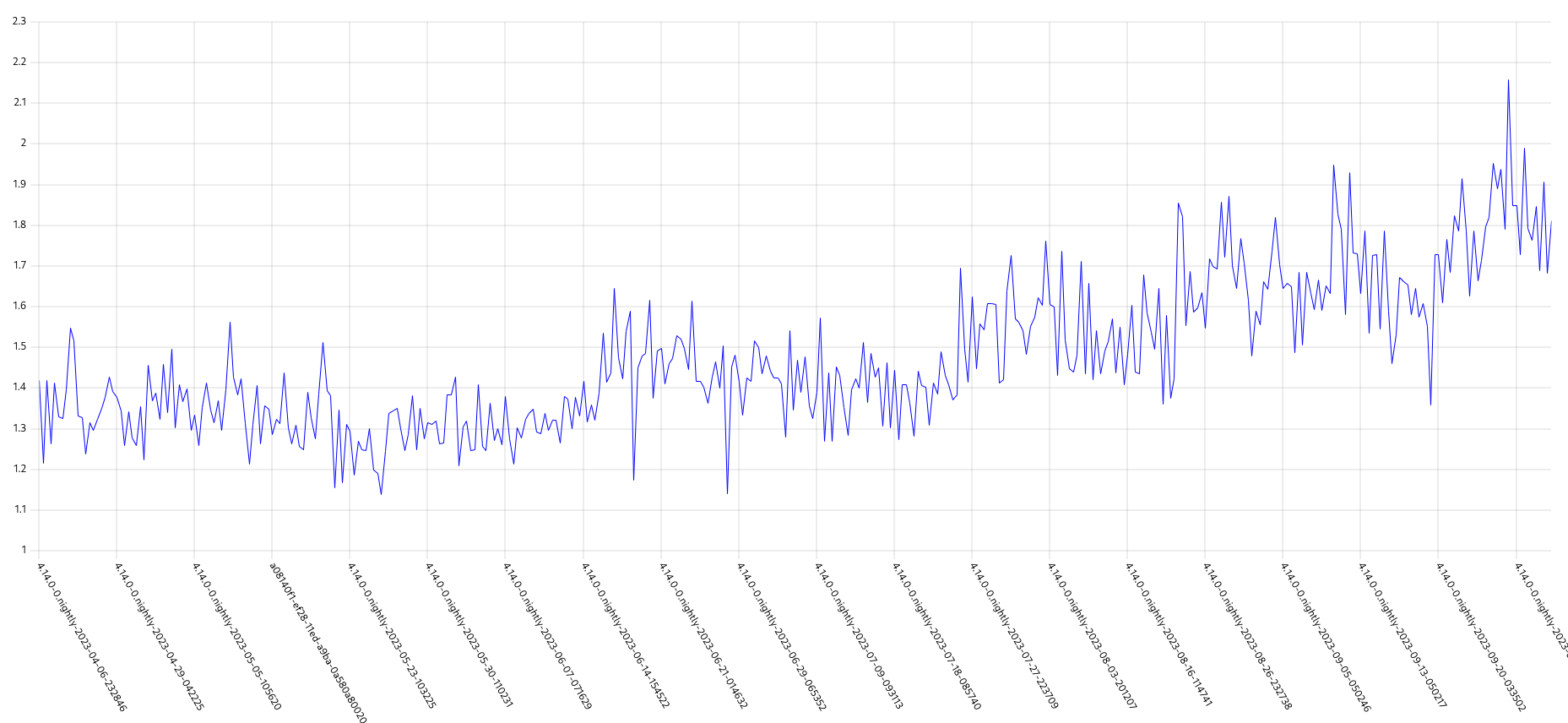
It appears the problem may have gotten worse in 4.14, the P50 has more than doubled for ExtremelyHighIndividual, from 200s to over 500s compared to 4.13. (DISCLAIMER: we cannot be 100% sure this comparison is accurate as our new numbers take whether or not the master nodes were updated during a micro upgrade into account, however given this is e2e