-
Bug
-
Resolution: Done
-
 Critical
Critical
-
None
-
4.14
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
No
-
None
-
None
-
Rejected
-
SDN Sprint 242
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
4.14.0-0.nightly-2023-09-04-224539 failed periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade failed due to multiple kubectl timeout issues.
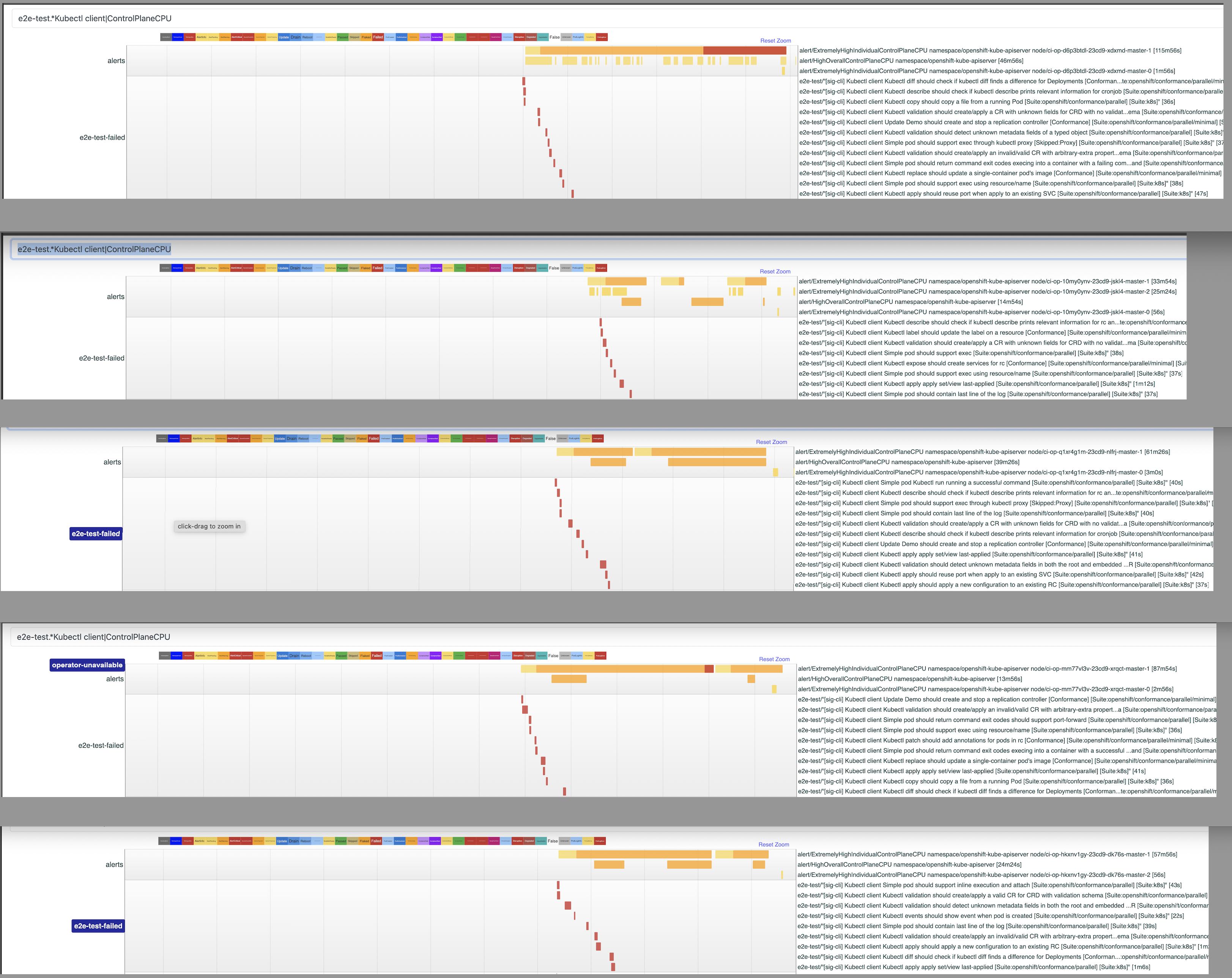
Investigating periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1698830727191203840 shows a large disruption event within the cluster based on the host-to-pod and pod-to-pod monitoring as observed in e2e-timelines_spyglass_20230905-011352.html

