-
Bug
-
Resolution: Done
-
 Major
Major
-
3.2.0.GA, 3.3.0.GA
-
False
-
-
False
-
Release Notes
-
-
Bug Fix
-
Done
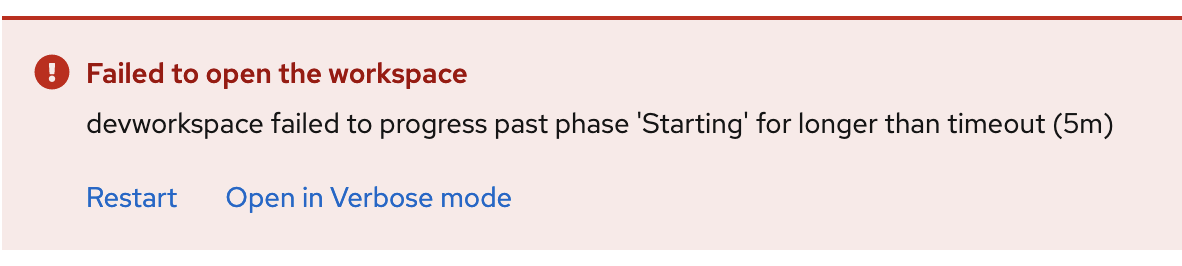
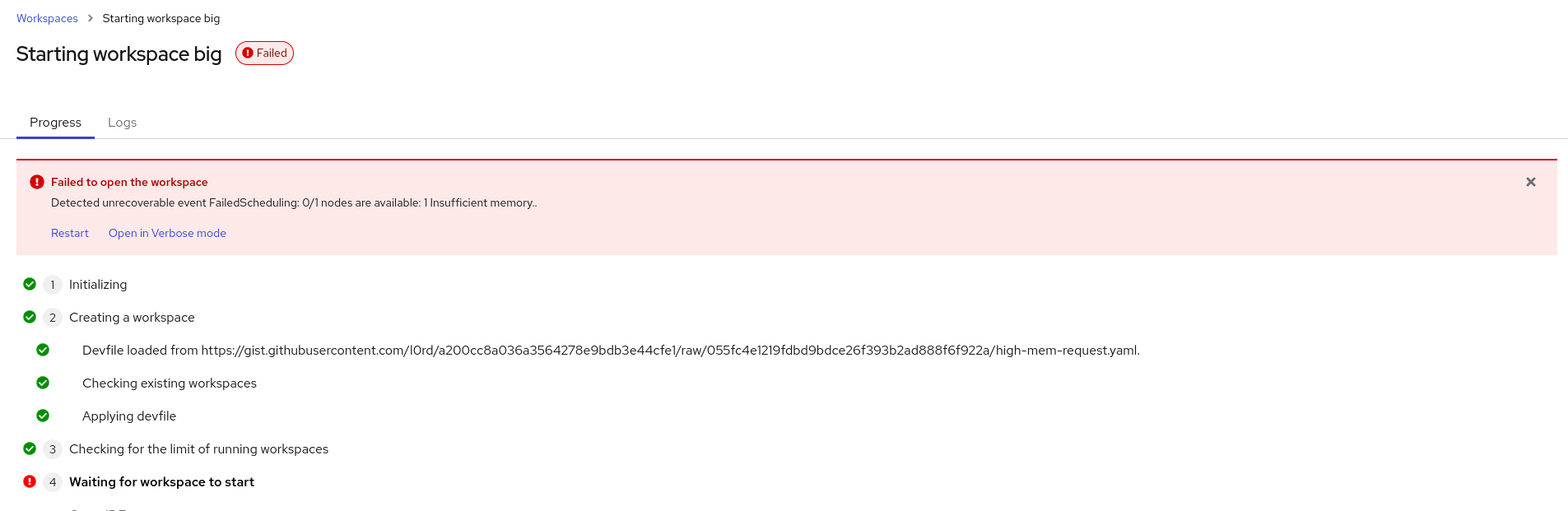
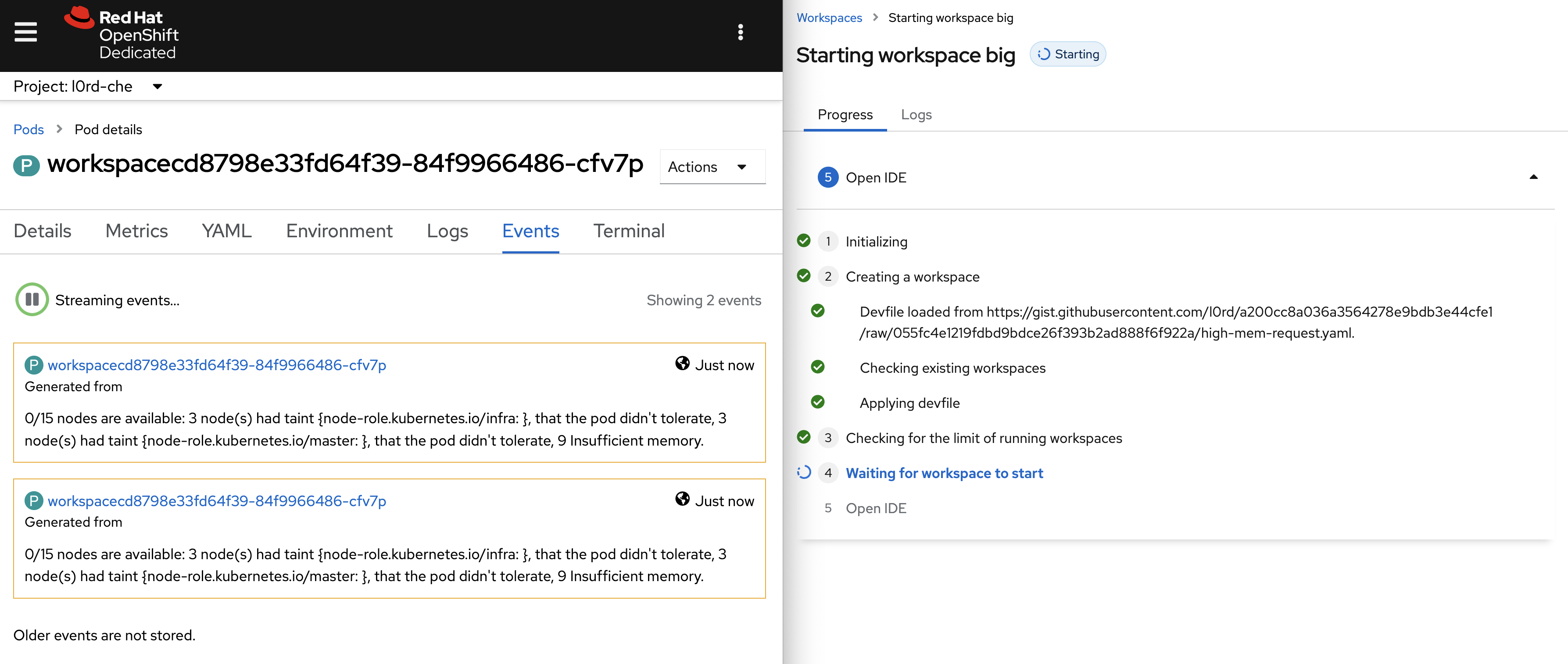