exposed after upgrade, I think it appears the conclusion is valid, this does seem worse in 4.14)
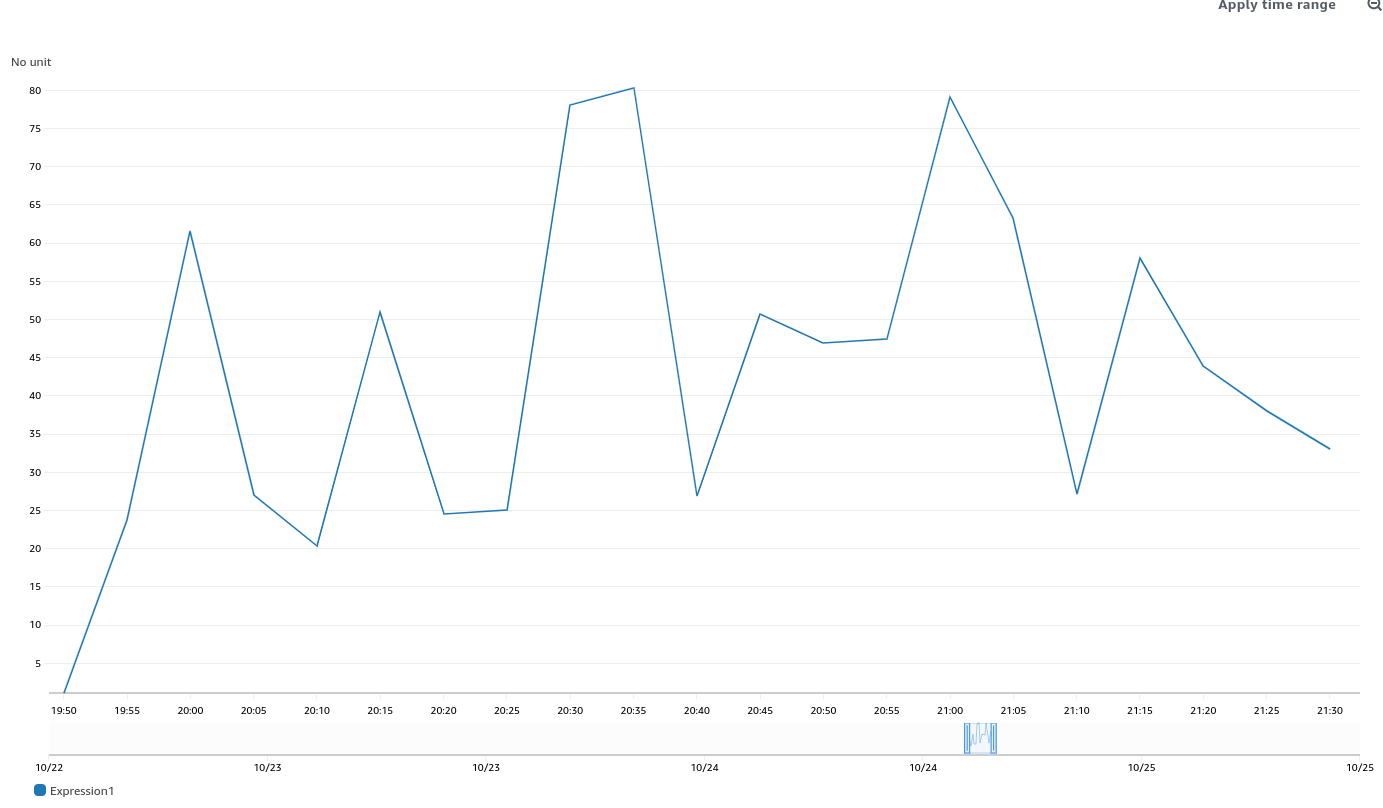
To find job runs experiencing high alert time, use the above dashboard links and scroll down to Most Recent Jobs runs, and click on any that high a high alert seconds. This number represents the firing time, we do not track pending in this database.
