-
Bug
-
Resolution: Unresolved
-
 Undefined
Undefined
-
None
-
None
-
False
-
None
-
False
-
-
Description of problem:
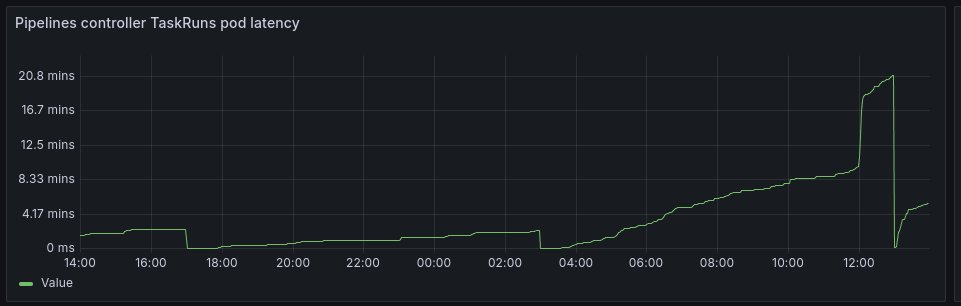
The tekton_pipelines_controller_taskruns_pod_latency_milliseconds metric - as configured with TektonConfig defaults - returns a Prometheus "instant vector". This significantly limits the usability of this metric - Prometheus can only aggregate with `sum`, `max`, `min`, and other aggregators that produce scalar outcomes.
Workaround: None
Prerequisites (if any, like setup, operators/versions):
- OpenShift Pipelines 5.0.5-492 on OCP 4.15
- Deploy with Prometheus monitoring enabled.
Steps to Reproduce
- Deploy OpenShift Pipelines v5.0.5-492, with Grafana
- Set up a Grafana or other visualizer to plot an aggregated view of the tekton_pipelines_controller_taskruns_pod_latency_milliseconds
Actual results:
Cannot use `rate` - it appears that the latency milliseconds is not reported as a Prometheus counter.
Expected results:
Pod (schedule) latency is reported with a counter metric (or equivalent from a histogram) so that we can observe rates over time
Reproducibility (Always/Intermittent/Only Once):
Always
Acceptance criteria:
Definition of Done:
Build Details:
OpenShift Pipelines 5.05-492
OpenShift 4.15.31
Additional info (Such as Logs, Screenshots, etc):