Version-Release number of selected component (if applicable):
How reproducible:
Multiple failures on payload 4.14.0-0.nightly-2023-09-04-224539
Steps to Reproduce:
1. 2. 3.
Actual results:
Expected results:
We do not expect disruption / failures invoking kubectl commands
Additional info:
Frequency
I believe querying for high host-to-host-new-connections disruption appears to be very good at finding these failures, the test failures will be somewhat random so I think this might be our best bet.
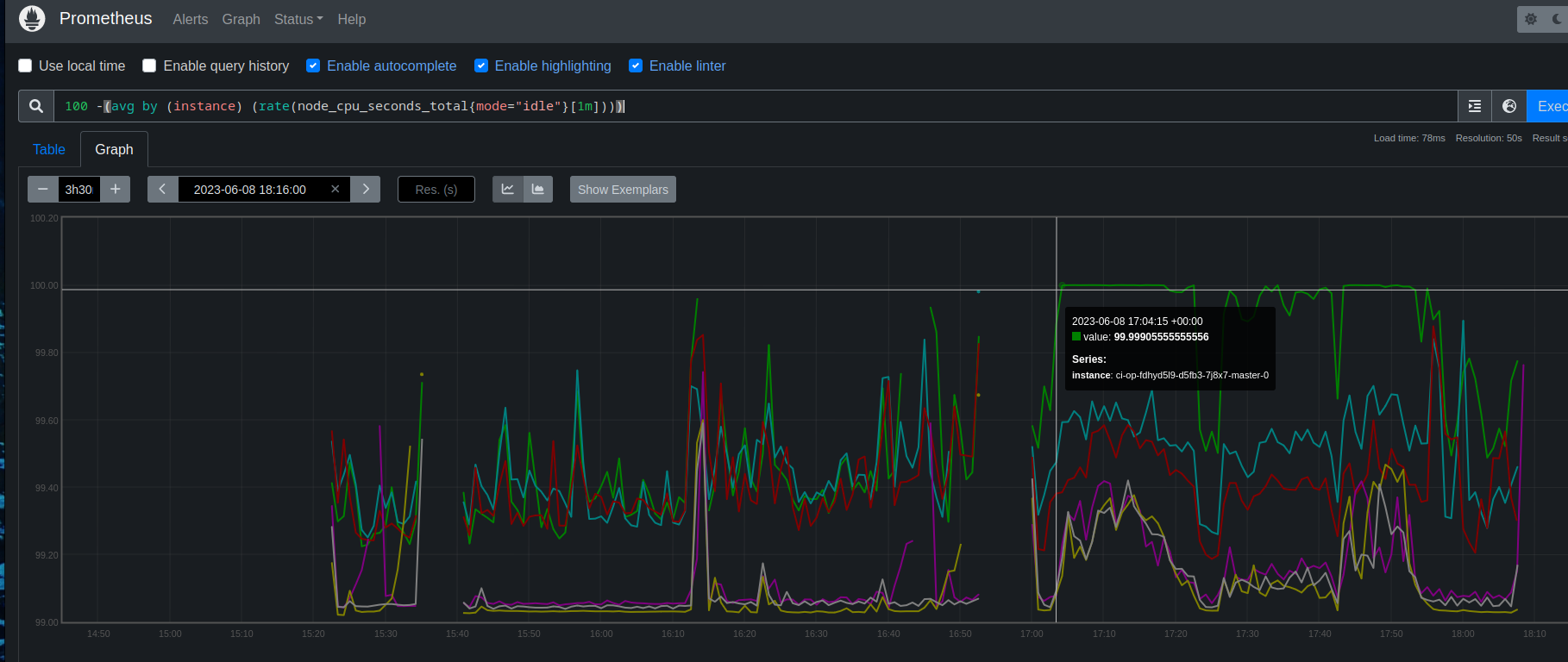
this query shows that with around 400 rt runs and 40 non-rt runs, both are experiencing a fail rate of 2-3%. However that is only one hit for non-rt. I am going to slowly kick off a few more jobs there to try to get more data and reproduce more hits.
This dashboard can be used to find the specific prow jobs with over 120s of host-to-host. Thus far everything I've opened exhibits the same "blood spatter" disruption pattern during the e2e phase of testing.

- is related to
-
-

- Closed
-