-
Task
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
Quality / Stability / Reliability
-
True
-
-
False
-
5
-
3
-
None
-
None
-
OpenShift SPLAT - Sprint 275
User Story:
As an OpenShift Engineer I want to report and propose investigation on CI of jobs randomly getting OOMKilled by Prow, impacting the feature readiness, so that we can increase velocity and confidence on features proposed to upstream cloud-provider-aws
Description:
< Record any background information >
- e2e job which is frequently OOMKilled so . Refs <https://kubernetes.slack.com/archives/C7J9RP96G/p1754511876402269?thread_ts=1754505741.634999&cid=C7J9RP96G>.
- cloud-provider-aws (upstream) CI information https://github.com/kubernetes/cloud-provider-aws/blob/master/docs/development.md#ci-test-infrastructure
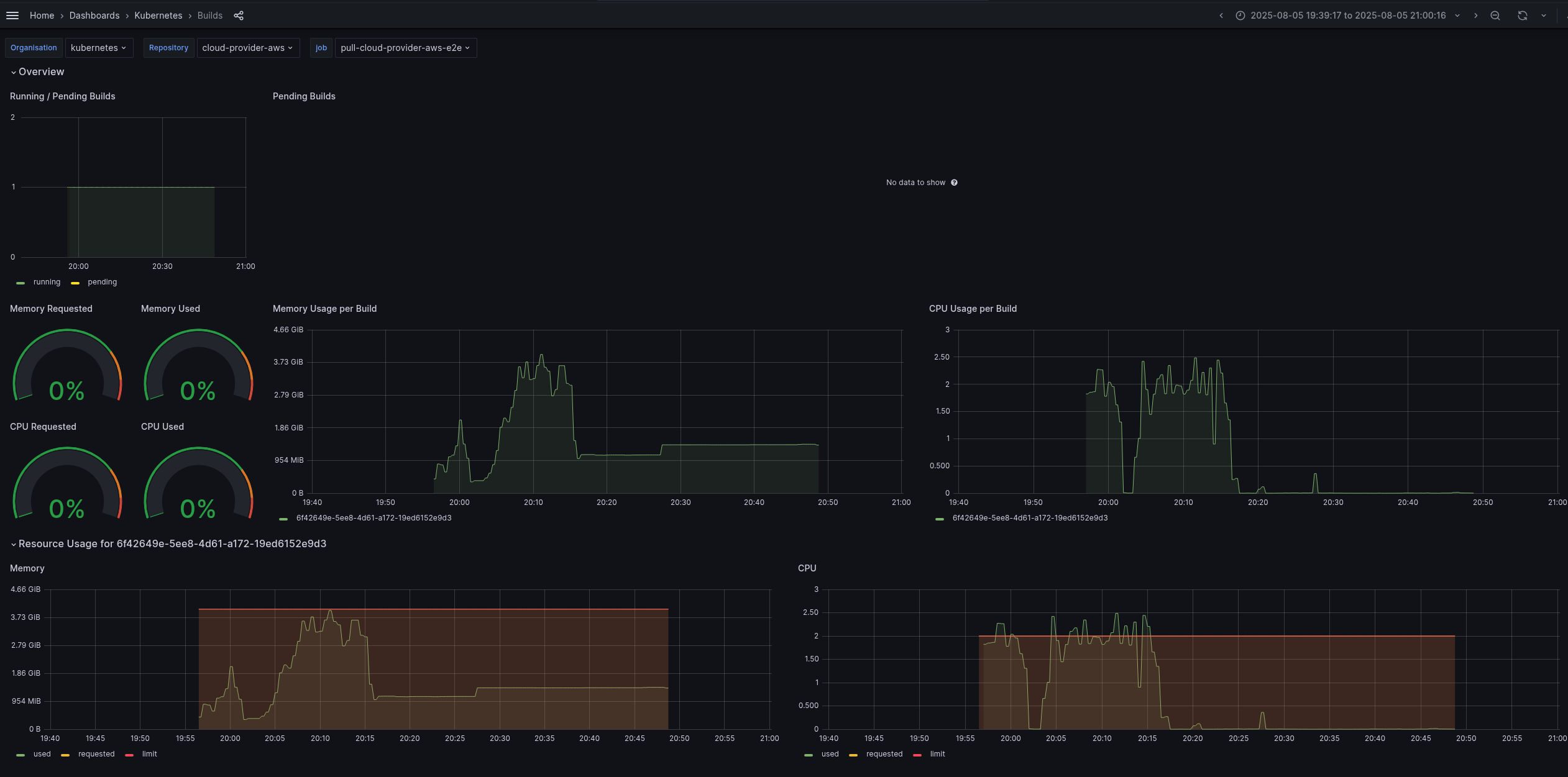
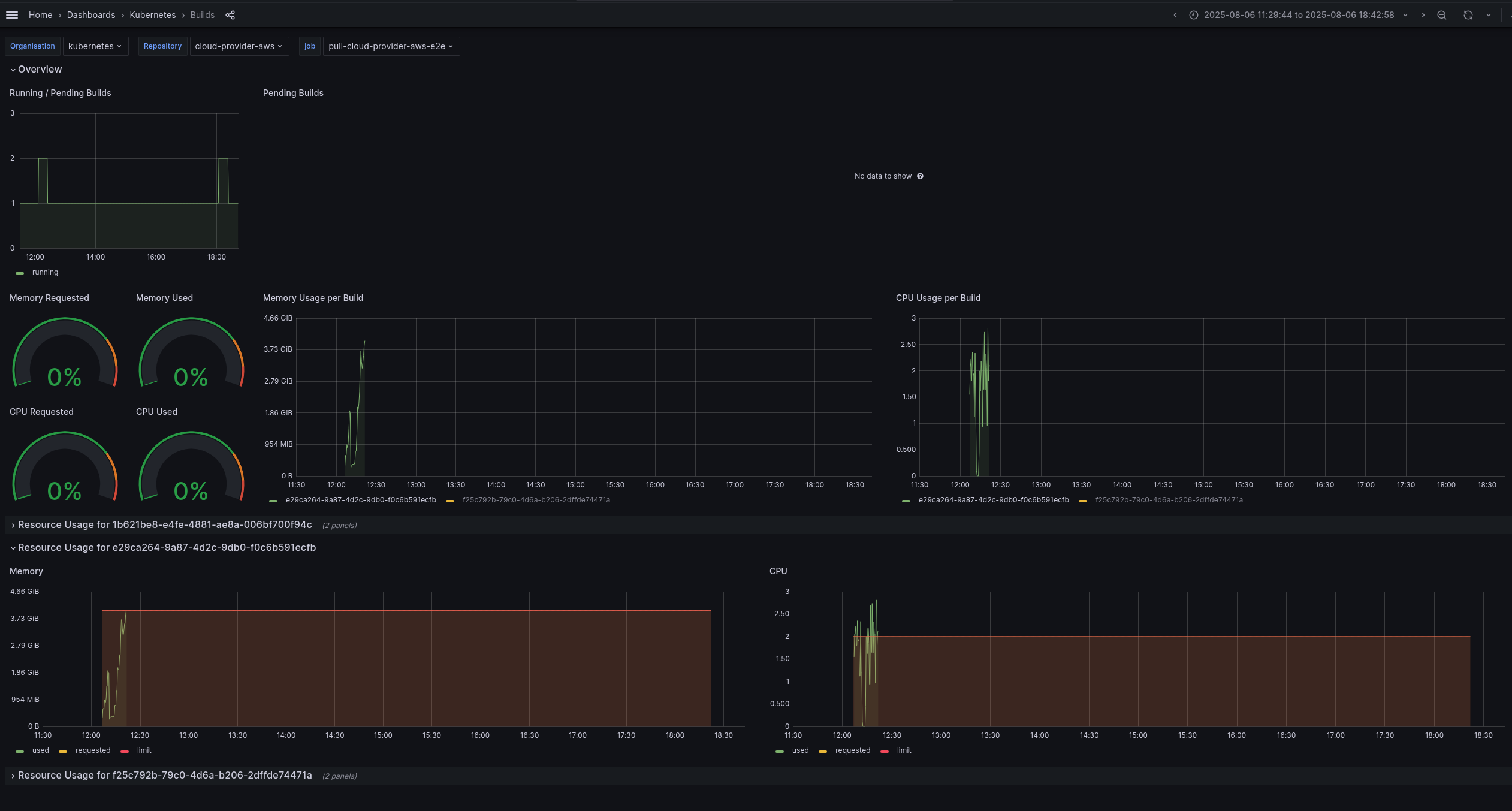
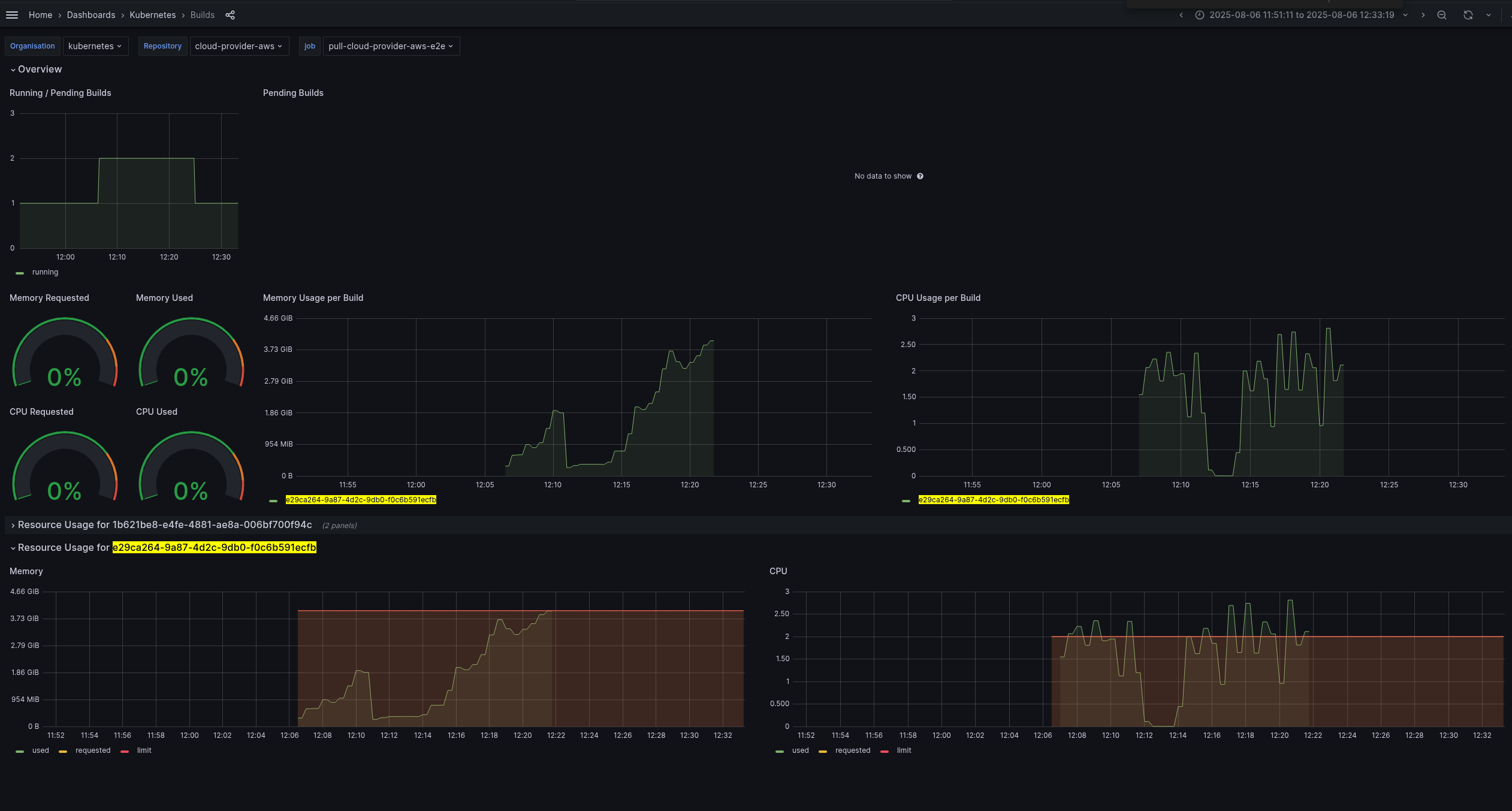
