-
Story
-
Resolution: Won't Do
-
 Major
Major
-
None
-
None
-
None
-
None
-
False
-
-
False
-
None
-
None
-
None
-
None
-
None
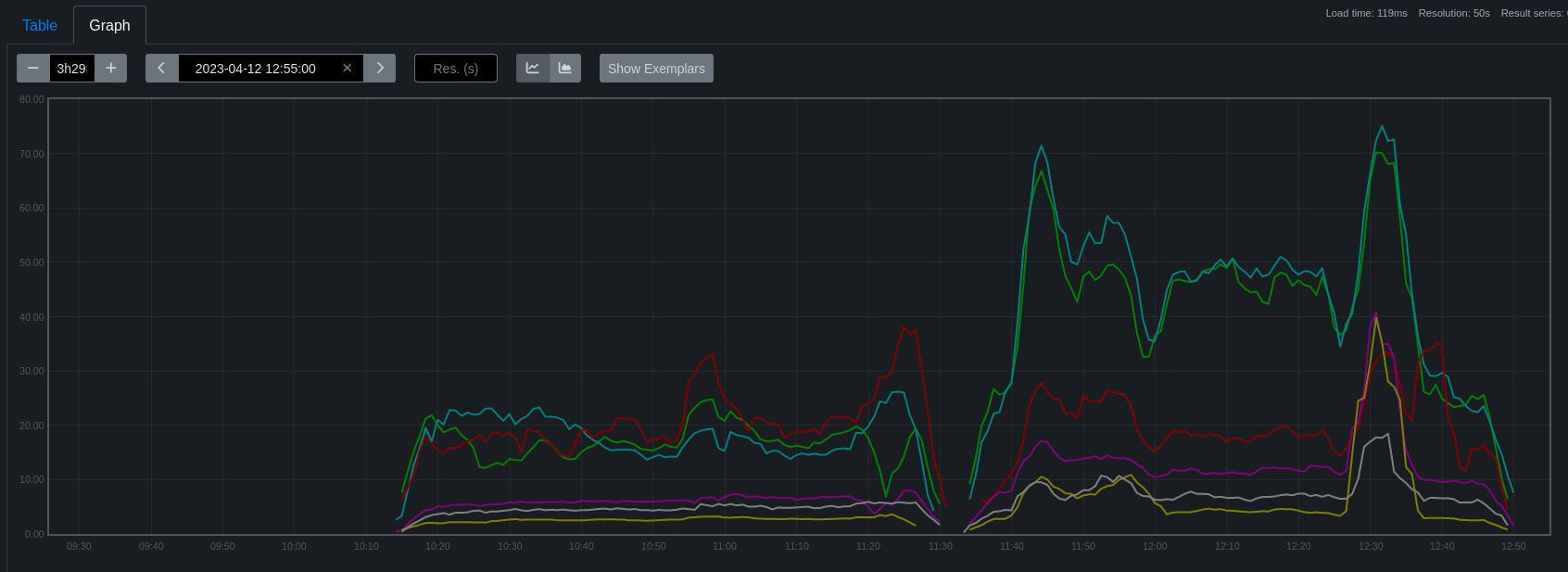
As fallout from OCPBUGS-11591 we want to deploy an alert in CI clusters (not in the product at this point) for high CPU use on workers.
Ryan from Node team has provided the following promql which should give insight into pod/namespace granularity of the problems:
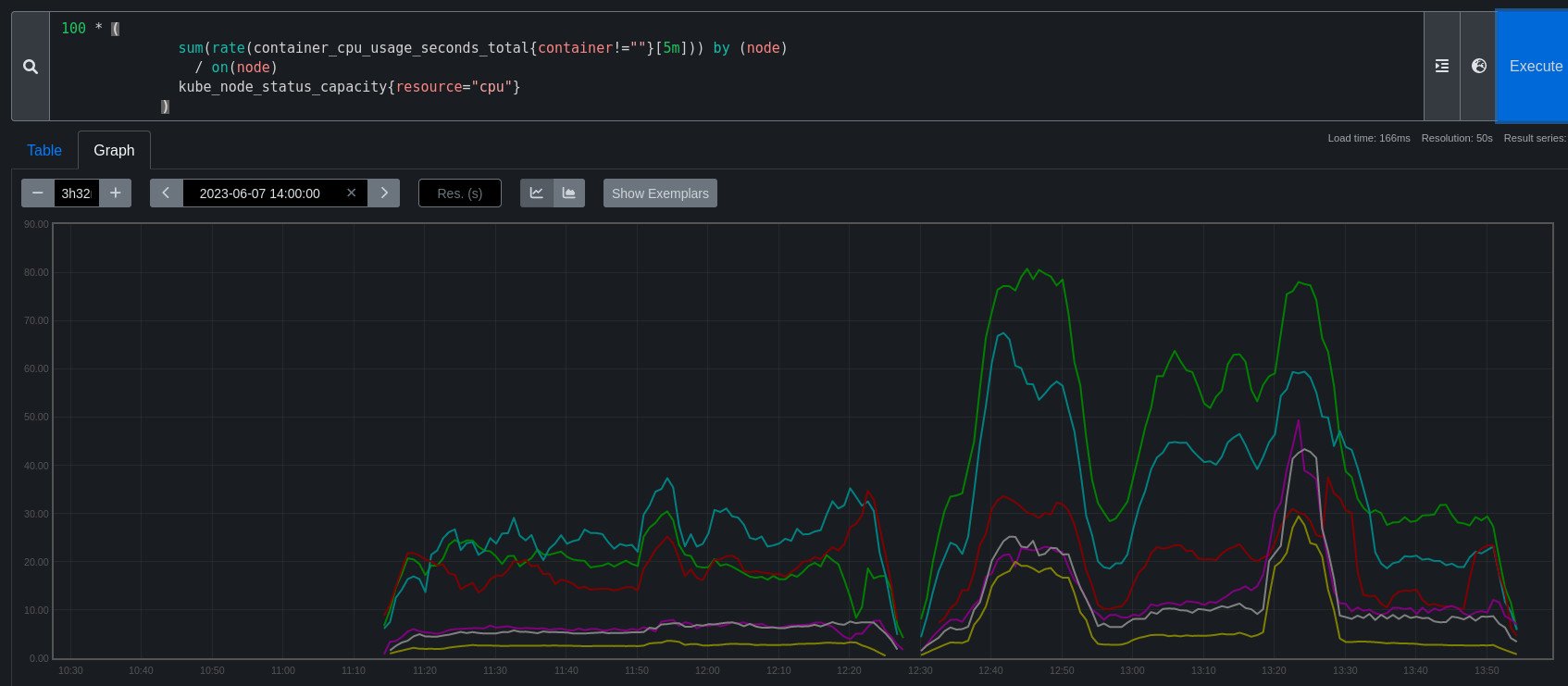
100 * (
sum(rate(container_cpu_usage_seconds_total{container!=""}[5m])) by (node)
/ on(node)
kube_node_status_capacity{resource="cpu"}
)
Or:
sum(rate(container_cpu_usage_seconds_total{}[5m])) by (pod)
First experiment with these promql queries in promecius on past runs, perhaps the bad runs from the parent bug. Determine when we think we should alert.
Then we need to find a way to deploy an alert into CI clusters during ipi installs, this should be quite global across the fleet.

- is related to
-
OCPBUGS-11591 Mass sig-network test failures on GCP OVN
-

- Closed
-
