-
Bug
-
Resolution: Done
-
 Critical
Critical
-
4.12
-
Quality / Stability / Reliability
-
False
-
-
None
-
Critical
-
None
-
None
-
Rejected
-
ETCD Sprint 226
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
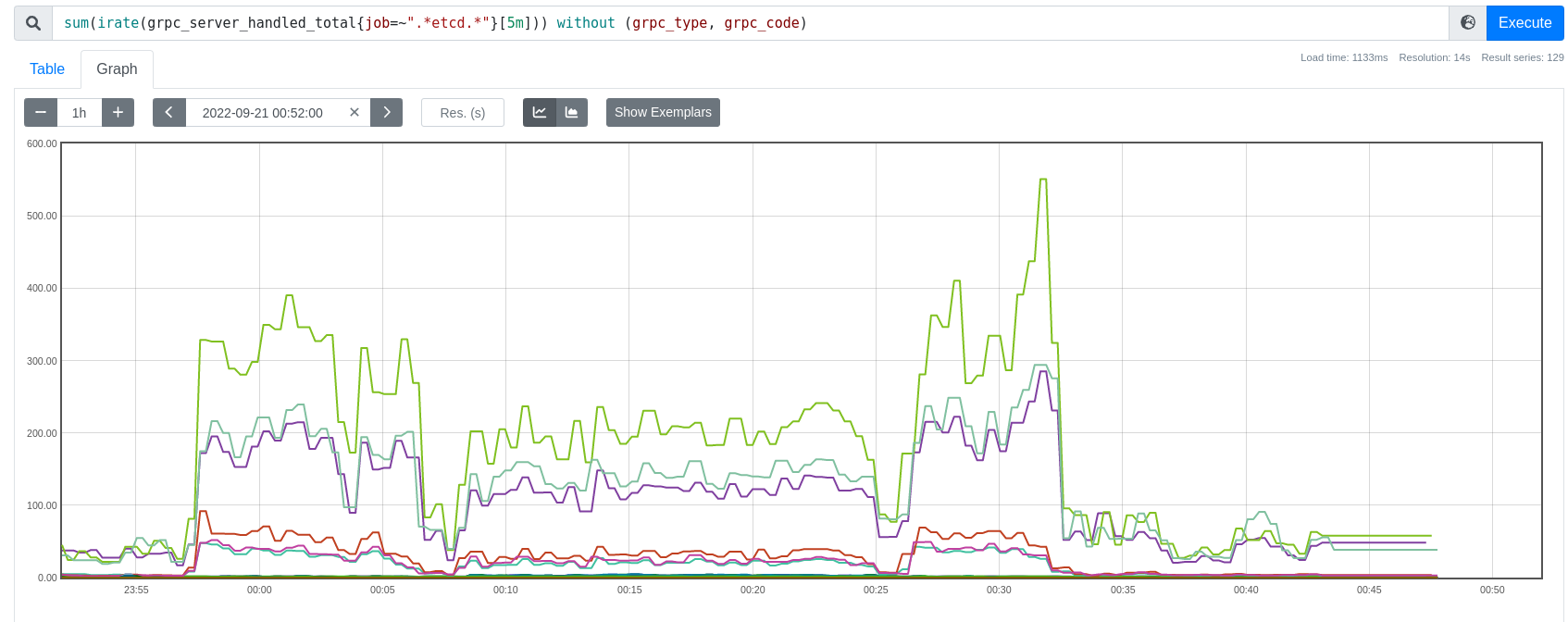
The test results in sippy look really bad on our less common platforms, but still pretty unacceptable even on core clouds. It's reasonably often the only test that fails. We need to decide what to do here, and we're going to need input from the etcd team.
As of Sep 13th:
- several vsphere and openstack variant combo's fail this test around 24-32% of the time
- aws, amd64, ovn, upgrade, upgrade-micro, ha - fails 6% of the time
- aws, amd64, ovn, upgrade, upgrade-minor, ha - fails 4% of the time
- gcp, amd64, sdn, upgrade, upgrade-minor, ha - fails 8% of the time
- globally across all jobs fails around 3% of the time.
