-
Epic
-
Resolution: Done
-
 Critical
Critical
-
None
-
JSON Logs
-
Done
-
0% To Do, 0% In Progress, 100% Done
-
Goals
- Forward records to any output type that are valid JSON objects and contain the original JSON payload as a JSON object.
- Provide sufficient flexibility to combine JSON payloads and additional JSON metadata to suite common cases.
- Handle mixture of JSON and non-JSON log entries from the same source correctly.
- Allow multi-tenant querying for fields inside a JSON document from Kibana.
Non-Goals
- General-purpose JSON queries and transformations.
- Recording or validating user-defined schema. The forwarder only identifies indices by name.
- Support for nested JSON objects (objects inside an object) due to some Elasticsearch limitations for dynamic mapping.
- Individual rollover policies for the index related indices in Elasticsearch.
- Preserve JSON structure for logs generated by containers in a platform-related namespace (e.g. any openshift-*).
Motivation
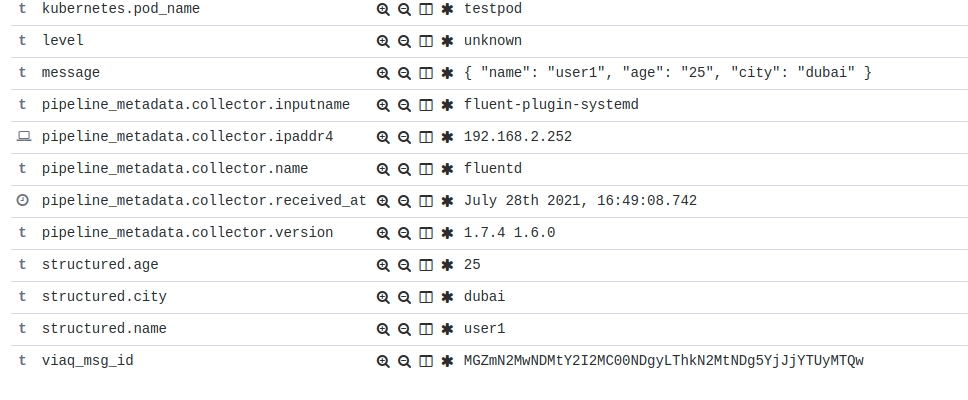
When applications write structured JSON logs, consumers want to access fields of JSON log entries for indexing and other purposes. The current logging data model stores the log entry as a JSON string, not a JSON object. Consumers can't access the log entry fields without a second JSON parse of this string. The current implementation also 'flattens' labels to work around Elasticsearch limitations.
Many customers have applications deployed on OpenShift (built by over 1.000 developers) that write their log messages in nested JSON format (e.g. by using log4j). They can't tell all their developers and change all their application to not do that anymore because we can't support them.
JSON, or structured logging, is probably the most common format used in the Java world and our inability to process and store those logs does not only impact our customers but also partners such as IBM Websphere. It will essentially lessen the value of our logging solution.
Alternatives
We do not process any JSON logs and customer always need to forward JSON type logs to a custom log normalizer (e.g. logstash) to do the parsing or use third party systems that allow you to parse incoming logs before they store it (e.g. DataDog).
Since JSON logs is not just an edge case but used by a majority of our customers in one way or the other, this alternative would lessen the need for our log solution and therefore the value we provide.
Acceptance Criteria
- Verify that parse only allows "JSON" or "json" and no other value.
- Verify that if parse is not defined in a pipeline, there is no structured field in the resulting log record.
- Verify that if you have structurdIndexKey AND structuredTypeName defined and the value for structuredTypeKey is empty or missing, use structuredTypeName as the index for the forwarded log record.
- Verify that structuredTypeKey always takes precedence over structuredTypeName if both are defined and the key is present on a record.
- Verify that if a record does not get assigned an index name by the structured... fields, then the resulting record has no structured field.
- Verify that with structuredTypeKey: kubernetes.namespaceName, the resulting record is sent to the index corresponding to the namespace.
- Verify that there is a corresponding index inside ES created to what is defined in the record.
- Verify that any new index is under the ES index management (specifically rollover).
- All new indices will be under the application source rollover policy. Therefore, what you configure there applies to all other "new" indices.
- Verify that you can query a specific field inside the JSON document through the Kibana UI.
- Verify that someone has not access to log messages coming from different namespaces but logged by the same application.
- Deploy the same application into two different namespaces.
- Add a app=myapp label to the related pods.
- Both should now log into the same index called myapp.
- User1 who only has access to namespace1 should not have access to the JSON logs from the other namespace even if both log records are colocated inside the same index.
- Verify that if you have multiple apps (e.g. 10) and only a subset (e.g. 2) are JSON logs, we only parse the subset and put them into their corresponding indices but the rest is not parsed and goes into the app index.
- We could setup multiple namespaces with multiple apps deployed. A small subset logs in JSON.
- Now we could configure a CLF CR and configure the input with parse: JSON without any filtering. At this point we try to validate everything that comes in.
- If the incoming message is not a valid JSON. We keep the message untouched and it goes to Elasticsearch which will put it into the app index (since the structured field is missing).
- If the incoming message is valid JSON, we parse and it goes into a separate ES index.
Risk and Assumptions
- Elasticsearch limitations for not standardized JSON schemas and nested objects inside the JSON message will continue to bring in problems. Even Elastic.co suggest to really try and standardize field and types, as well as avoid nested objects where they can. Here is an interesting read about the mapping conflicts https://www.elastic.co/blog/great-mapping-refactoring#conflicting-mappings. We try to workaround this by given users more choice to distribute common JSON schemas to their own indices.
Documentation Considerations
- See https://issues.redhat.com/browse/RHDEVDOCS-2677
- Explicitly highlight that although JSON logs go to a dedicated index, users will read them out from the app alias. Specifically important when creating index patterns in Kibana.
The following points caused confusion during the implementation, make sure to be clear in the docs:
- Final name for elasticsearch API fields: structuredTypeName, structuredTypeKey
- Don't call these "index" names, they are used to form the index name by adding 'app-' prefix.
- Emphasise that the structured type should identify JSON docs with different formats, it should not be used to identify applications, namespaces, users or any other type of group. Keep the number small.
- "app-" prefix is added to structured type to form index name, conforming to existing Elasticsearch index model.
- there is not (currently) any way to route logs to an index that is not named "app-...". May be a future feature.
Open Questions
Additional Notes
{kind=link}
- is documented by
-
RHDEVDOCS-2521 Document our JSON log entry format.
-
- Closed
-
-
-
- Closed
-
- is related to
-
-
- Closed
-
-
-
- Closed
-
- links to