-
Bug
-
Resolution: Done
-
 Critical
Critical
-
None
-
None
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
NetObserv - Sprint 225, NetObserv - Sprint 226, NetObserv - Sprint 227
-
None
-
None
-
None
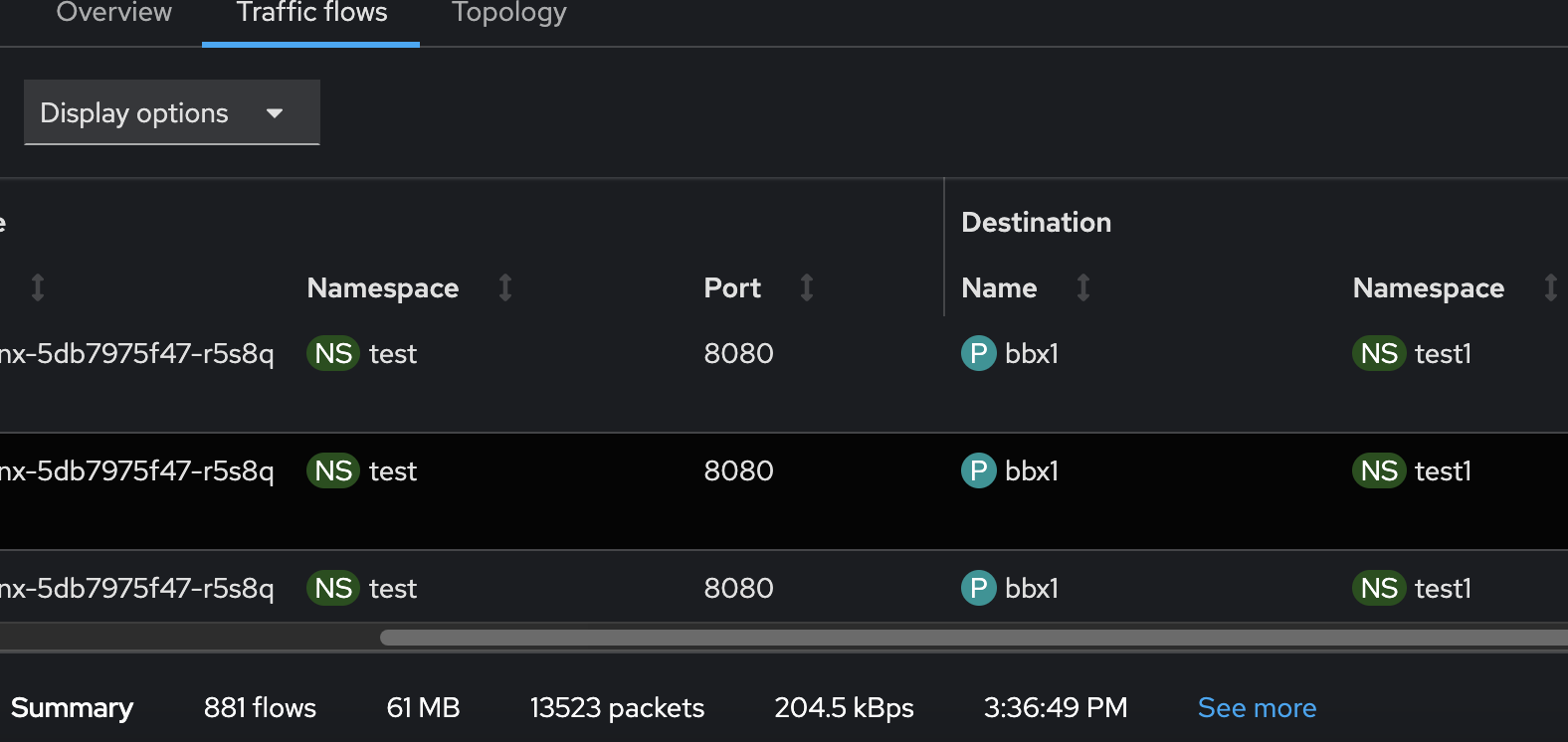
After adding more bytes counter metrics, I'm trying to validate the correctness using different sources :
- Our Topology view
- Loki + Grafana
- These new metrics
- Existing cluster metrics
The bad news is, none of them match perfectly, they all differ. But I can see an explanation for the new metrics vs cluster metrics mismatch.