Even on some major variant combos, a 4-8% failure rate is too high.
On Sep 13 arch call (no etcd present), Damien mentioned this might be an upstream alert that just isn't well suited for OpenShift's use cases, is this the case and it needs tuning?
Has the problem been getting worse?
I believe this link https://datastudio.google.com/s/urkKwmmzvgo indicates that this may be the case for 4.12, AWS and Azure are both getting worse in ways that I don't see if we change the release to 4.11 where it looks consistent. gcp seems fine on 4.12. We do not have data for vsphere for some reason.
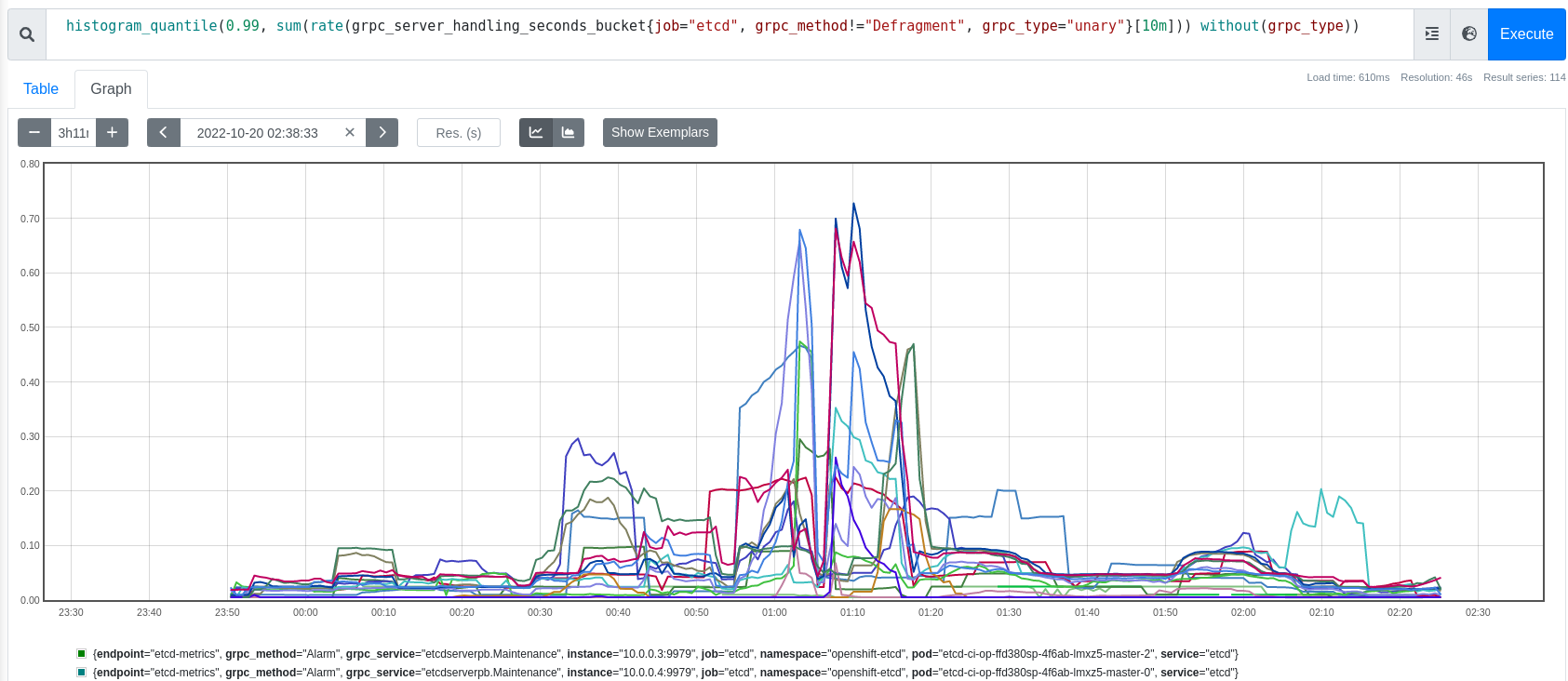
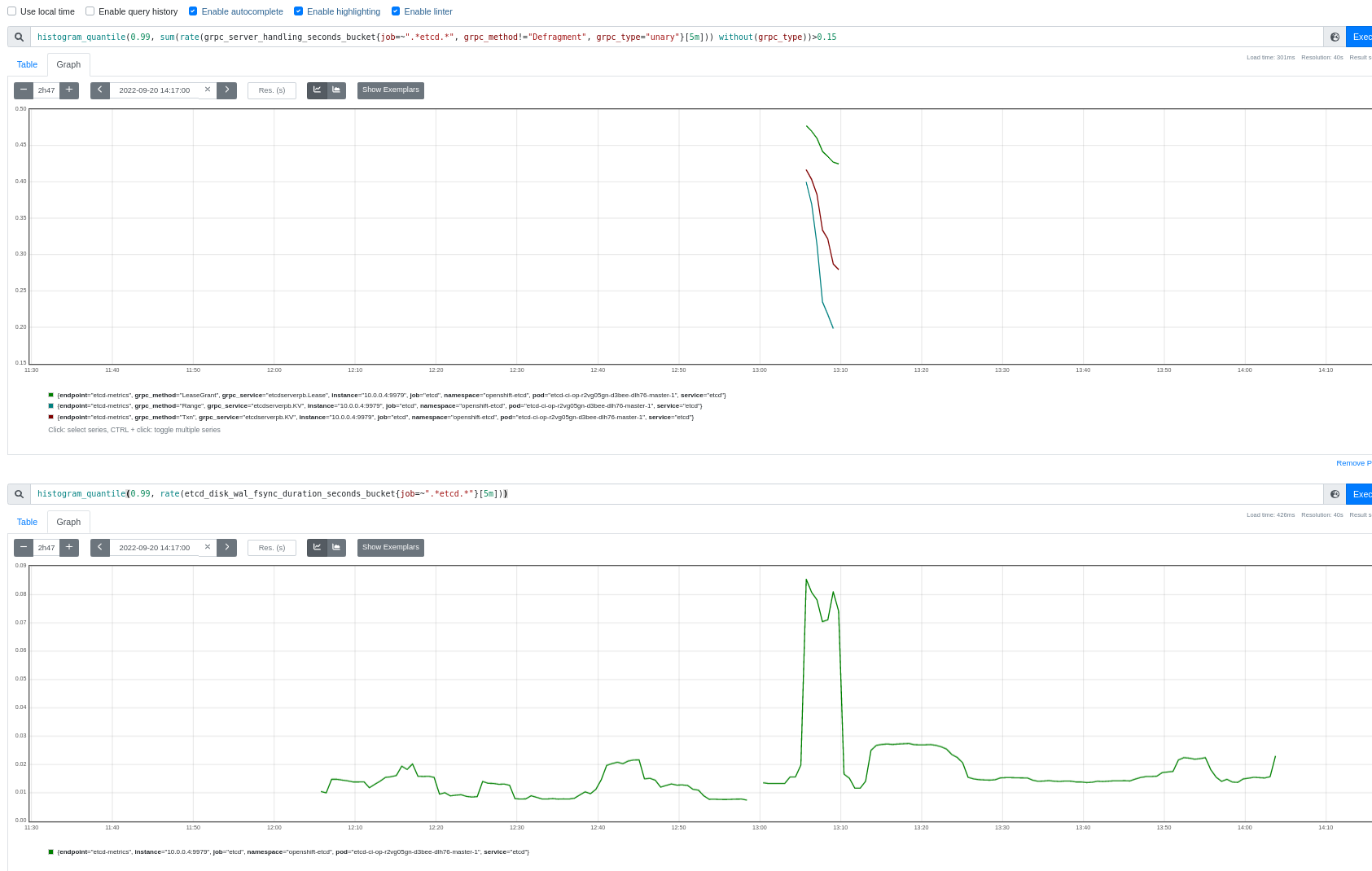
This link shows the grpc_methods most commonly involved: https://search.ci.openshift.org/?search=etcdGRPCRequestsSlow+was+at+or+above&maxAge=48h&context=7&type=junit&name=&excludeName=&maxMatches=5&maxBytes=20971520&groupBy=job
At a glance: LeaseGrant, MemberList, Txn, Status, Range.