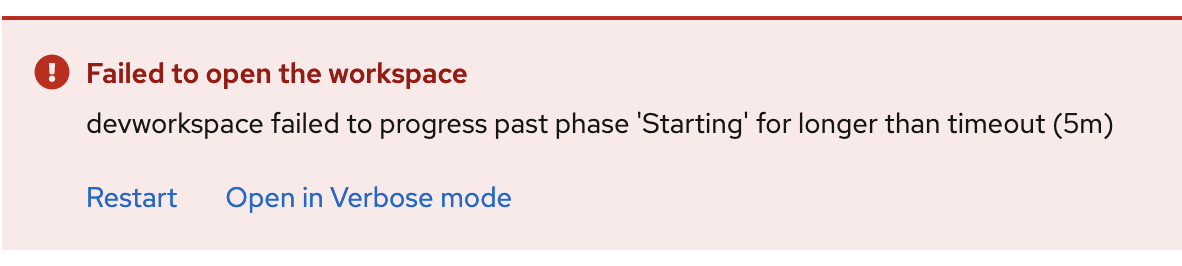
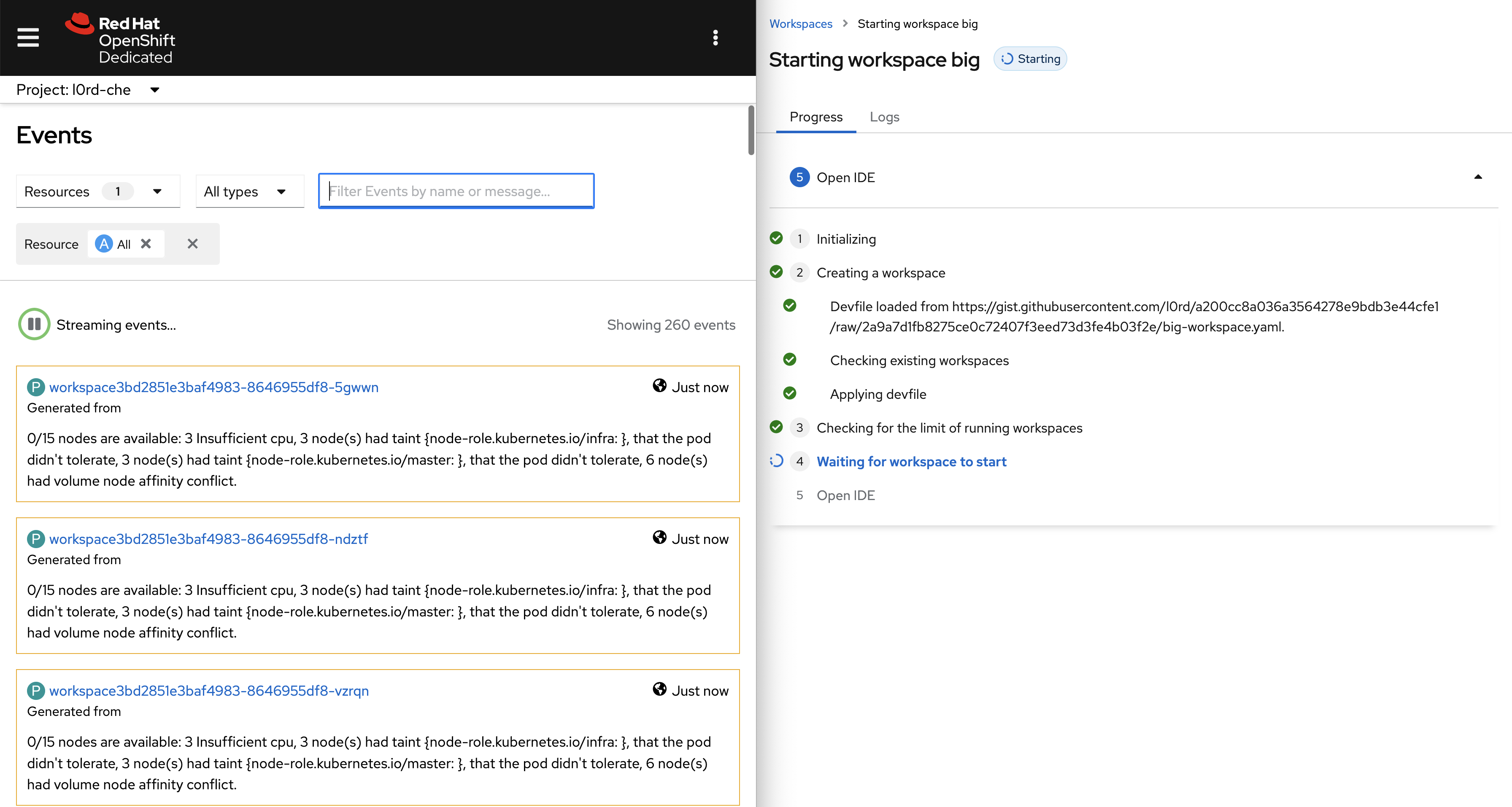
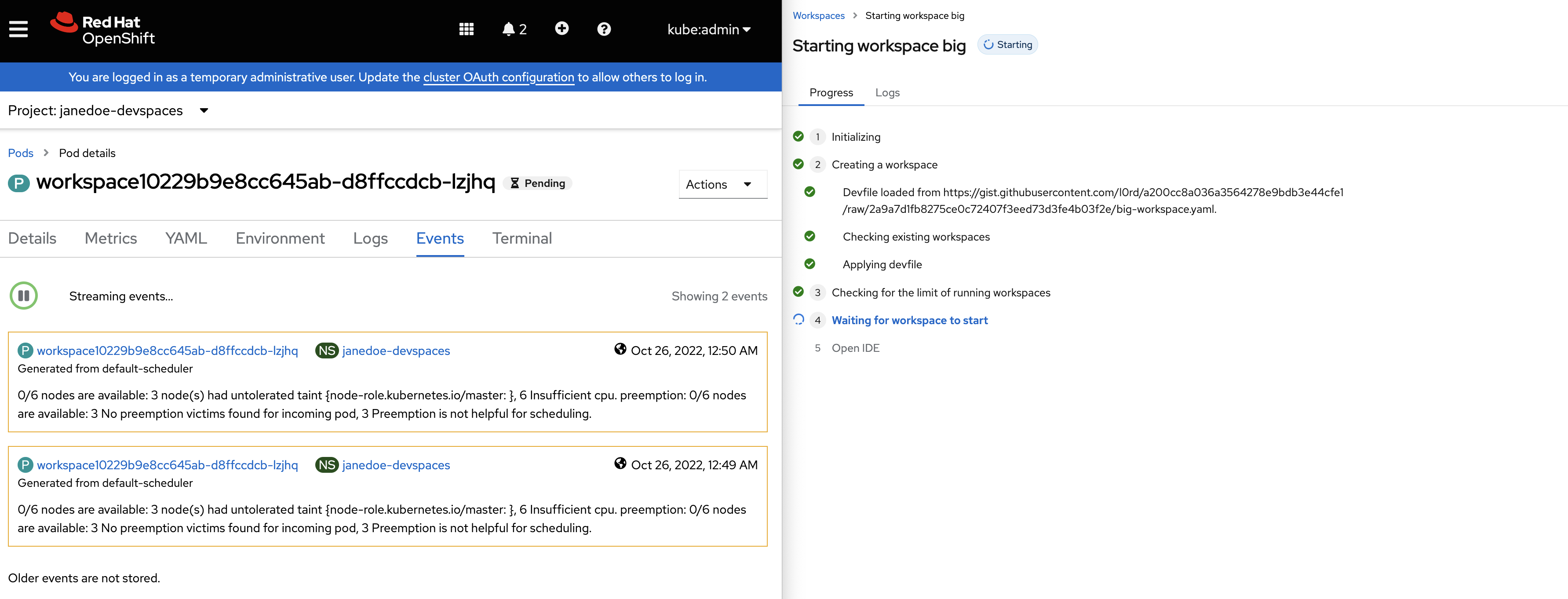
When the CPU or the memory requested to start a workspace are higher than the