-
Bug
-
Resolution: Done
-
 Major
Major
-
Logging 6.1.z, Logging 5.8.z, Logging 5.9.z, Logging 6.0.z, Logging 6.2.z, Logging 6.3.z
-
Incidents & Support
-
False
-
-
False
-
NEW
-
NEW
-
-
Bug Fix
-
-
-
Log Collection - Sprint 272, Log Collection - Sprint 273
-
Critical
-
Customer Escalated
Description of problem:
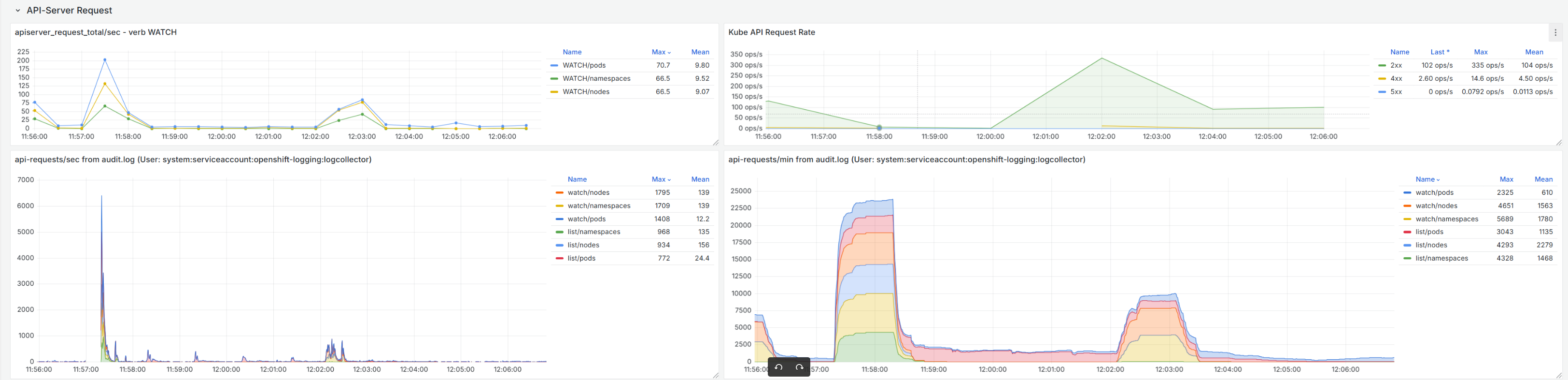
With the collector pods (Vector) restart, the control-plane is impacted going to unavailable as the number of requests to the API is highly increased for the requests received by the collectors when restarted. Better visibility is in the next dashboards:
Api requests:
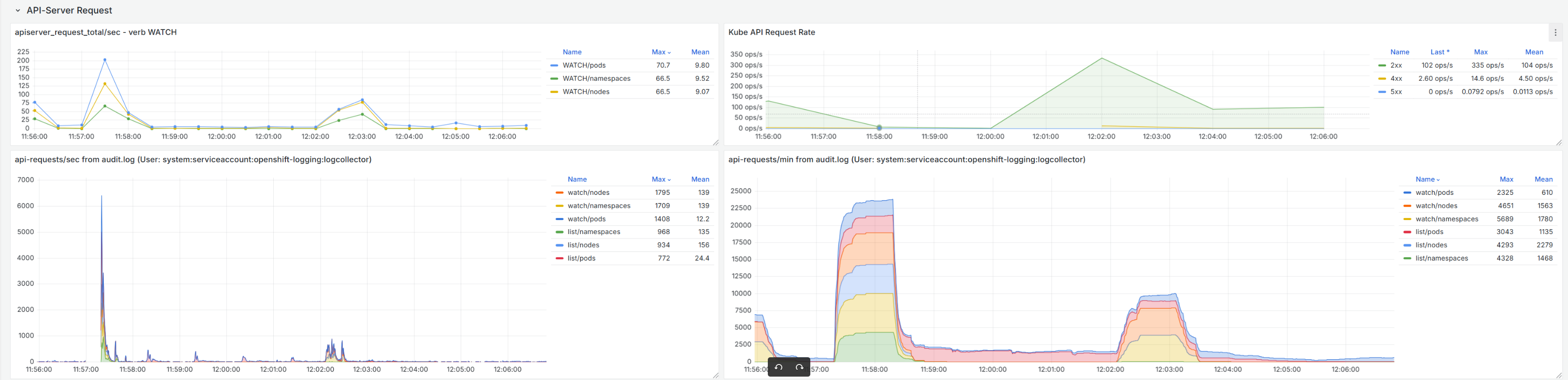
Cpu and memory usage in the control plane:

Version-Release number of selected component (if applicable):
How reproducible:
Every time that the collector pods are restarted manually or by the Logging Operator for applying any change
Some information:
$ oc get no --no-headers |wc -l 40 $ oc get po A -no-headers|wc -l 4162 $ oc get ns --no-headers|wc -l 473
Number of "inputs" in the clusterLogForwarder: 38
Steps to Reproduce:
In the environments affected, every time that restarted, the KubeAPI is impacted
Actual results:
The KubeAPI returns timeouts
Expected results:
The KubeAPI and control plane work normally and the restart of the collector pods don't impact in the control-planes (KubeAPI)
Data needed to collect:
- number of pods "oc get pods -A|wc -l"
- number of namespace "oc get ns|wc -l"
- Logging Operator version "oc get csv |grep -i logging"
- clusterLogForwarder
- Dashboard avaiable in "OpenShift Console > Observe > Dashboards > Dashboard: OpenShift Logging / Collection"
Possible workaround to test until the RCA is not found and resolved:
Move to Unmanaged the clusterLogForwarder CR. This will avoid to be restarted all the collector pods by the operator when a change in the Logging configuration is applied, but it will avoid:
- Update the Logging stack as the Operator won't consider to manage the resources
- Any update in the configuration won't be applied as the Logging Operator is not managing the resources
- causes
-
LOG-7535 Implement GA of kube-api server caching and configurable daemonset rollout strategy
-
- Closed
-
- is caused by
-
-

- Closed
-
- is cloned by
-
-
- Closed
-
-
-
- Closed
-
- links to
- mentioned on

{kind=link}
{kind=link}