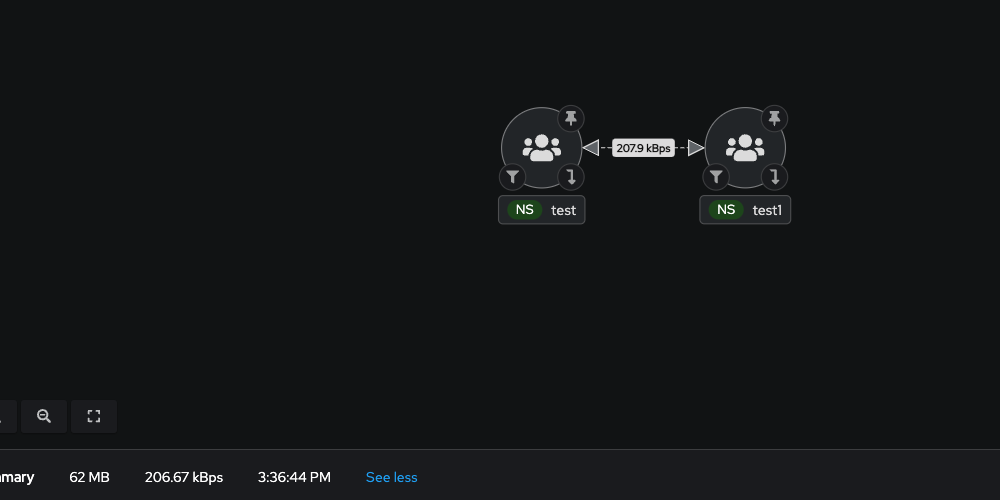
I'm considering for instance the bytes sent from Loki pod (in a single-pod deployment), reported from destination. Note that I have sampling set to 1.
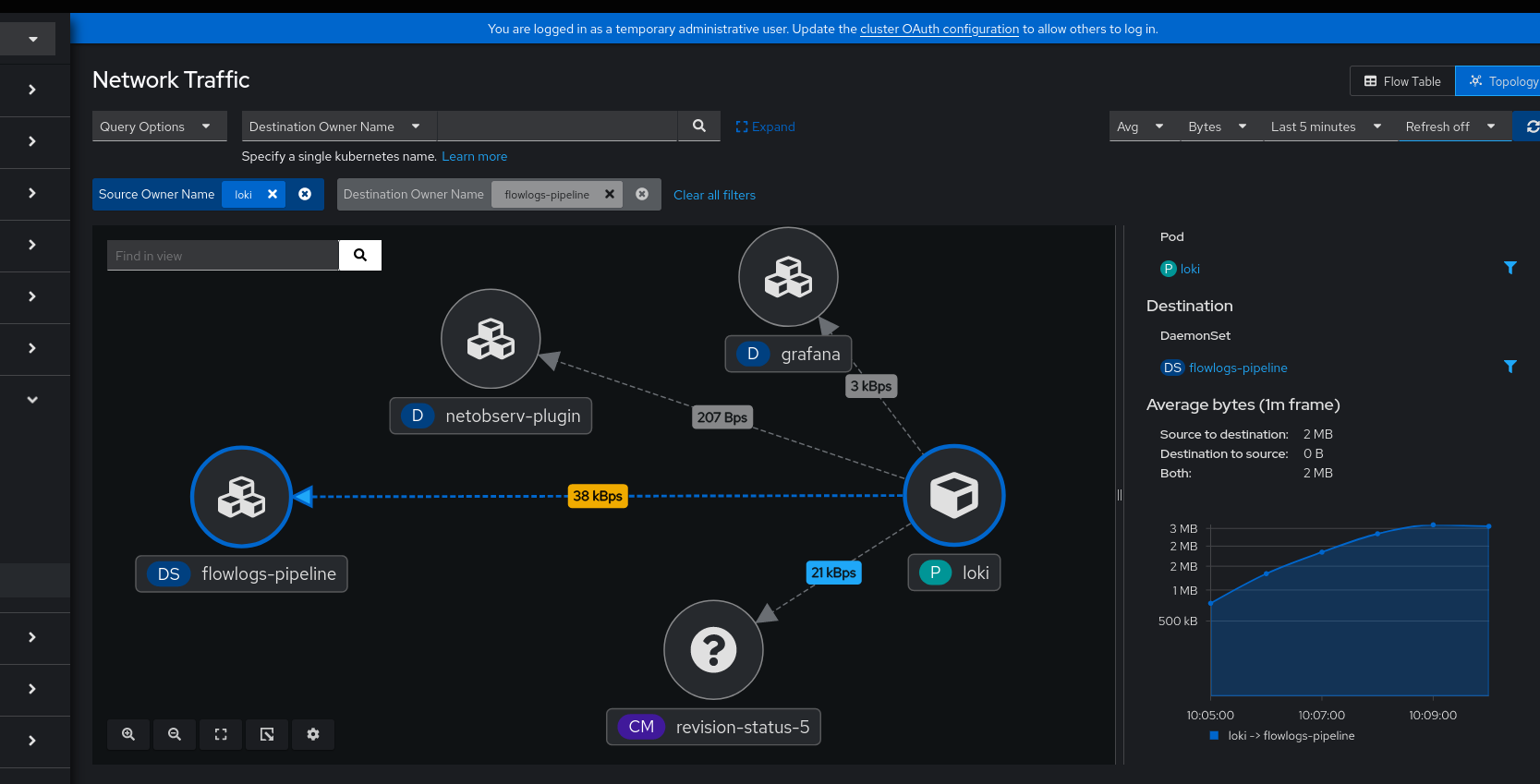
1. Topology:

AVG ~= 62 KBps
2. Loki+Grafana:
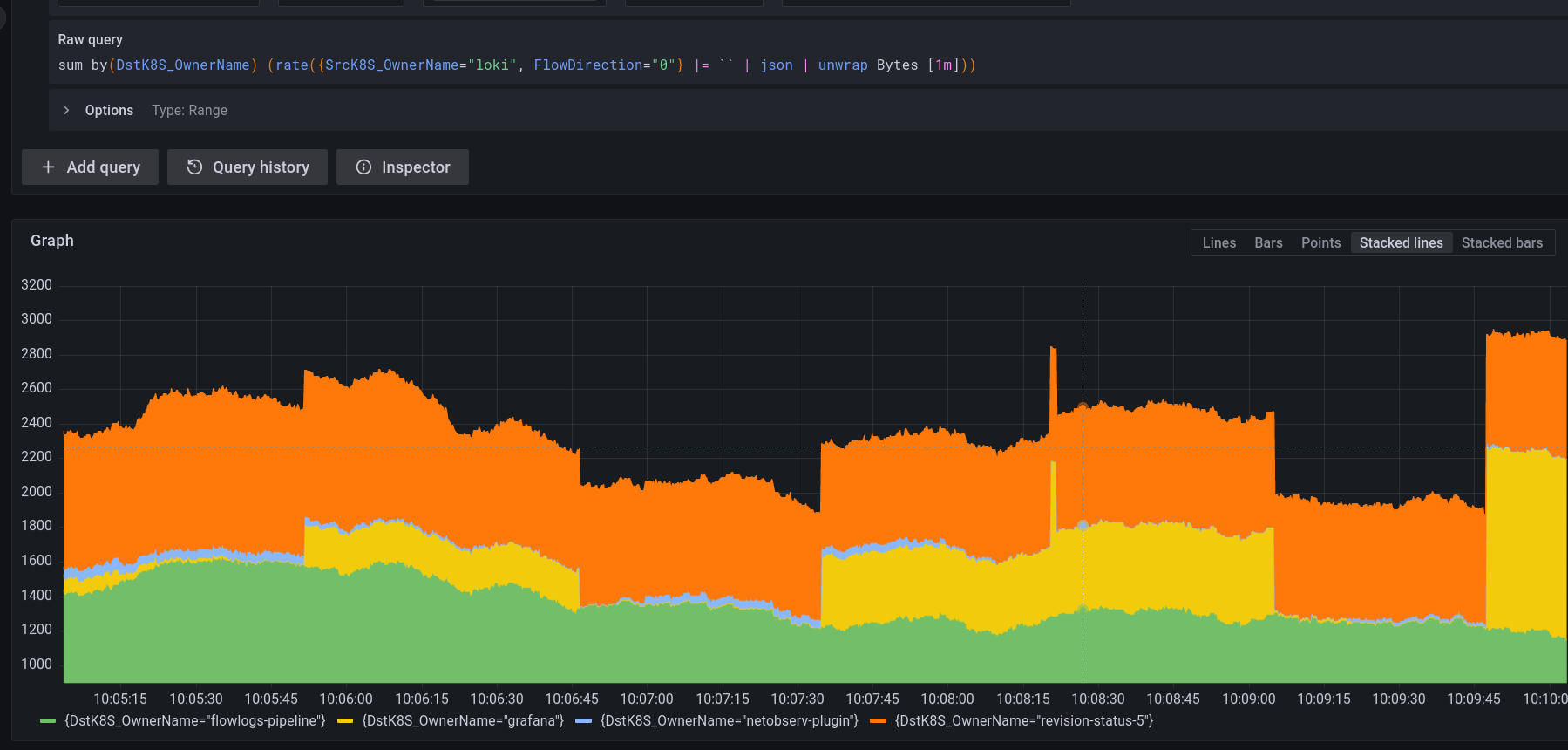