maximum available CPU in the cluster nodes, the scheduler fails right away. But the Dev Spaces user is notified only after the workspace startup timeout (5 minutes) and the message doesn't provide any clue about the origin of the problem.
Here are two devfiles:
- one to reproduce the insufficient CPU problem (link to reproduce it on the dogfooding instance).
- one to reproduce the insufficient memory error (link to reproduce it on the dogfooding instance).
Some screenshots:
Insufficient CPU on a Dev Spaces 3.3 instance with ?che-editor=che-incubator/che-code/insiders:
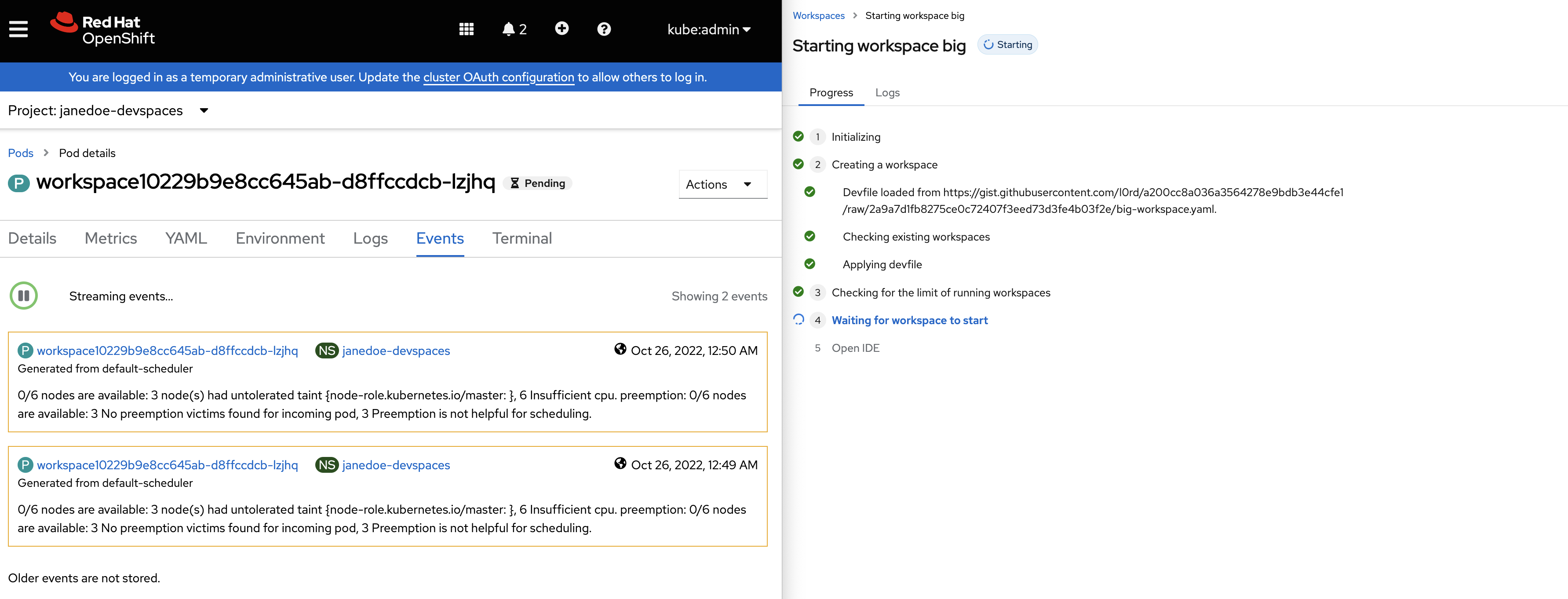
Insufficient CPU on the dogfooding cluster:
