Details
-
Story
-
Resolution: Done
-
 Critical
Critical
-
None
-
None
-
5
-
False
-
False
-
Undefined
-
Workloads Sprint 201, Workloads Sprint 202, Workloads Sprint 203
Description
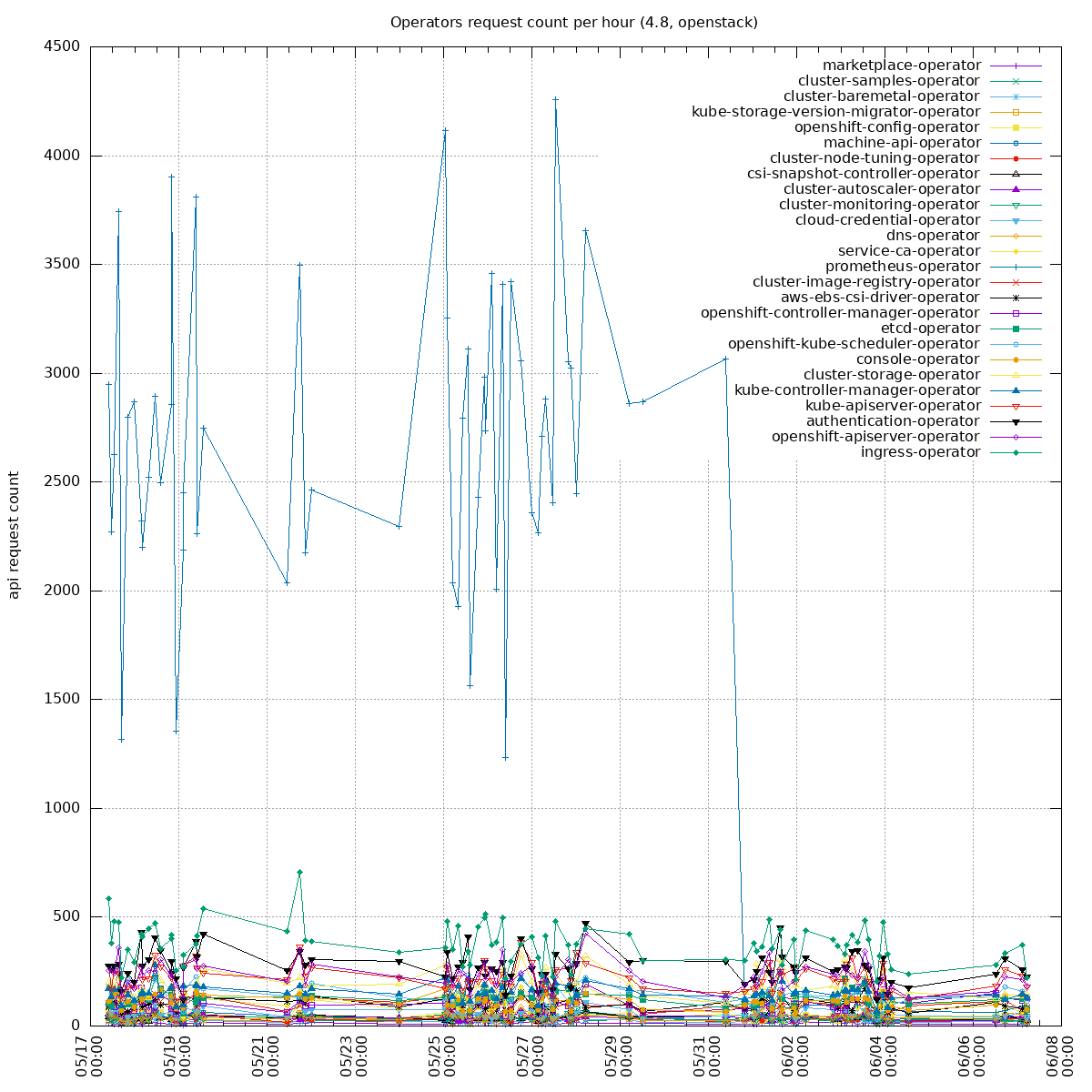
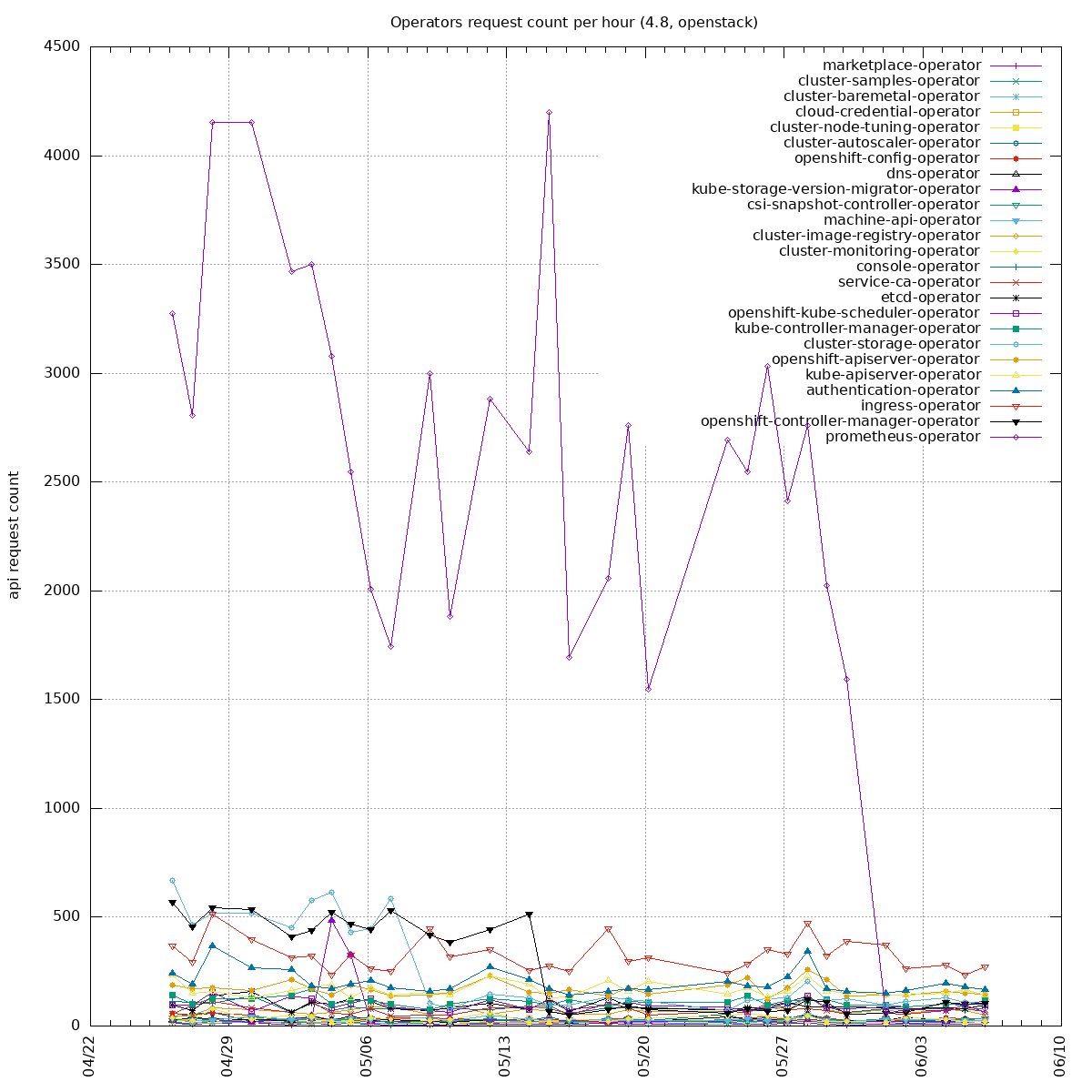
