-
Epic
-
Resolution: Done
-
 Critical
Critical
-
None
-
Content-based filtering
-
False
-
False
-
Green
-
NEW
-
Administer, API
-
To Do
-
OBSDA-228 - Log filtering and collecting
-
-
VERIFIED
-
0% To Do, 0% In Progress, 100% Done
-
-
Release Note Not Required
Goals
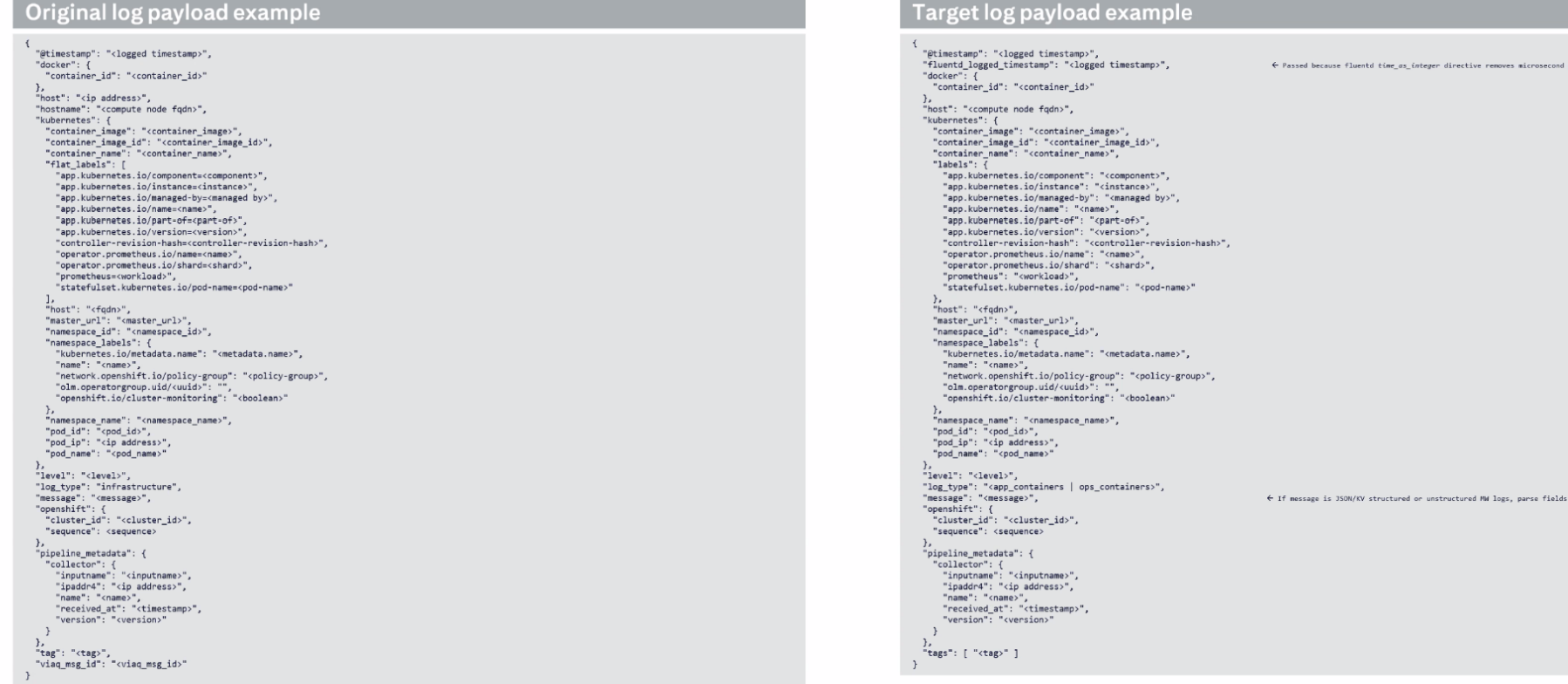
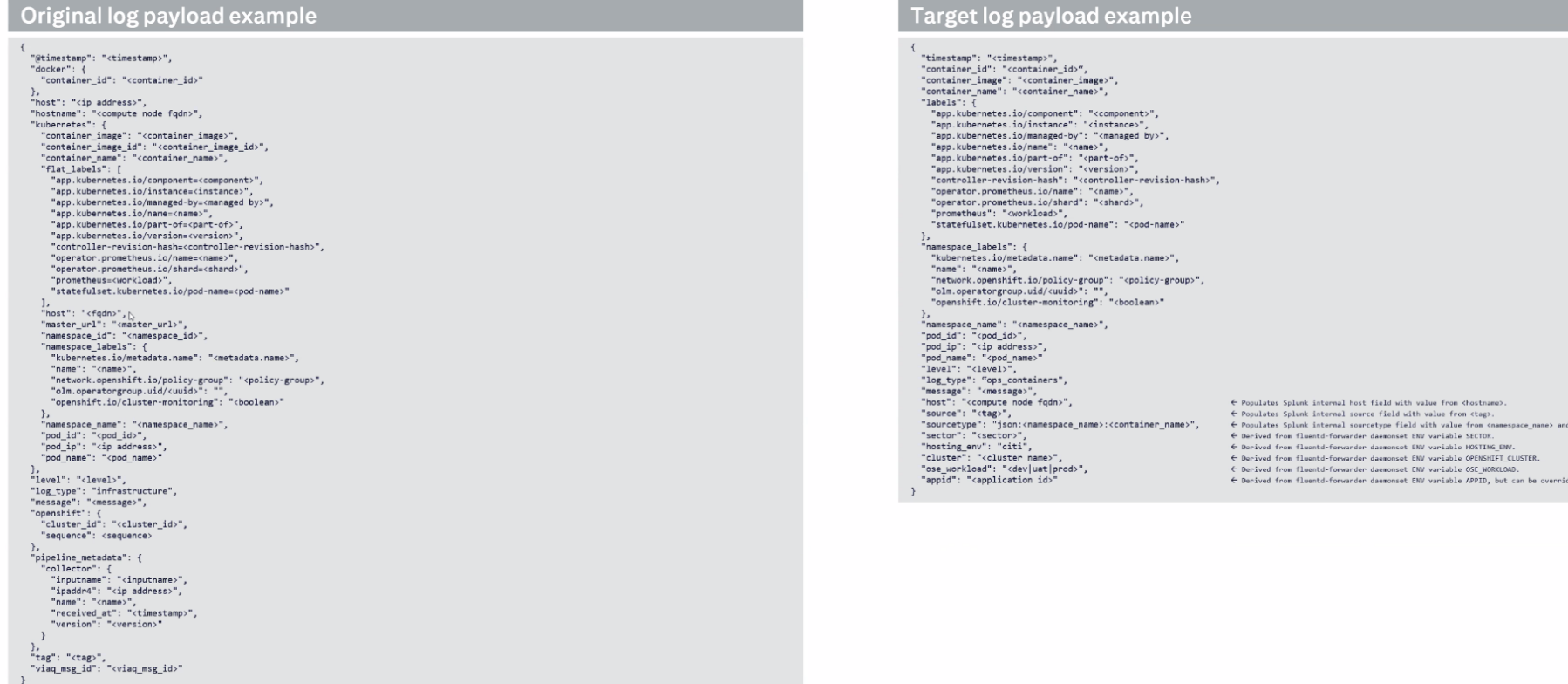
- Extend the forwarder input selector API to exclude log messages by message content and metadata, for example:
- Exclude logs from namespaces, pods or containers that match a name glob.
- Include or exclude logs from pods with a particular set of labels.
- Add filters to modify events based on message content:
- Ignore DEBUG level messages.
- Forward only CRITICAL level messages.
- Forward only logs with message matching a regular-expression.
It should be possible to combine content filtering with all existing message filtering/routing mechanisms, such as by namespace, k8s labels etc.
NOTE: some types of message "content" can be filtered more efficiently because they are constant for a given log file, and can be filtered by simply excluding that file from collection, for example:
- Namespace name, pod name, container name.
- Namespace or pod ID
- Pod labels
The implementation should eliminate log streams rather than analyze the content whenever possible - filters using metadata that is looked up once by the collector when it starts reading a stream can be used to eliminate the stream.
Non-Goals
- No transformation of log records, only filtering based on content.
Motivation
- Users need to route logs differently based on their content.
Alternatives
- Filter in some external service provided by the user, not supported by us
Acceptance Criteria
- Tests to verify types of filtering as described by each of the stories in this epic.
Risk and Assumptions
Possible risks:
- CPU, memory cost at the collector.
- Negative performance (throughput, latency) on collector for filtering on message content.
Documentation Considerations
See stories.
Open Questions
This epic could be split in two: static filters that eliminate a stream vs. filters that require matching the messages. Even if it is, we need a consistent API for both types of filter.
Additional Notes
TODO
- blocks
-
OBSDA-228 Log filtering and collecting
-

- Closed
-
- incorporates
-
-

- Closed
-
- is depended on by
-
-
- Closed
-
- is documented by
-
OBSDOCS-821 [DOC] Filter log messages based on metadata and content.
-

- Closed
-
- is duplicated by
-
-
- Closed
-
-
-
- Closed
-
- links to