-
Story
-
Resolution: Done
-
 Minor
Minor
-
None
-
None
-
None
-
False
-
-
False
-
None
-
None
-
None
-
None
-
None
The symptom is shown in these logs in this step:
Creating new realtime tuned profile on cluster tuned.tuned.openshift.io/worker-rt created waiting for mcp/worker condition=Updating timeout=5m machineconfigpool.machineconfiguration.openshift.io/worker condition met waiting for mcp/worker condition=Updated timeout=30m error: timed out waiting for the condition on machineconfigpools/worker
The symptom occurs on the "periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade" job. We did not observe this symptom happening in other jobs.
This problem started happening on this payload: 4.14.0-0.nightly-2023-04-20-231721 (OS version 414.92.202304201926-0)
The previous payload does not have the problem: 4.14.0-0.nightly-2023-04-19-224500 (OS version 414.92.202304172216-0)
This is a problem blocking 4.14 nightly payloads.
Note the bump in rhcos:
414.92.202304201926
414.92.202304172216
The jobs showing the symptom fail after less than 1.5 hours; jobs that get past the problem fail after (usually) above 2.5 hours.
Here's an aggregated job where all 10 jobs showed the symptom (click on "job-run-summary for aggregated") and you'll see:
periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191289897357312 failure after 1h30m46s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191290732023808 failure after 1h33m26s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191292409745408 failure after 1h23m44s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191293248606208 failure after 1h25m31s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191294104244224 failure after 1h27m14s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191295811325952 failure after 1h27m33s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191296658575360 failure after 1h29m32s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191297480658944 failure after 1h21m35s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191298294353920 failure after 1h22m14s periodic-ci-openshift-release-master-ci-4.14-upgrade-from-stable-4.13-e2e-gcp-ovn-rt-upgrade/1649191299133214720 failure after 1h21m6s
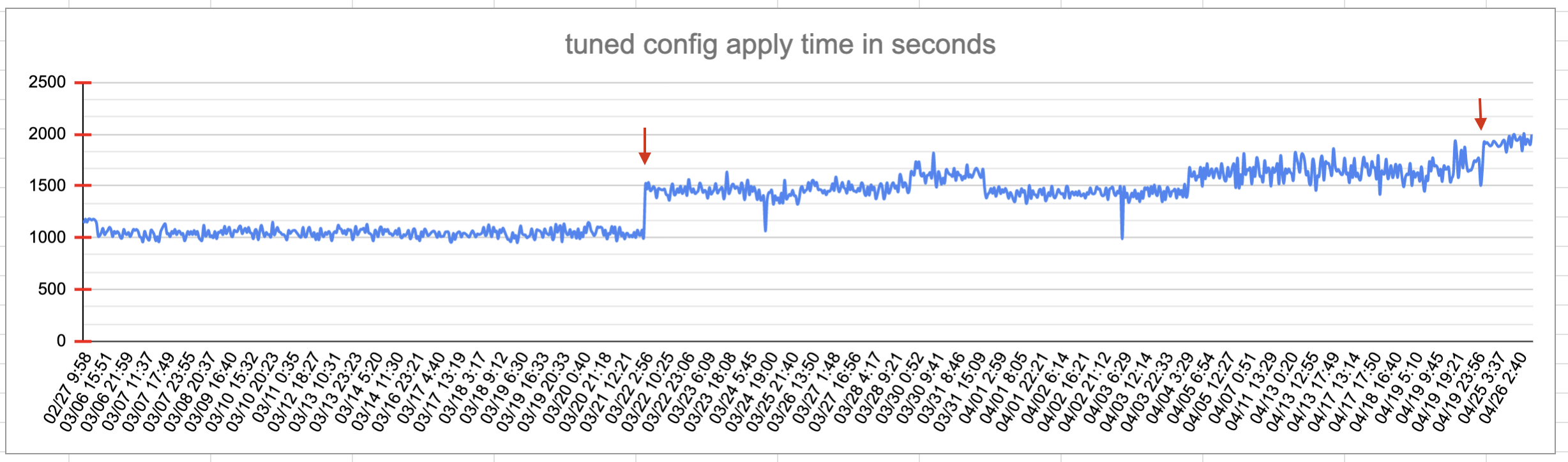
The step above is trying to apply a tuned configuration and waiting up to 30m for the configuration to be applied. Sometimes the configuration change is not finished before the timeout.
Here's a job showing the symptom.
Here's a job not showing the symptom
We looked in the "openshift-cluster-node-tuning-operator_tuned" and "openshift-cluster-node-tuning-operator_cluster-node-tuning-operator-58f85646cd-8hdsq_cluster-node-tuning-operator" logs.
We also looked at toplevel build-log.txt files in prow jobs for cases where the symptom occurs and not. We observed that the time it takes to apply the tuned config close to 30m which might explain why this is intermittent.
At this point, we are testing what happens if we increase the timeout in this PR. But we don't know why it's taking longer than before.
(update Apr 26, 2023): the timeout increase helps, the PR is merged and the test failures related to this are no longer there. At this point, the urgency of this drops but we can leave it open to keep the investigation going as to the reason for the slowdown.
{kind=link}