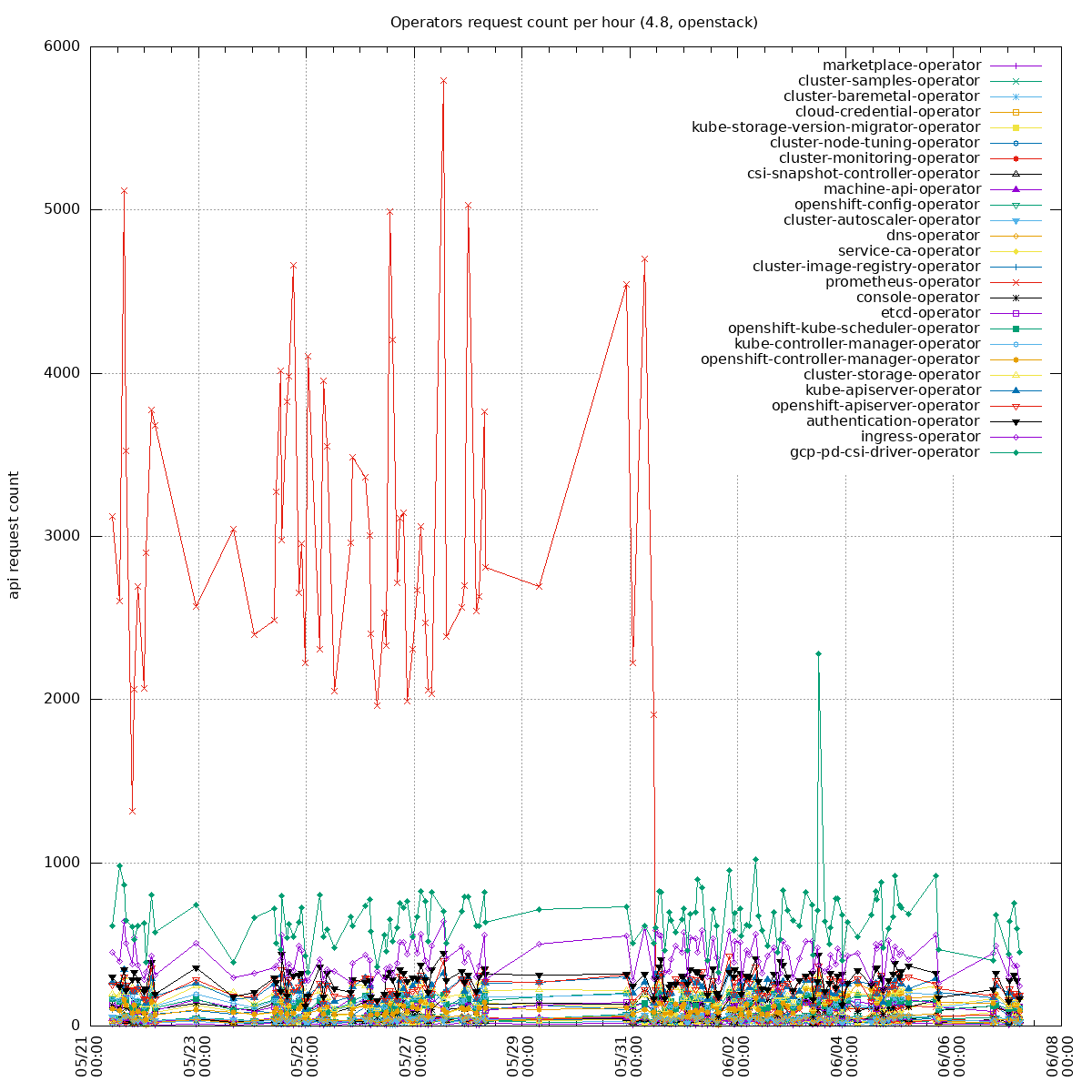
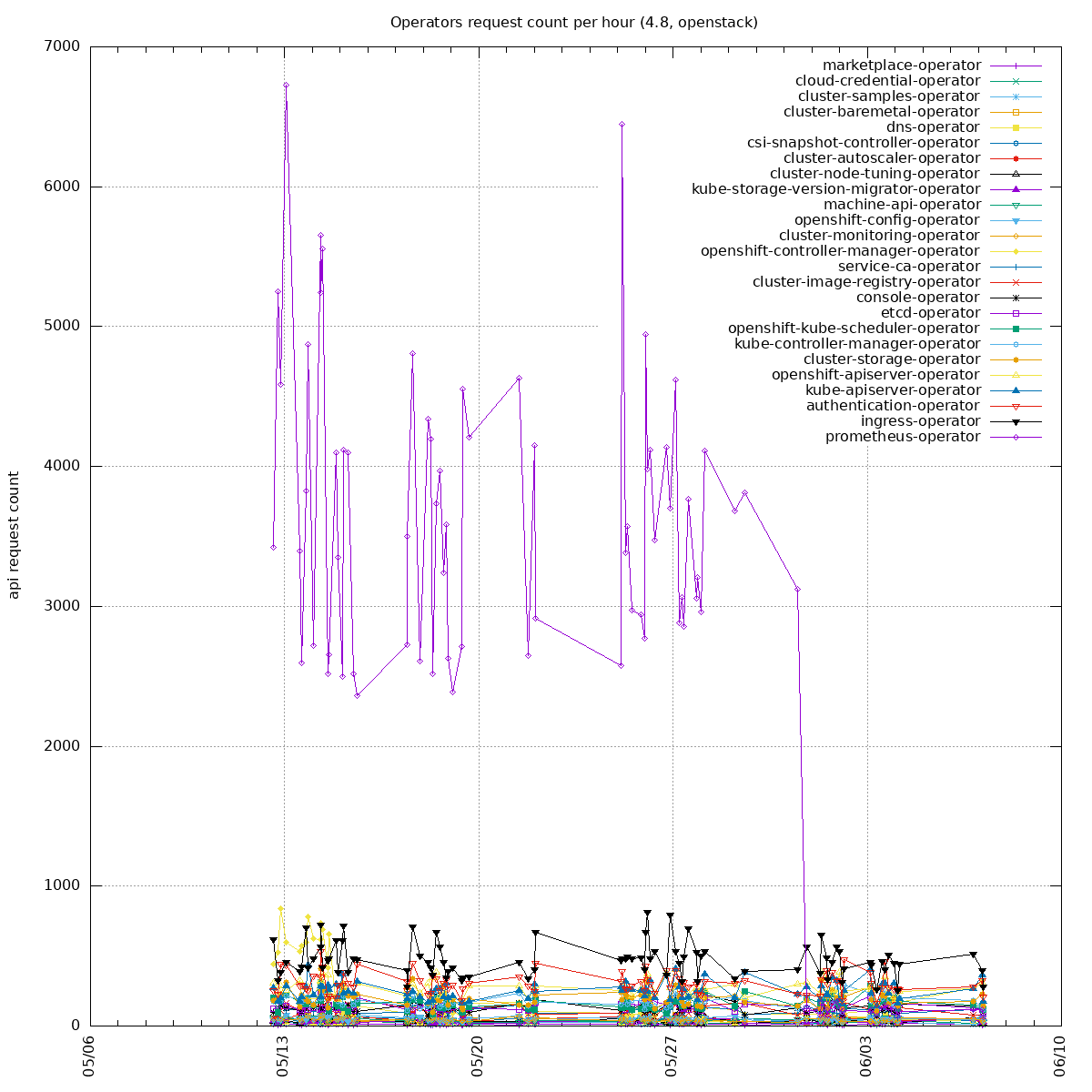
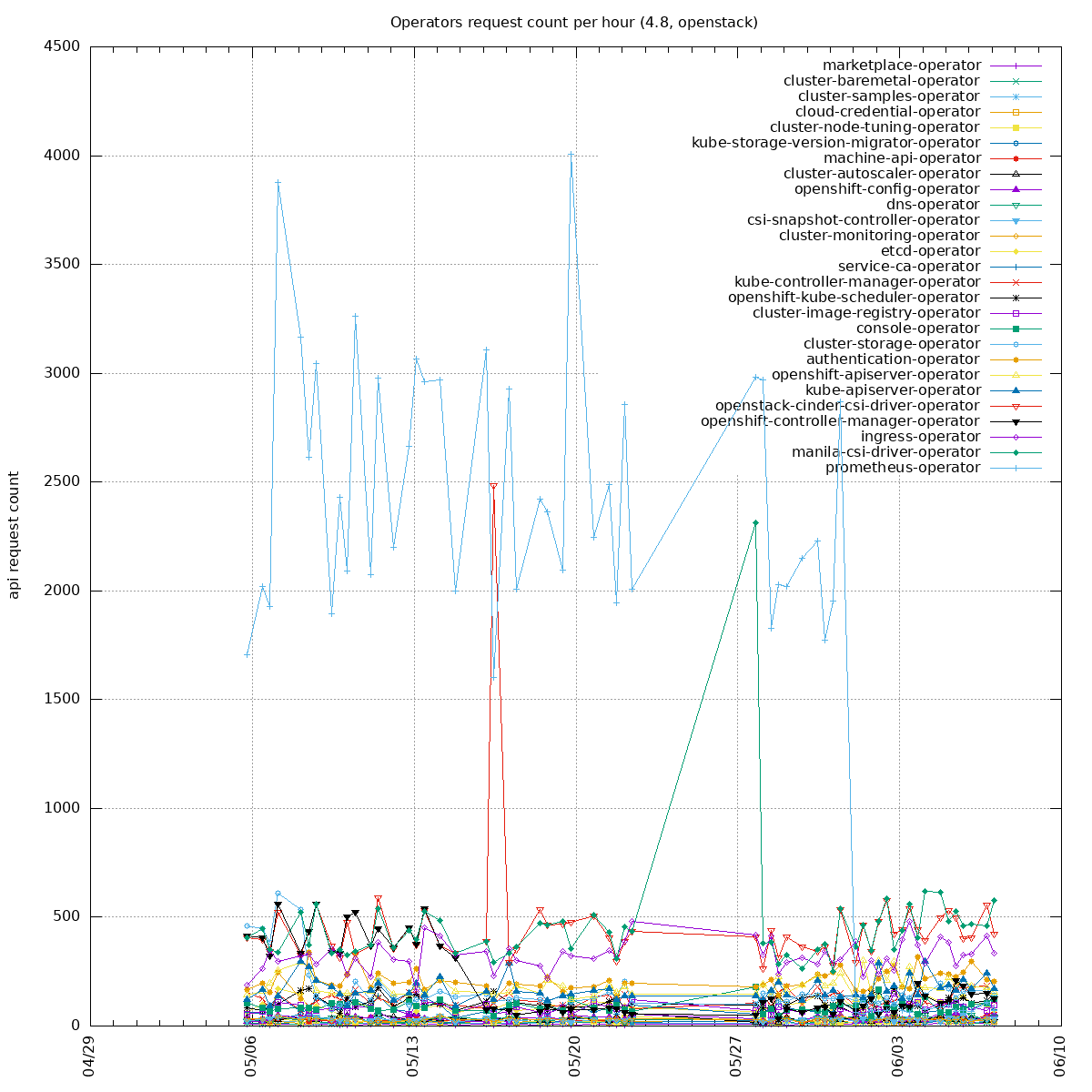
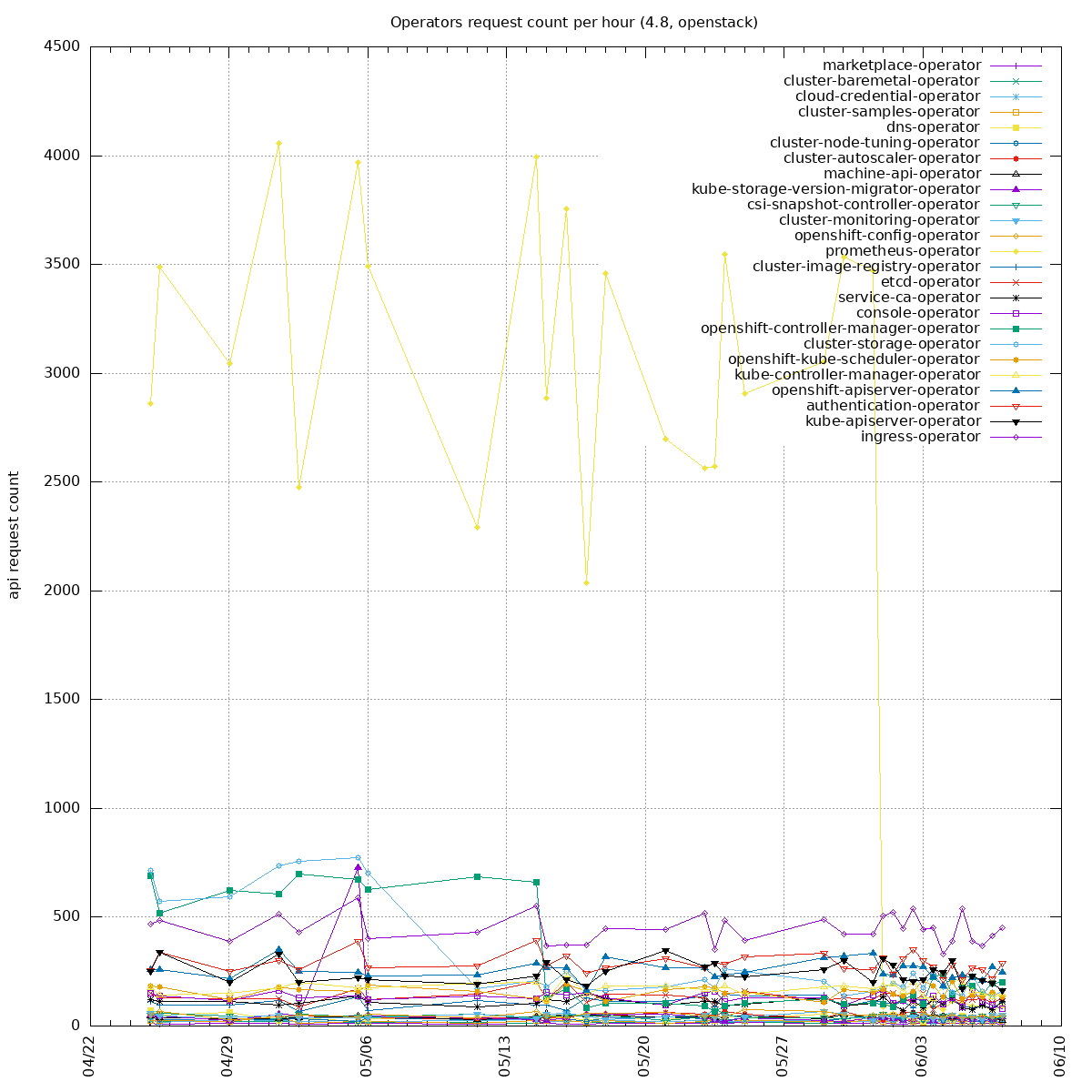
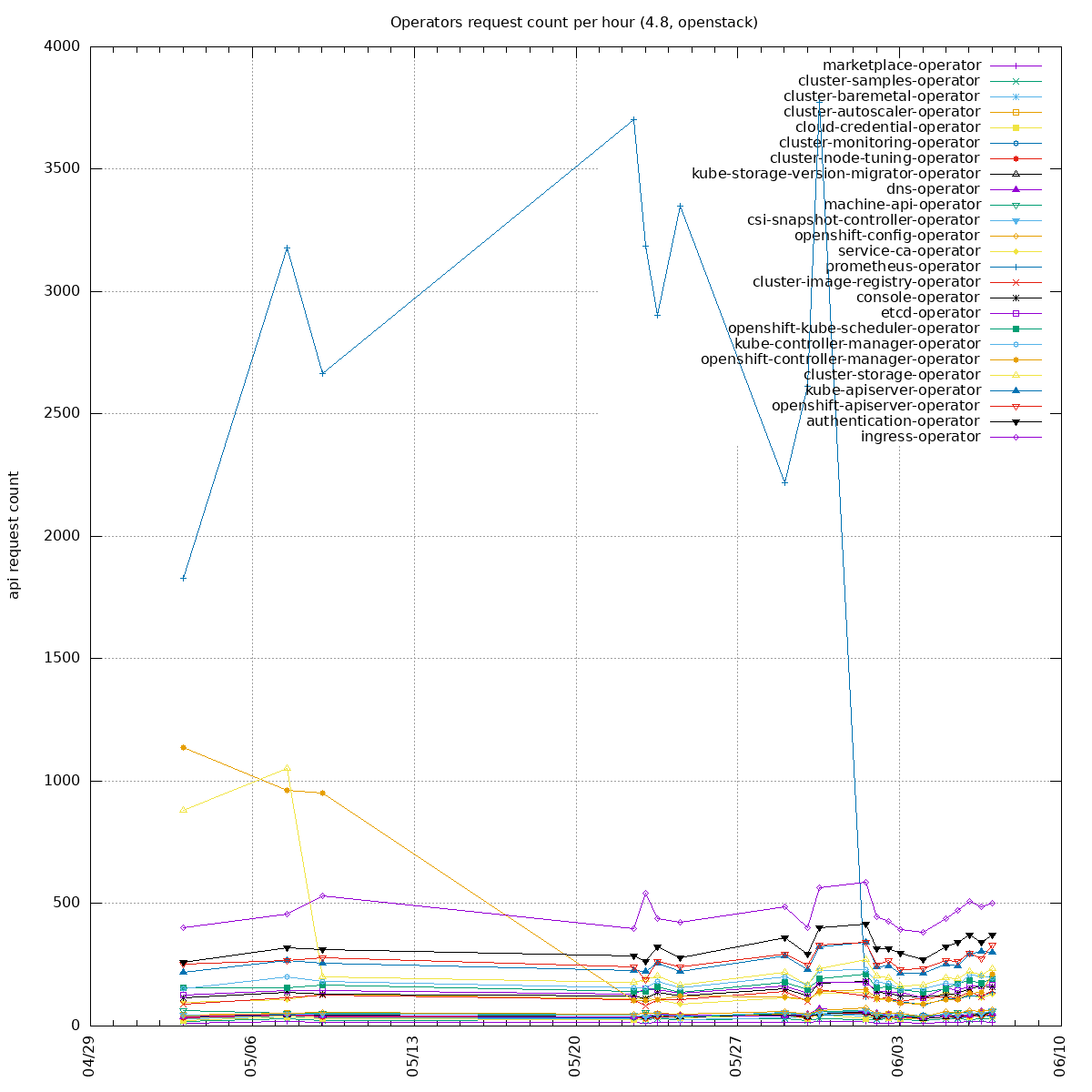
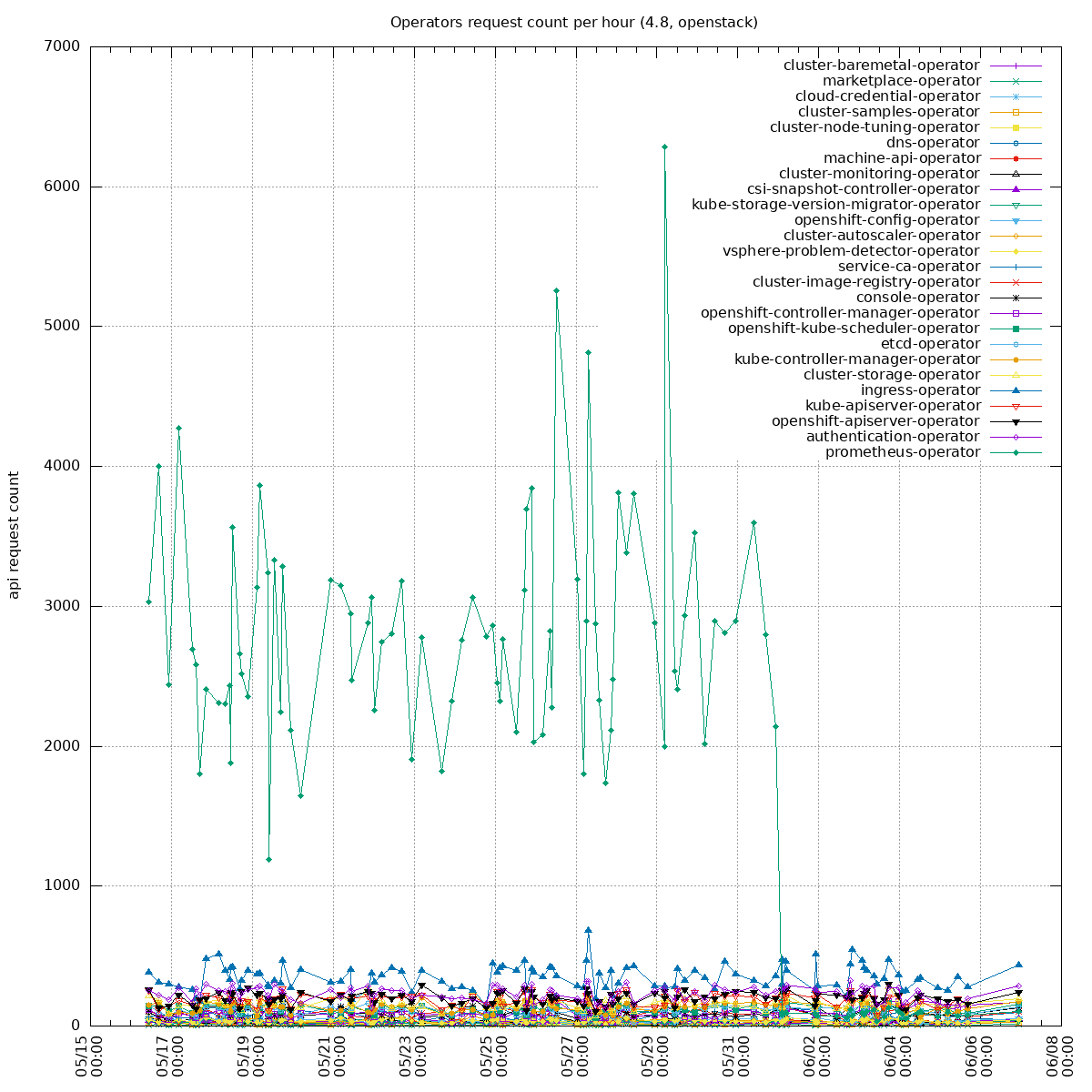
Two sides of the issue:
