This was originally reported in BZ as https://bugzilla.redhat.com/show_bug.cgi?id=2046335
—
Description of problem:
The issue reported here https://bugzilla.redhat.com/show_bug.cgi?id=1954121 still occur (tested on OCP 4.8.11, the CU also verified that the issue can happen even with OpenShift 4.7.30, 4.8.17 and 4.9.11)
How reproducible:
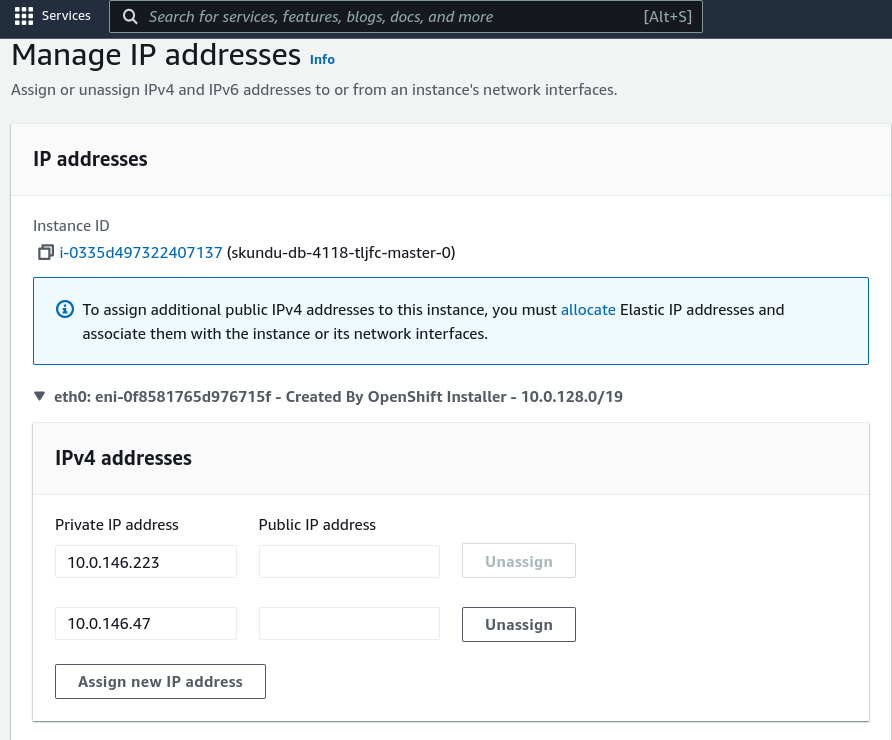
Attach a NIC to a master node will trigger the issue
Steps to Reproduce:
1. Deploy an OCP cluster (I've tested it IPI on AWS)
2. Attach a second NIC to a running master node (in my case "ip-10-0-178-163.eu-central-1.compute.internal")
Actual results:
~~~
$ oc get node ip-10-0-178-163.eu-central-1.compute.internal -o json | jq ".status.addresses"
[
,
,
,
{ "address": "ip-10-0-178-163.eu-central-1.compute.internal", "type": "InternalDNS" }]
$ oc get co etcd
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE
etcd 4.8.11 True False True 31h
$ oc get co etcd -o json | jq ".status.conditions[0]"
{ "lastTransitionTime": "2022-01-26T15:47:42Z", "message": "EtcdCertSignerControllerDegraded: [x509: certificate is valid for 10.0.178.163, not 10.0.187.247, x509: certificate is valid for ::1, 10.0.178.163, 127.0.0.1, ::1, not 10.0.187.247]", "reason": "EtcdCertSignerController_Error", "status": "True", "type": "Degraded" }~~~
Expected results:
To have the certificate valid also for the second IP (the newly created one "10.0.187.247")
Additional info:
Deleting the following secrets seems to solve the issue:
~~~
$ oc get secret n openshift-etcd | grep kubernetes.io/tls | grep ^etcd
etcd-client kubernetes.io/tls 2 61s
etcd-peer-ip-10-0-132-49.eu-central-1.compute.internal kubernetes.io/tls 2 61s
etcd-peer-ip-10-0-178-163.eu-central-1.compute.internal kubernetes.io/tls 2 61s
etcd-peer-ip-10-0-202-187.eu-central-1.compute.internal kubernetes.io/tls 2 60s
etcd-serving-ip-10-0-132-49.eu-central-1.compute.internal kubernetes.io/tls 2 60s
etcd-serving-ip-10-0-178-163.eu-central-1.compute.internal kubernetes.io/tls 2 59s
etcd-serving-ip-10-0-202-187.eu-central-1.compute.internal kubernetes.io/tls 2 59s
etcd-serving-metrics-ip-10-0-132-49.eu-central-1.compute.internal kubernetes.io/tls 2 58s
etcd-serving-metrics-ip-10-0-178-163.eu-central-1.compute.internal kubernetes.io/tls 2 59s
etcd-serving-metrics-ip-10-0-202-187.eu-central-1.compute.internal kubernetes.io/tls 2 58s
$ oc get secret n openshift-etcd | grep kubernetes.io/tls | grep ^etcd | awk '
' | xargs -I {} oc delete secret {} -n openshift-etcd
secret "etcd-client" deleted
secret "etcd-peer-ip-10-0-132-49.eu-central-1.compute.internal" deleted
secret "etcd-peer-ip-10-0-178-163.eu-central-1.compute.internal" deleted
secret "etcd-peer-ip-10-0-202-187.eu-central-1.compute.internal" deleted
secret "etcd-serving-ip-10-0-132-49.eu-central-1.compute.internal" deleted
secret "etcd-serving-ip-10-0-178-163.eu-central-1.compute.internal" deleted
secret "etcd-serving-ip-10-0-202-187.eu-central-1.compute.internal" deleted
secret "etcd-serving-metrics-ip-10-0-132-49.eu-central-1.compute.internal" deleted
secret "etcd-serving-metrics-ip-10-0-178-163.eu-central-1.compute.internal" deleted
secret "etcd-serving-metrics-ip-10-0-202-187.eu-central-1.compute.internal" deleted
$ oc get co etcd -o json | jq ".status.conditions[0]"
{ "lastTransitionTime": "2022-01-26T15:52:21Z", "message": "NodeControllerDegraded: All master nodes are ready\nEtcdMembersDegraded: No unhealthy members found", "reason": "AsExpected", "status": "False", "type": "Degraded" }~~~

- blocks
-
OCPBUGS-1758 [4.11] ETCD Operator goes degraded when a second internal node ip is added
-

- Closed
-
- clones
-
-
- Closed
-
- depends on
-
-
- Closed
-
- is cloned by
-
-
- Closed
-
- links to