AVG ~= 2.4 KBps
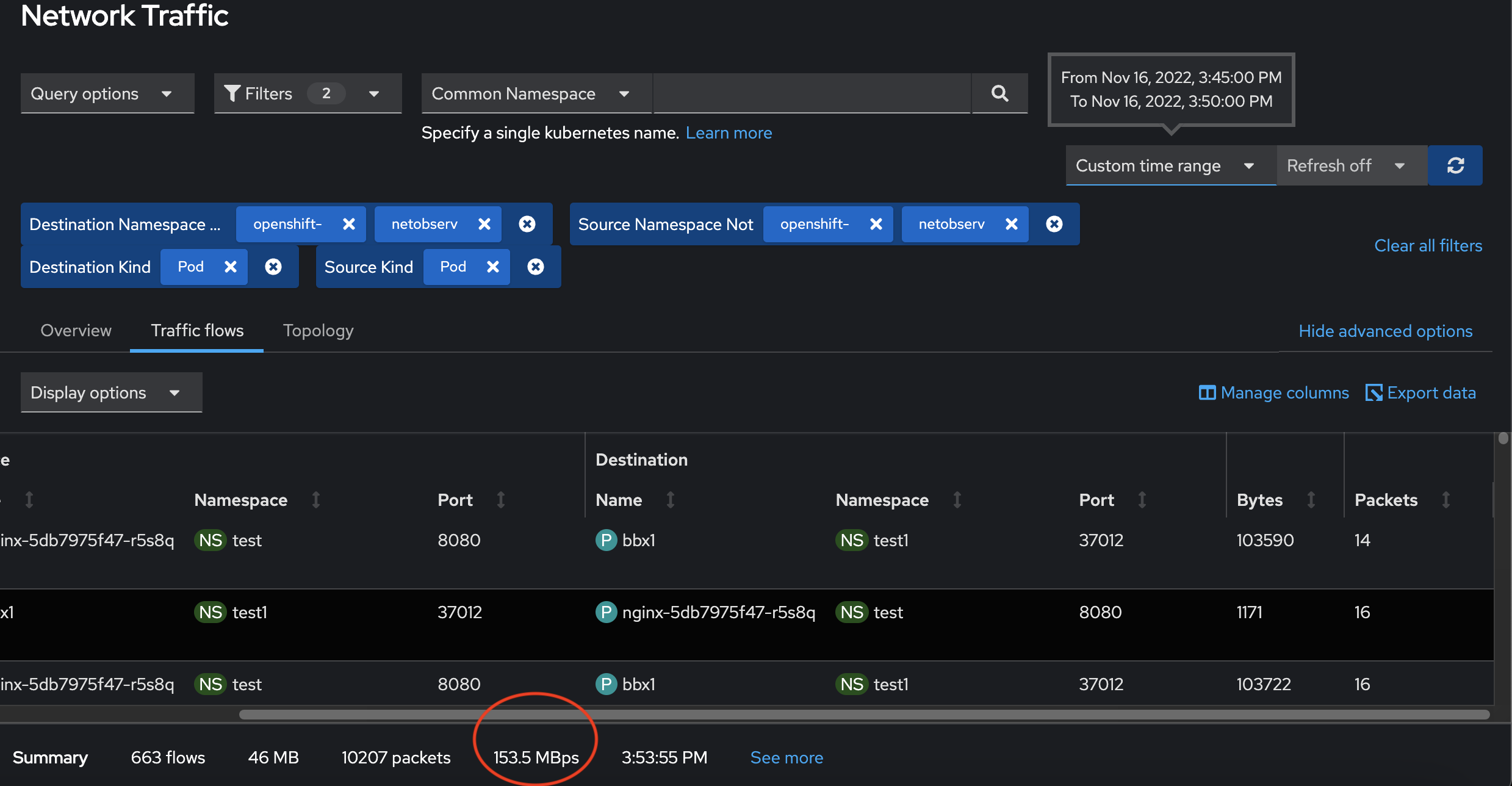
3. New metrics:
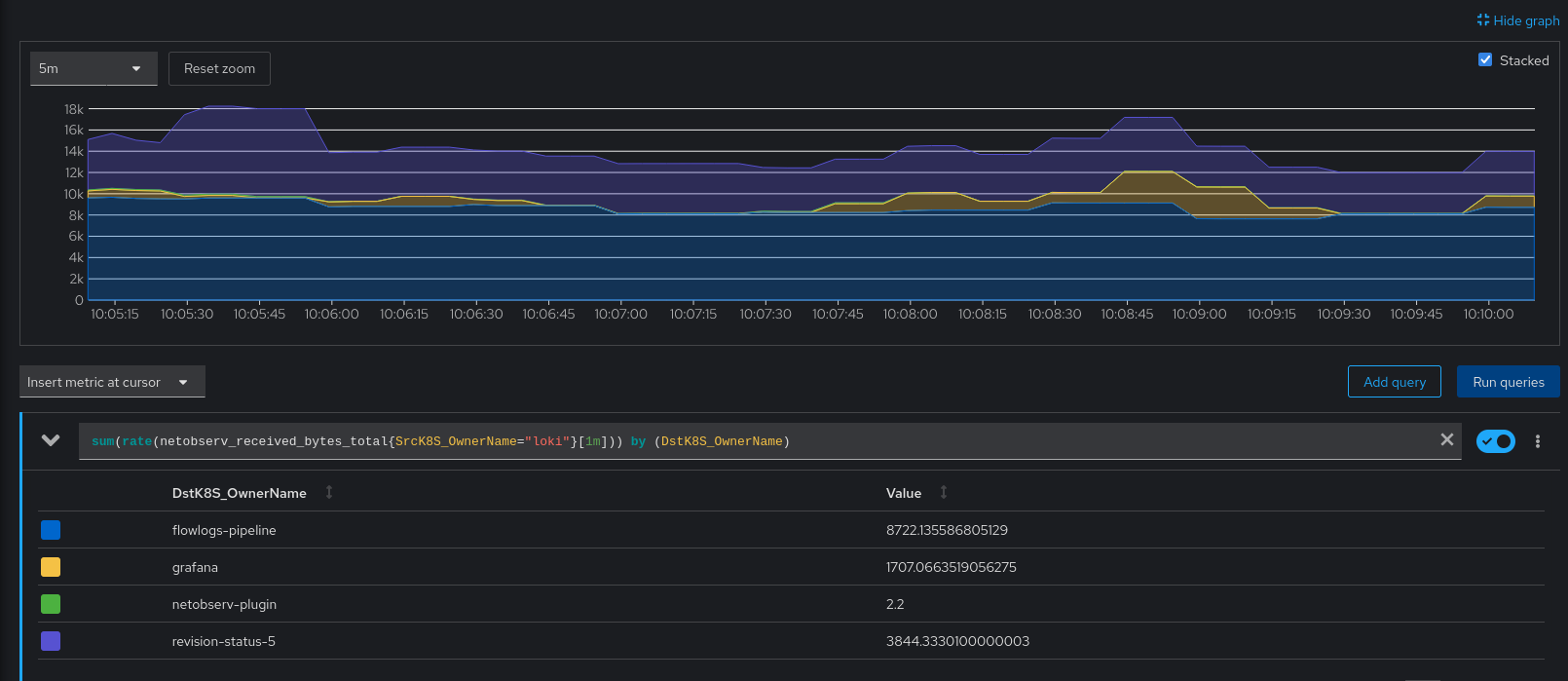
AVG ~= 15 KBps
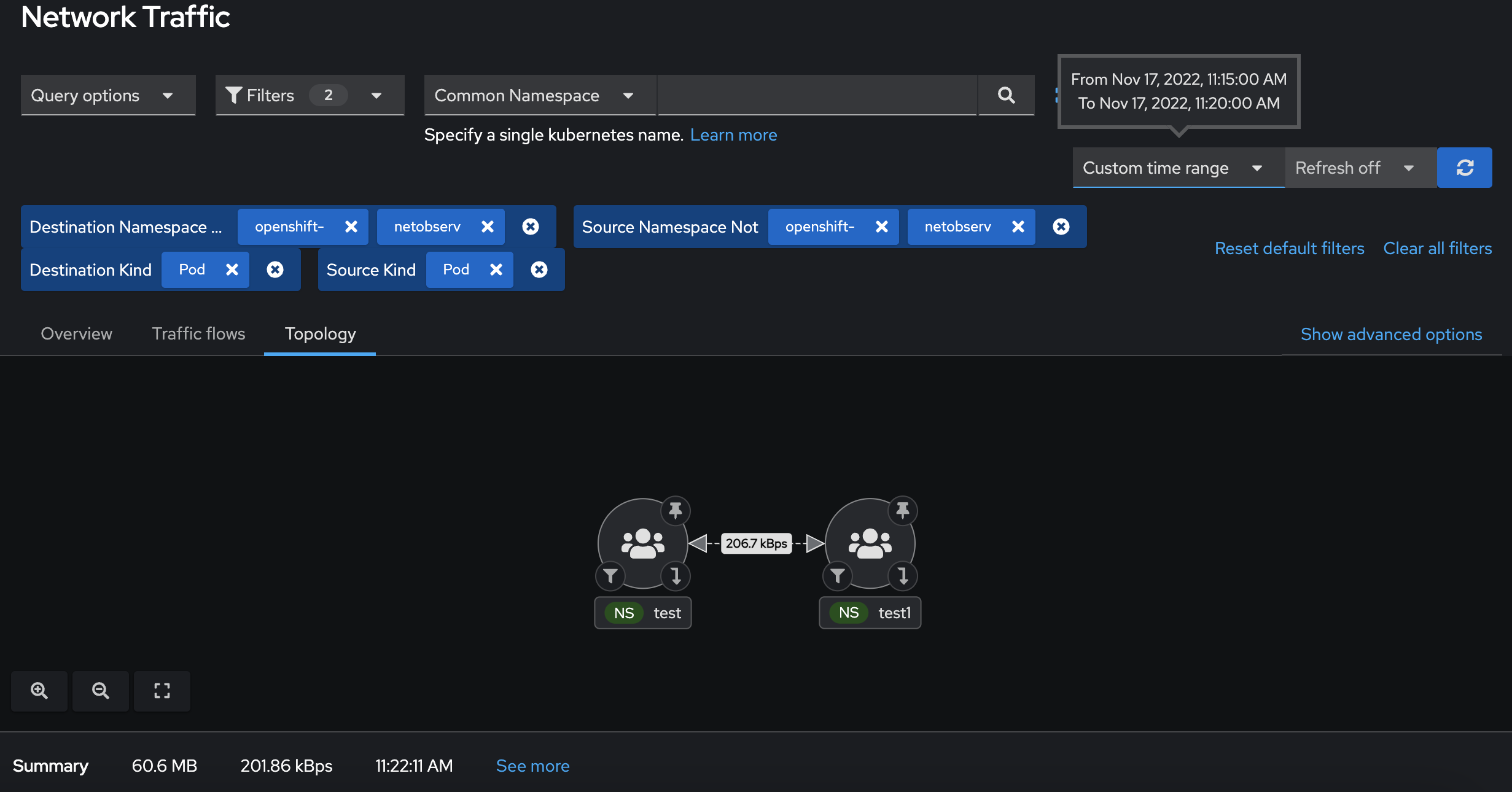
4. Existing cluster metrics:

AVG ~= 8 KBps
1 and 2 are using exactly the same data source: Loki; and the same query language: logQL. I must be missing something, because I think we should get the same results. In any case the byterate displayed in the console plugin seems wrong.
3 is obtained from the first primary source (ebpf agent), but then via prometheus / promQL.
4 is, afaik, a container/cadvisor metric.
My current explanation for 3 vs 4 discrepancy is that there's a known issue with the eBPF agent, as it is monitoring all interfaces (pods and nodes), resulting in duplicated data. Assuming this is the case, dividing by two would give us something coherent with 4.
Then, I don't explain the result with 2. It is significantly lower than 3, and would be even worse if we divide it by two. Is that Loki / LogQL doing a poor job at extracting timeseries? I hope not, but it should be investigated.
Same for 1., either I am missing something that I don't capture with my queries, or I'd expect to see similar values as 2. since it's using the same data source.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}