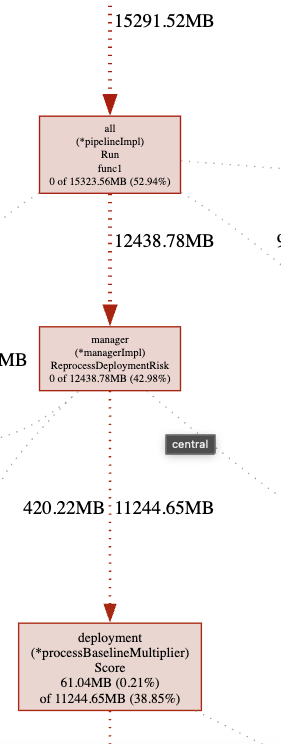
As noted in numerous support cases recently, the reprocessing of risk particularly related to process baselines and process indicators is consuming an large amount of memory and compute resources. There are some suboptimal patterns in that chunk of code we must look at and improve.
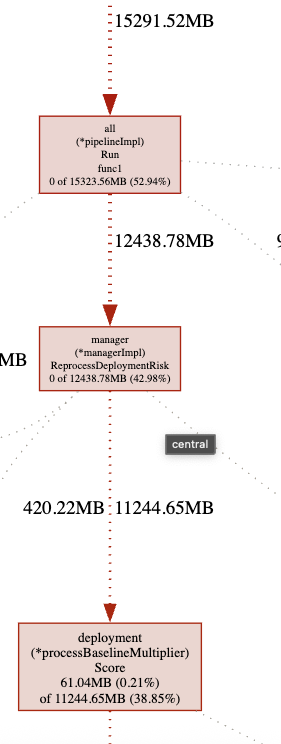
Things we need to do:
- Create bench mark tests to measure success
- We should only query the indicators we need not ALL of them from the deployment. Meaning we should add container name to the indicator query.
- The process indicator object can be quite large. We should only query the fields we need when we need them. We only need the arguments for the violating processes so those should be a separate query. We only need the ID, path, and a couple of time fields for evaluation if it is a violation or not. We can greatly reduce memory consumption by only retrieving those fields. That will alleviate pressure on both the database and central.