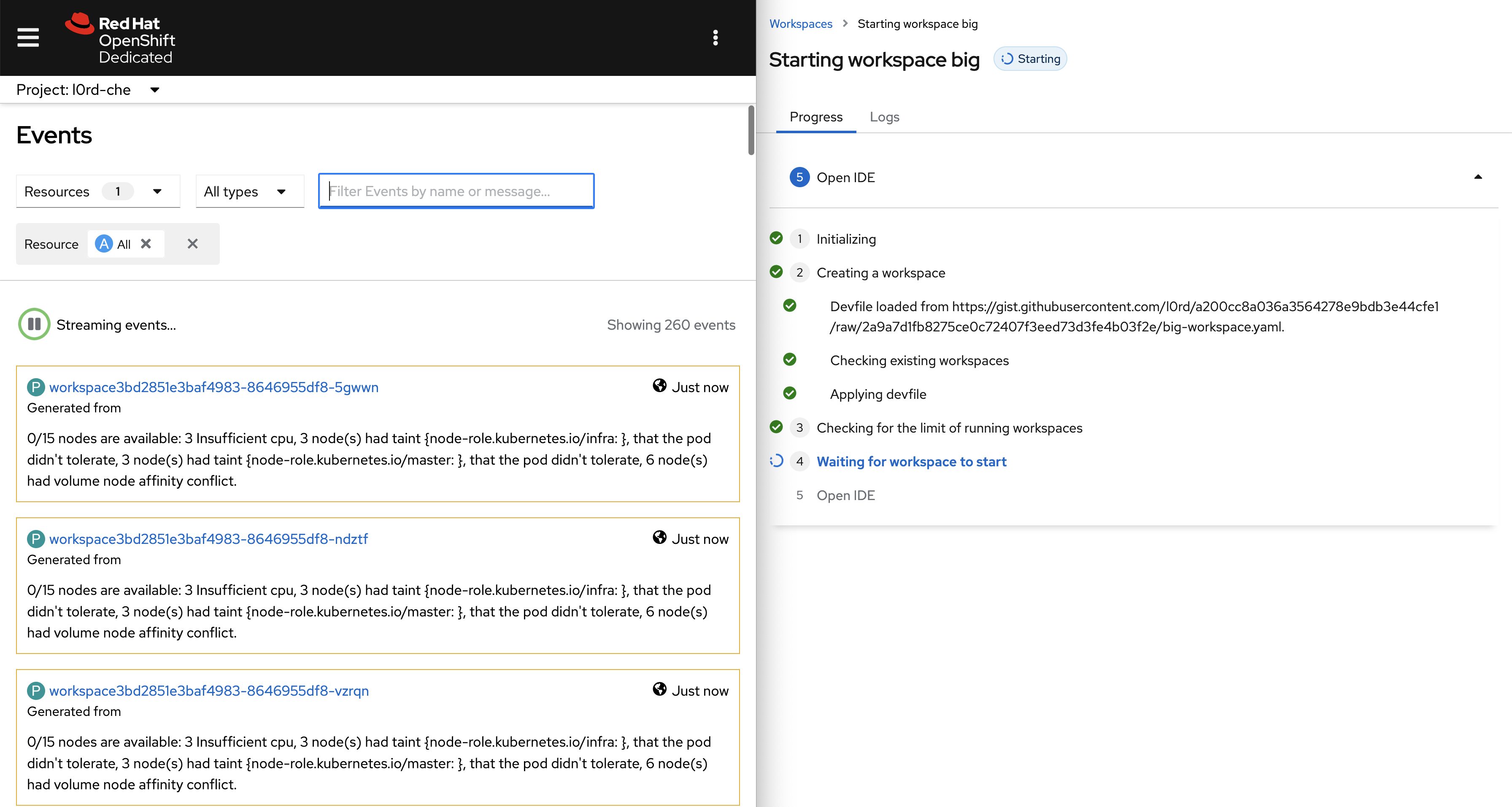
Insufficient memory on the dogfooding cluster:
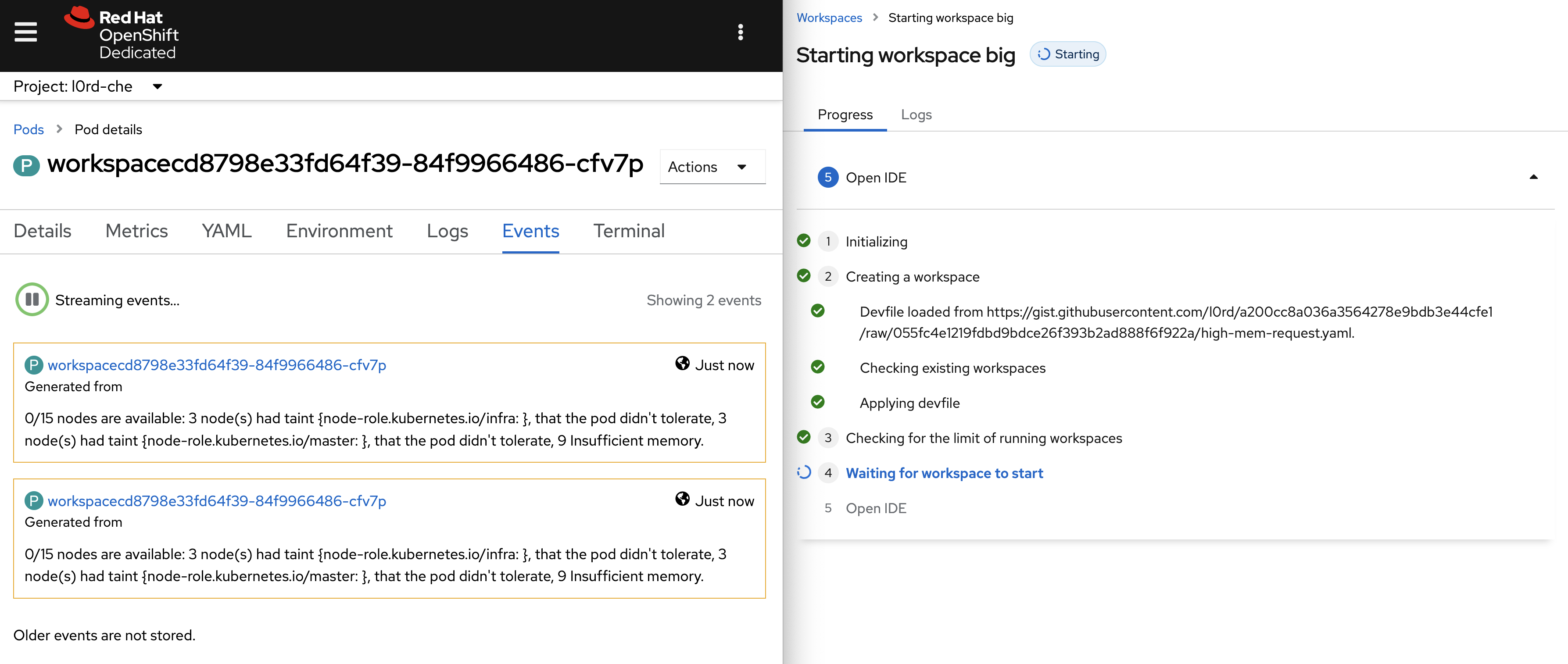
In all cases the workspace fails to start after 5 minutes:
- relates to
-
-

- Closed
-
- links to