Broken out of TRT-401
For linking with sippy:
[bz-etcd][invariant] alert/etcdGRPCRequestsSlow should not be at or above info
[sig-arch][bz-etcd][Late] Alerts alert/etcdGRPCRequestsSlow should not be at or above info [Suite:openshift/conformance/parallel]





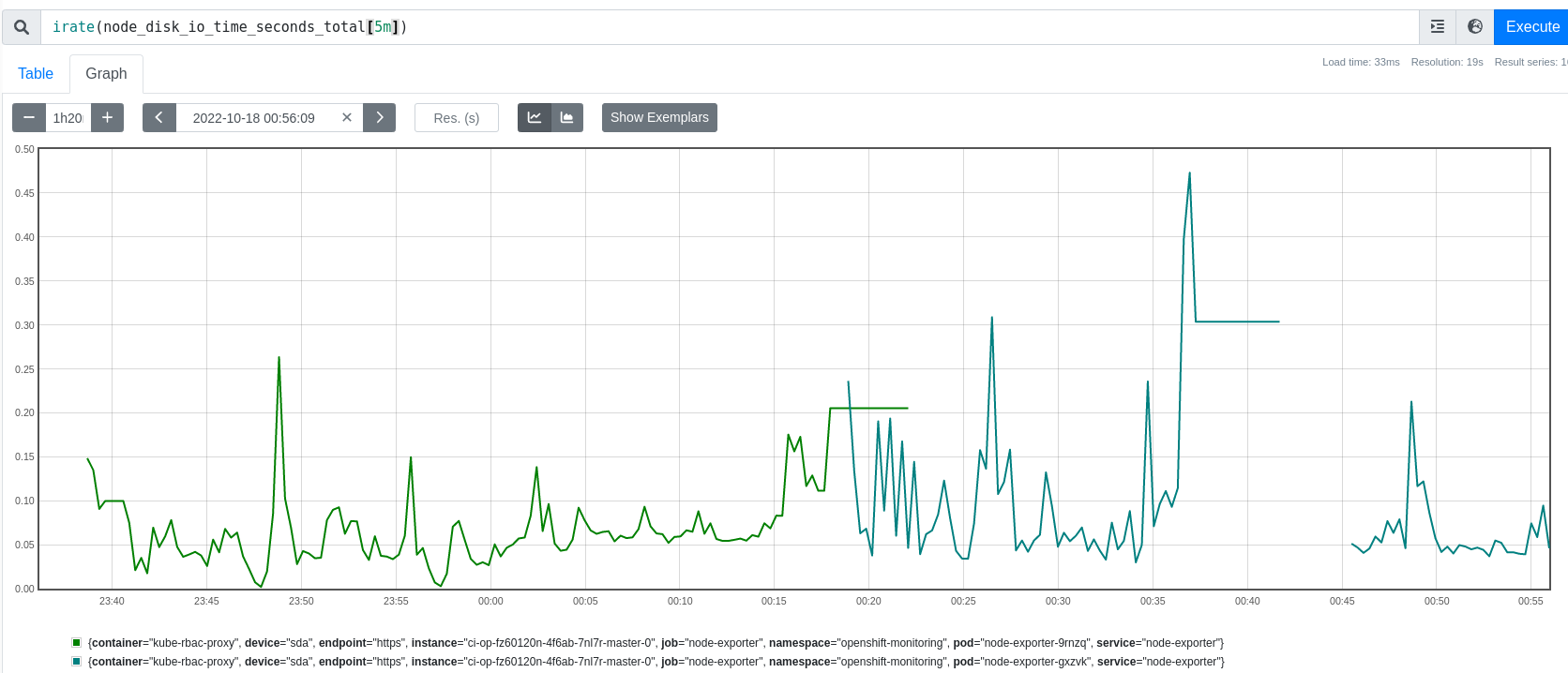
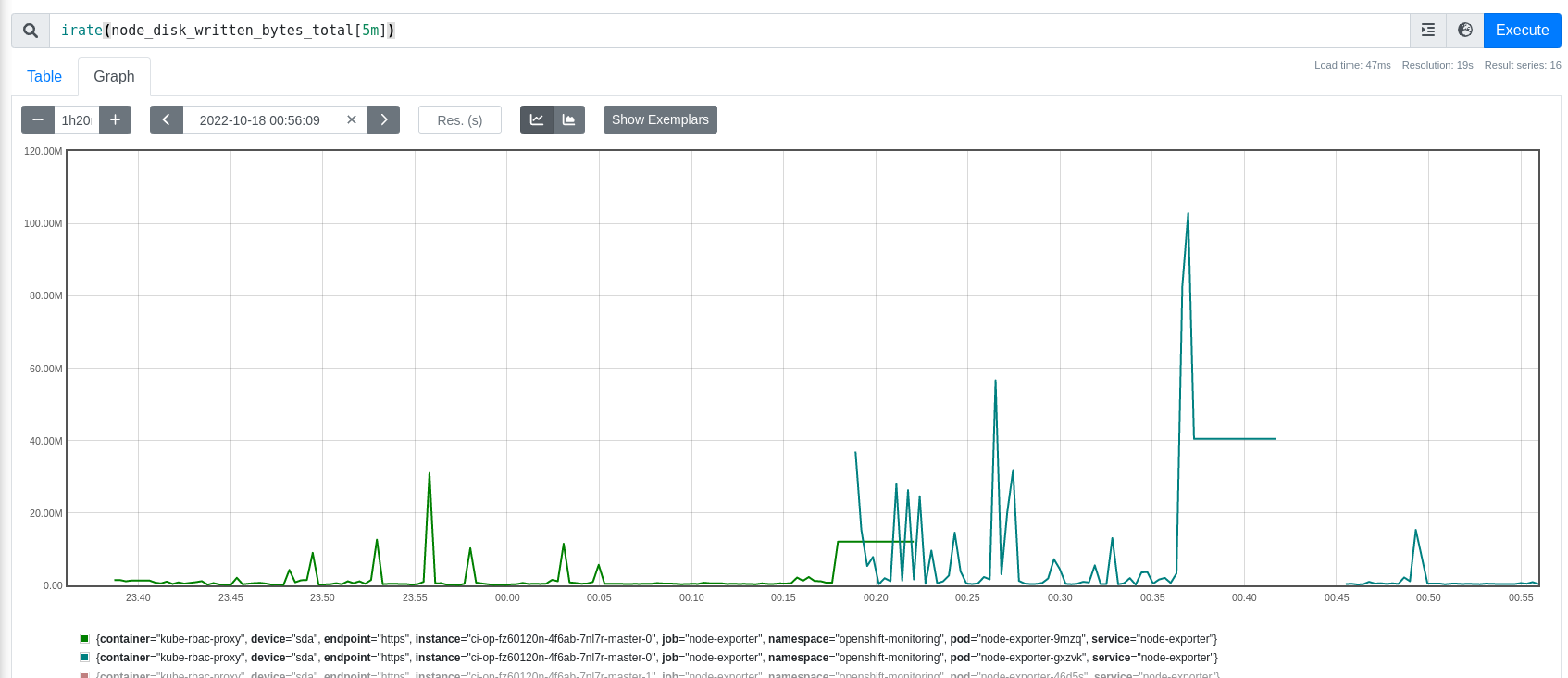

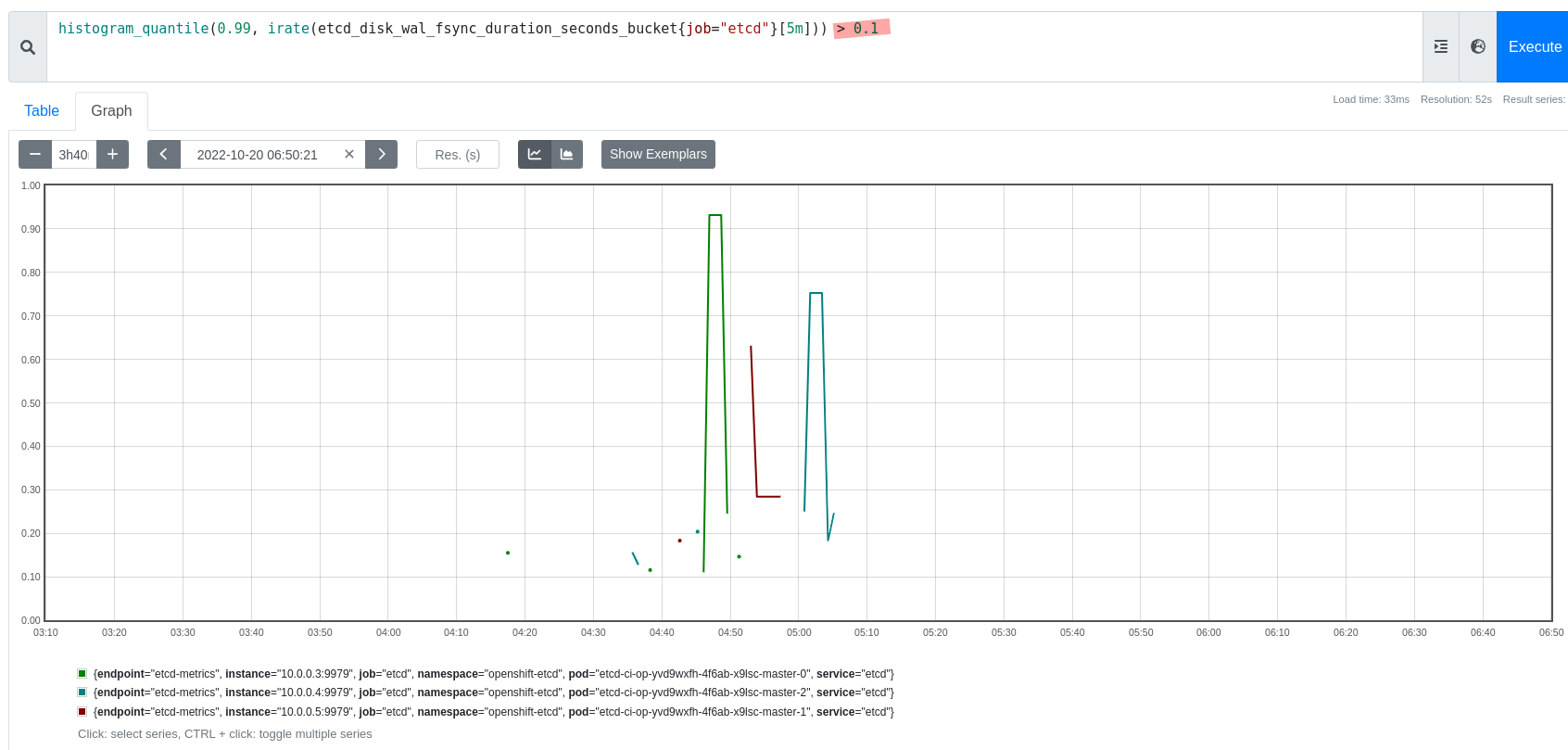
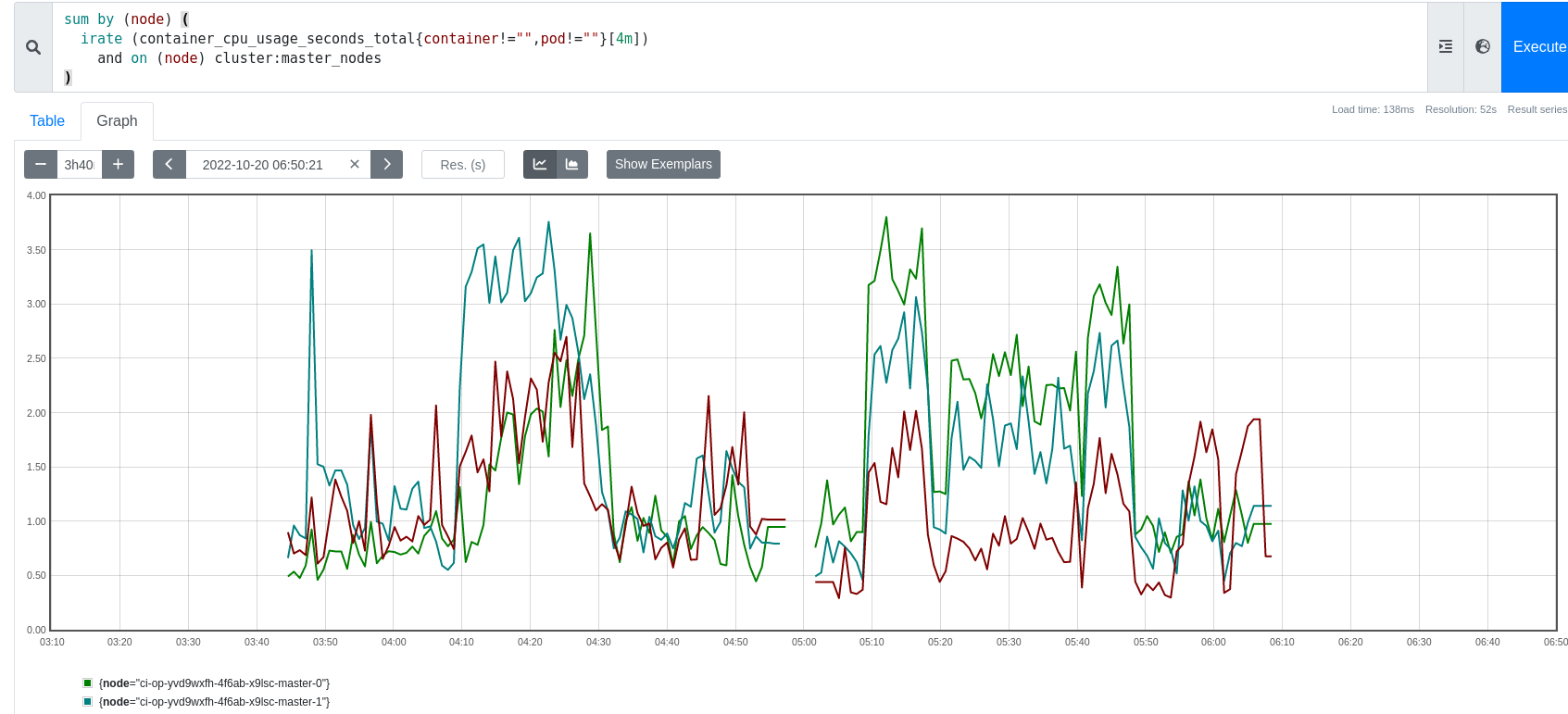

- blocks
-
-
- Closed
-
- is blocked by
-
-

- Closed
-
- is cloned by
-
-
- Closed
-
- is related to
-
-
- Closed
-
- links to

