-
Epic
-
Resolution: Obsolete
-
 Normal
Normal
-
None
-
None
-
Customizable Observability in the MCO
-
To Do
-
OCPSTRAT-554 - Improving error handling, propagation, collection, and disambiguation for users
-
-
0% To Do, 0% In Progress, 100% Done
-
0
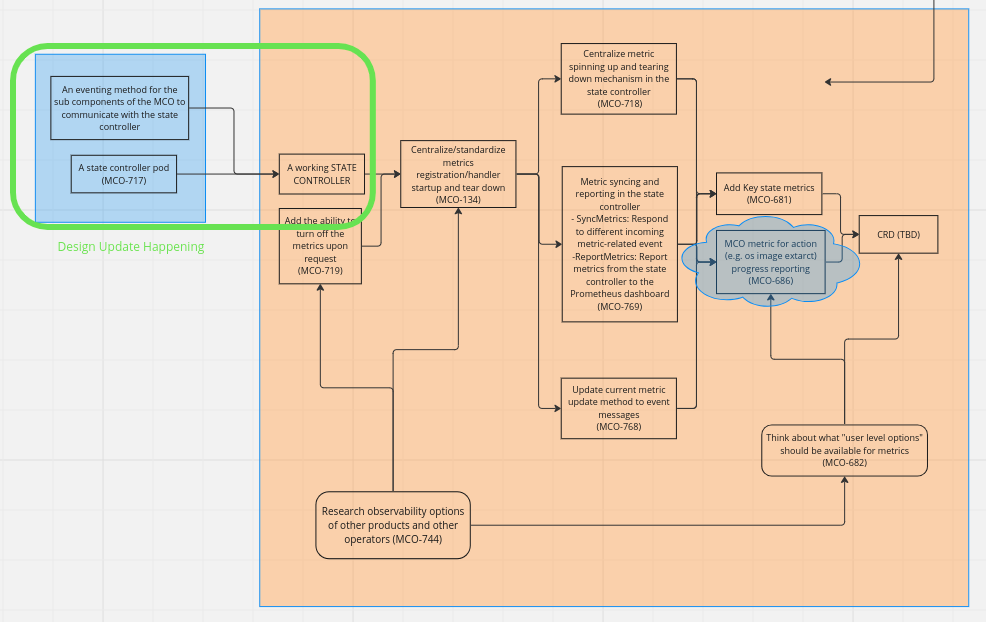
It became clear overtime that we need to enhance most of the MCO metrics that we have as well as adding more related to the MCC. The MCC is tasked with watching what's going on with pools and it makes sense to add more metrics and alerting especially there. There are various hiccups with metrics that we've been and are going through. This epic aims at addressing those and start working on adding more useful metrics/alerting to the MCO. Another aim for this epic would be (but we can split it out) to provide more data to help us proactively debug clusters when things go wrong.
There's a preliminary SPIKE attached to this epic (as well as more metrics related cards) that we'd need to hash out and refine first before moving on (the spike will help us to close/move/obsolete some of the attached cards perhaps)
MCO-1 Workflow:
{kind=link}
- clones
-
-
- Closed
-
- relates to
-
MCO-690 MVP: Implement StateController
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
MCO-134 Centralize/standardize metrics registration/handler startup and teardown
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-