-
Bug
-
Resolution: Duplicate
-
 Major
Major
-
None
-
None
-
None
-
None
-
5
-
False
-
-
False
-
Yes
-
MK - Sprint 232
WHAT
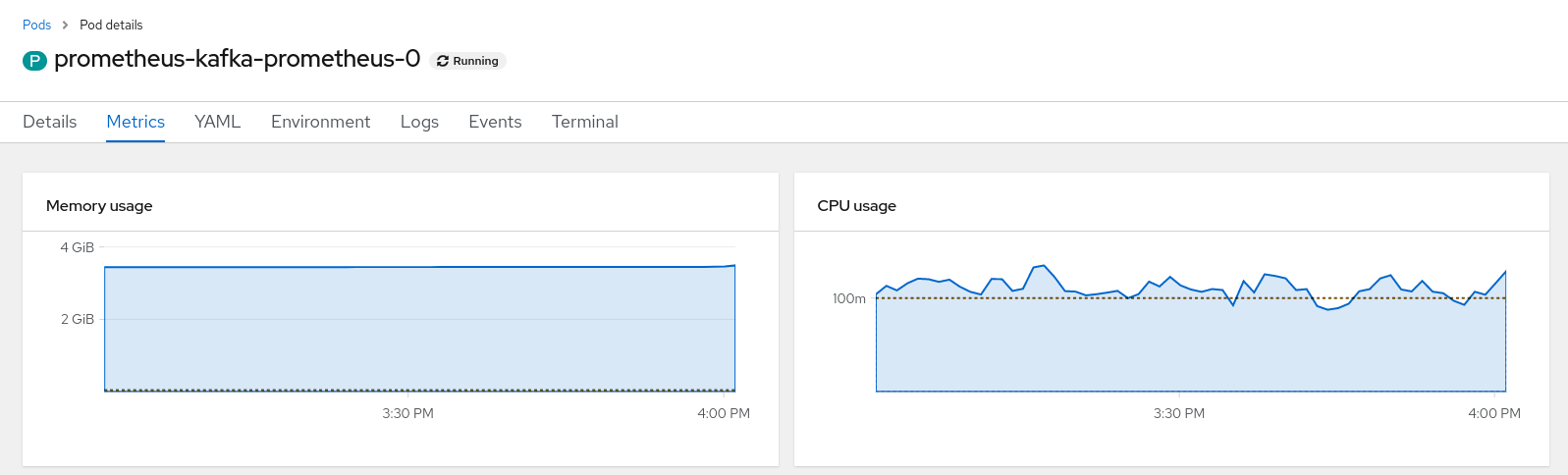
Looking at the production OSD instance's `prometheus-kafka-prometheus-0` pod's metrics in the `managed-application-services-observability` namespace the memory and CPU limits seem to be lower than what the system seems to require.
WHY
While looking at Single AZ cluster and its requirements for the additional nodes it came to observation that most of the pods in the namespace `managed-application-services-observability` do not define explicit cpu/memory limits, even where specified seem to be under-represented by their need. In tightly packed system like single AZ the pods can be placed on this node claiming all the CPU and memory which would leave with nor resources expend on observability needs.
HOW
Correct the CPU/Memory requirements for the pods in question. We can take a look at the current usage over time and use the maximum plus some buffer of the historical data as the new limit. Make sure that the limits are reasonable for the node size.
- is duplicated by
-
MGDSTRM-9546 Ensure that all Observability Stack components have resource settings
-
- Backlog
-