- CI monitoring dashboard (filtered in the period of job got stuck):
- Jobs overview dashboard https://monitoring-eks.prow.k8s.io/d/53g2x7OZz/jobs?orgId=1&var-org=kubernetes&var-repo=cloud-provider-aws&var-job=All&from=1754492403103&to=1754494500102
- Job examples:
- Failed job:
- https://prow.k8s.io/view/gs/kubernetes-ci-logs/pr-logs/pull/cloud-provider-aws/1158/pull-cloud-provider-aws-e2e/1953110200760143872
- https://monitoring-eks.prow.k8s.io/d/96Q8oOOZk/builds?orgId=1&var-org=kubernetes&var-repo=cloud-provider-aws&var-job=pull-cloud-provider-aws-e2e&var-build=All&from=1754433557755&to=1754438416037
- Dashboard snapshots:
- All job run: Screenshot From Screenshot From 2025-08-06 21-05-59.png

- Failed step time frame (with using above limits) : Screenshot From 2025-08-06 21-06-13.png
- All job run: Screenshot From Screenshot From 2025-08-06 21-05-59.png
- Succeeded job:
- https://prow.k8s.io/view/gs/kubernetes-ci-logs/pr-logs/pull/cloud-provider-aws/1158/pull-cloud-provider-aws-e2e/1952866070154973184
- https://monitoring-eks.prow.k8s.io/d/96Q8oOOZk/builds?orgId=1&var-org=kubernetes&var-repo=cloud-provider-aws&var-job=pull-cloud-provider-aws-e2e&var-build=All&from=1754433606980&to=1754438510368
- Dashboard snapshots:
- All job run: Screenshot From Screenshot From 2025-08-06 21-03-32.png
- All job run: Screenshot From Screenshot From 2025-08-06 21-03-32.png
- Failed job:
Acceptance Criteria:
- Open an upstream issue reporting the problem
- Open an PR proposing increasing the job resource limit
- Check any room for optimization to the step (maybe using pre-built kops binary instead of downloading every time?)
- Open a PR updating development document, CI section, to upstream refrencing the Grafana dashboard
Other Information:
< Record anything else that may be helpful to someone else picking up the card >
issue created by splat-bot