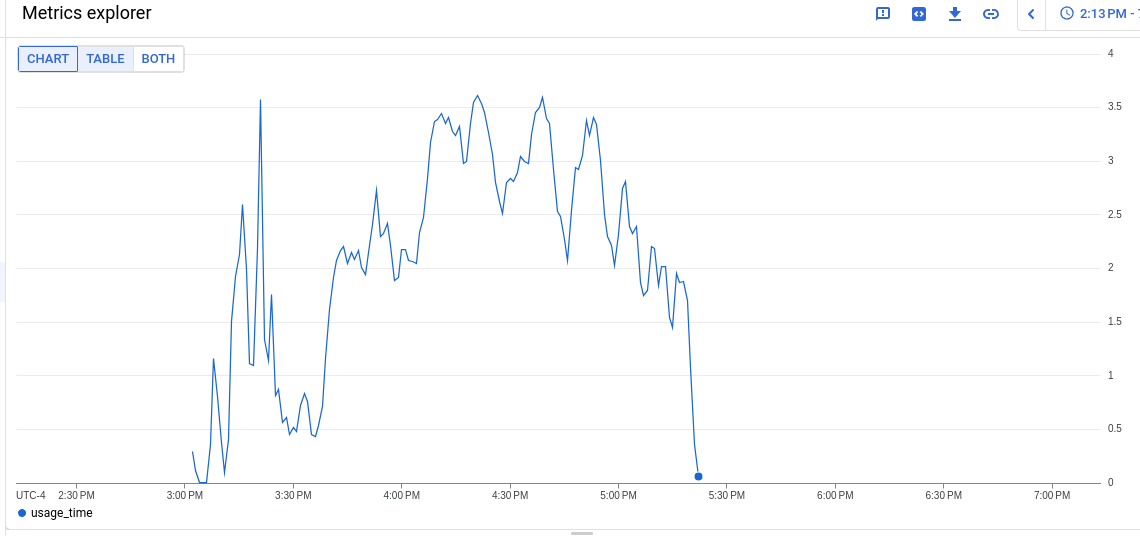
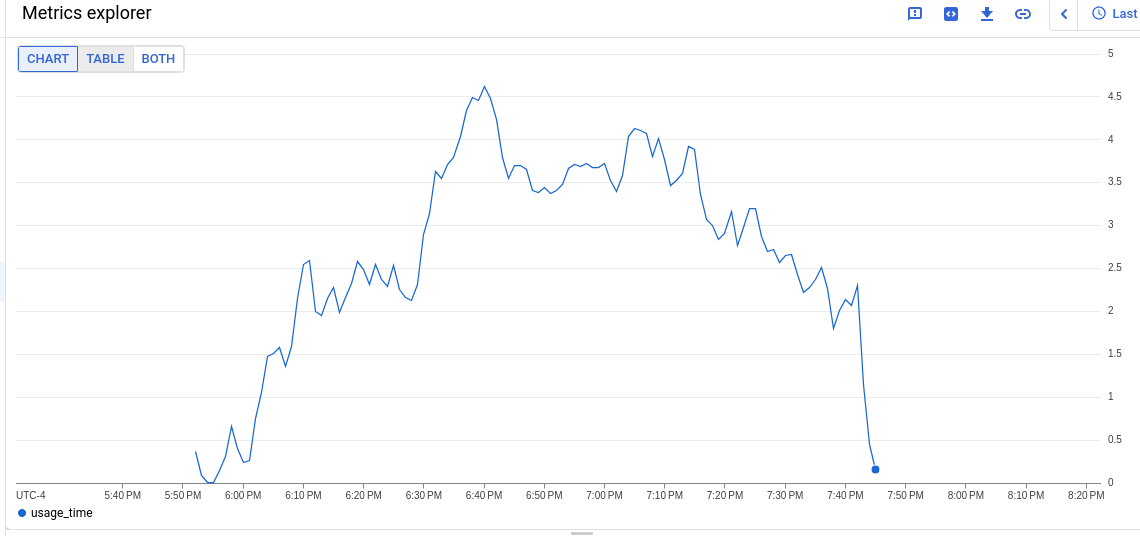
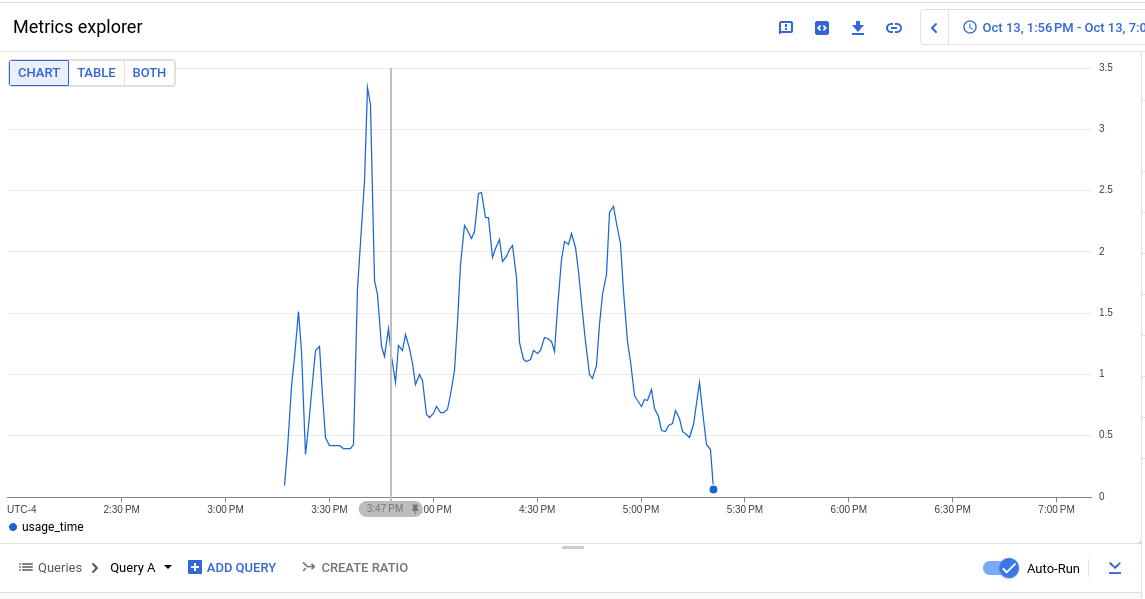
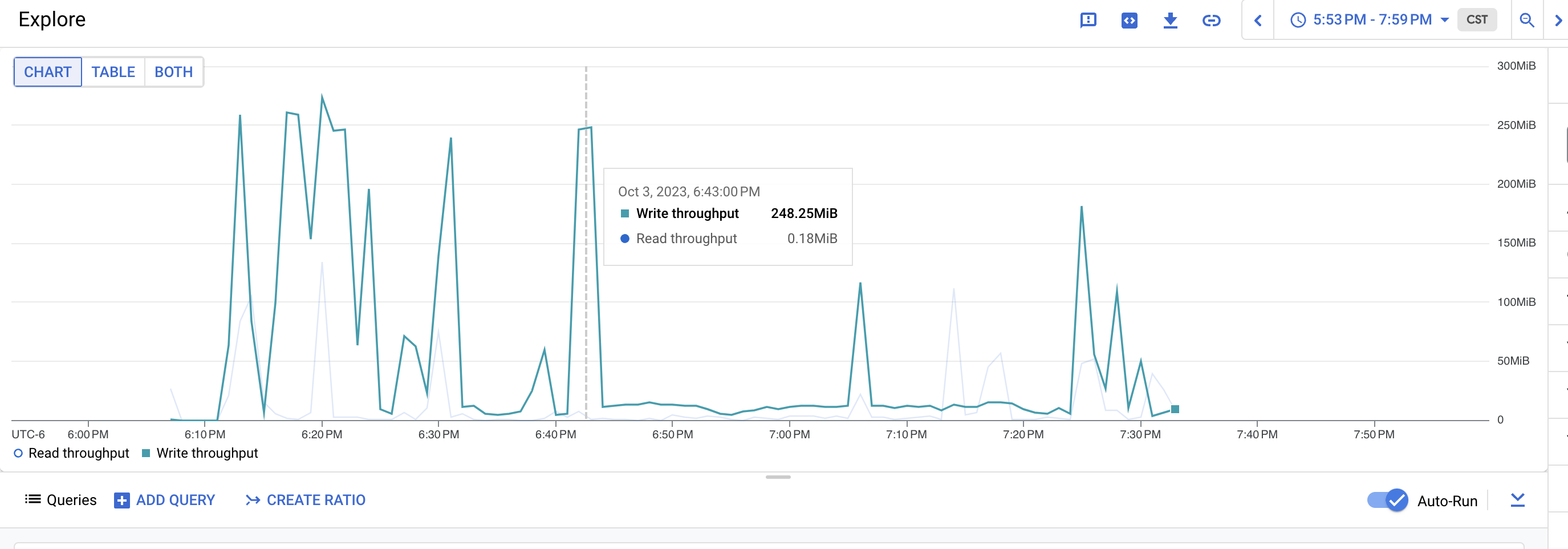
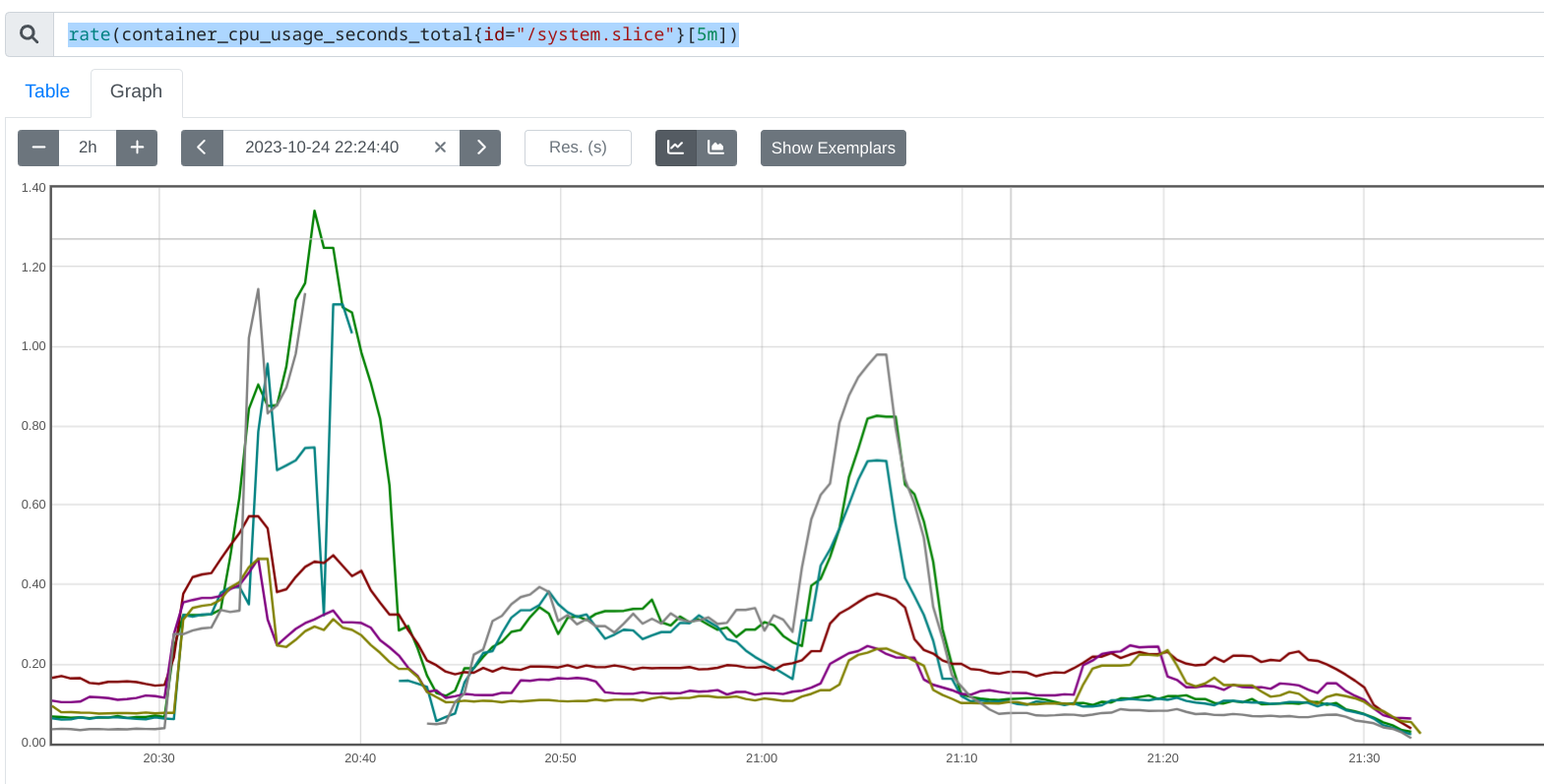
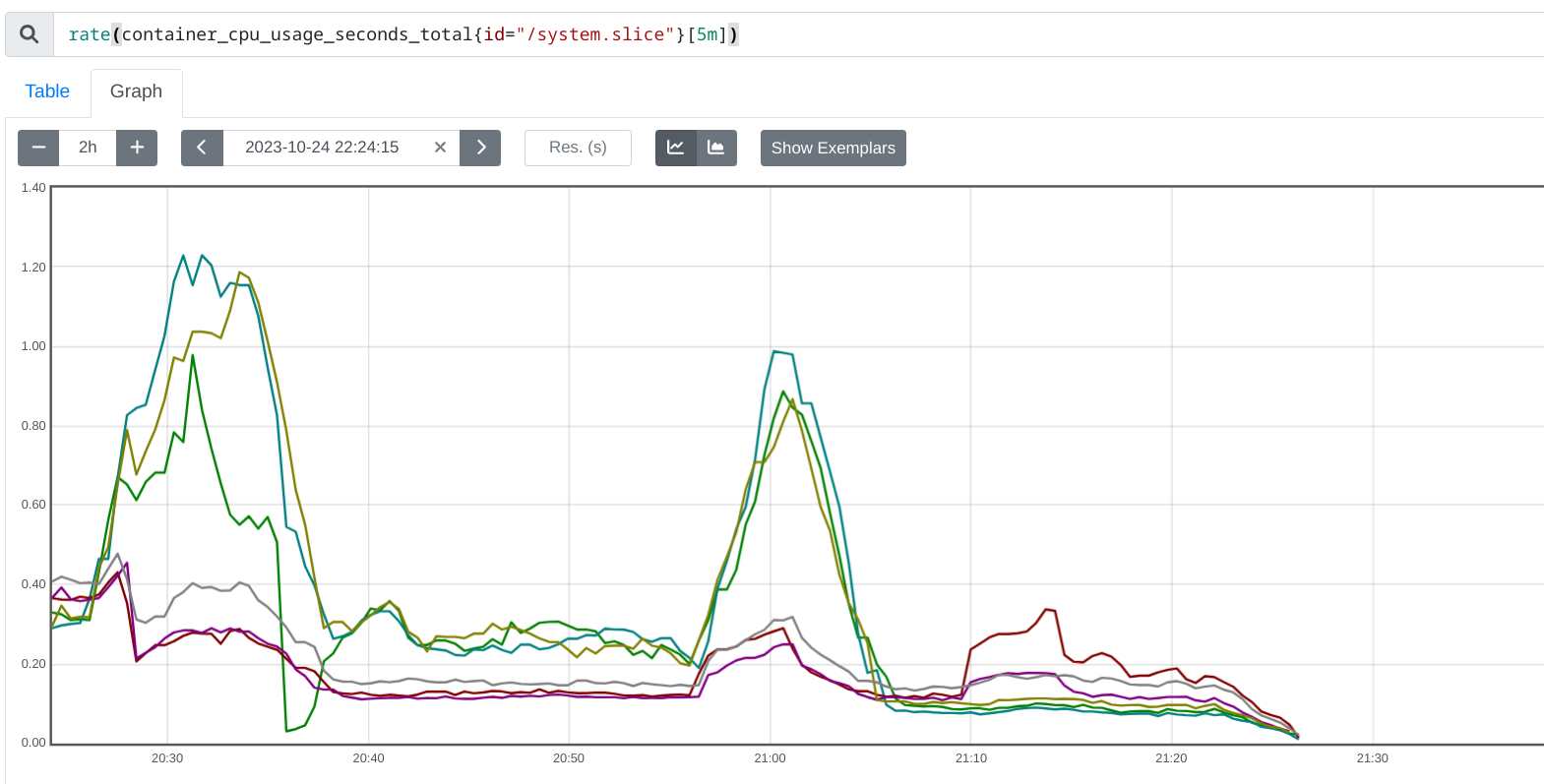
The PromeCIeus link under debug tools should be helpful in examining prom metrics during these runs, however we have seen some corrupted files which may be related to the extremely bad runs.
If you need metrics perhaps from one of the tests with 6 or 8 vcpu, these seem to have gotten valid prometheus data so it appears the high cpu is linked to corrupted metrics data:
8 vcpu with valid prom data but no high cpu alerts: https://prow.ci.openshift.org/view/gs/origin-ci-test/pr-logs/pull/openshift_release/43300/rehearse-43300-periodic-ci-openshift-release-master-ci-4.15-upgrade-from-stable-4.14-e2e-gcp-ovn-rt-upgrade/1702716280932405248
6 vcpu with valid prom data, high cpu alerts went pending but never firing: https://prow.ci.openshift.org/view/gs/origin-ci-test/pr-logs/pull/openshift_release/43416/rehearse-43416-periodic-ci-openshift-release-master-ci-4.15-e2e-gcp-ovn-upgrade/1702718765097029632
Additionally Justin Pierce may be able to help examine GCP cloud metrics for the vms if needed.
- relates to
-
-

- Closed
-


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}