- clients unable to handle "too many requests": https://github.com/kubernetes/kubernetes/pull/100878 PR merged, backport to o/k: https://github.com/openshift/kubernetes/pull/669, not yet in 1.21 so we can not backport it into our client-go yet
- some watchers in our operators are recreating watchers too often (e.g. every 10s instead of 10 minutes): the goal is to update our operators to re-create the watchers less often. Example PR: https://github.com/openshift/cluster-storage-operator/pull/165
To get the biggest watch offenders, one can run:
```
$ /kubectl-dev_tool audit -f /home/jchaloup/Projects/src/github.com/openshift/installer/must-gather/audit_logs/kube-apiserver/audit.log -otop=50 --verb=watch --by=user
had 1 line read failures
count: 44948, first: 2021-05-11T09:48:47+02:00, last: 2021-05-11T11:43:20+02:00, duration: 1h54m32.592105s
7391x system:serviceaccount:openshift-monitoring:prometheus-operator
4398x system:serviceaccount:openshift-operator-lifecycle-manager:olm-operator-serviceaccount
3644x system:serviceaccount:openshift-monitoring:prometheus-k8s
2704x system:kube-controller-manager
2000x system:serviceaccount:openshift-cluster-csi-drivers:aws-ebs-csi-driver-operator
1950x system:serviceaccount:openshift-controller-manager-operator:openshift-controller-manager-operator
1909x system:node:ip-10-0-166-5.ec2.internal
1770x system:node:ip-10-0-132-124.ec2.internal
1745x system:node:ip-10-0-147-213.ec2.internal
1217x system:node:ip-10-0-170-41.ec2.internal
1101x system:node:ip-10-0-143-23.ec2.internal
1098x system:serviceaccount:openshift-ingress-operator:ingress-operator
...
```