Description of problem:
When submitting a pipeline from Elyra, the resulting run in the DS Pipelines page as well as the `PipelineRun` details page in OCP show placeholder names for all pipelines steps (run-a-file-N).
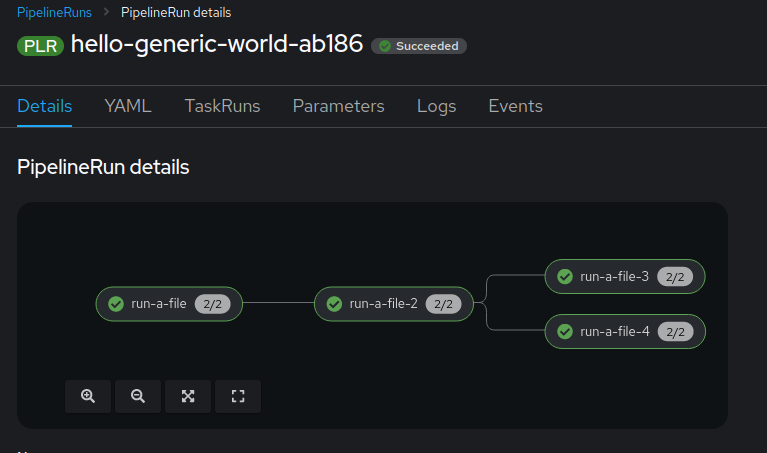
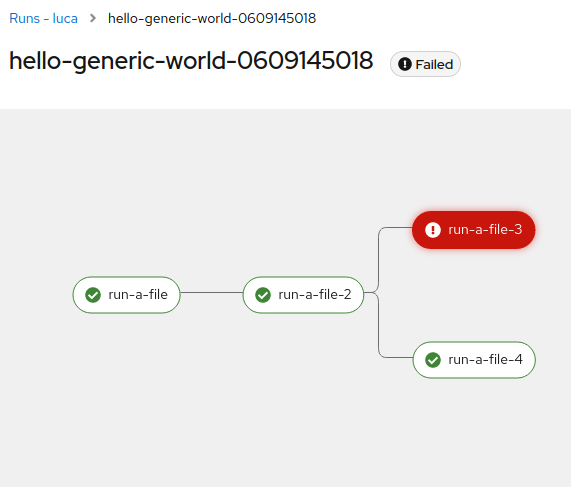
This appears to be a UI issue, since the correct file/step names are included in the logs of the executions and in the `Run output` as well, e.g.:
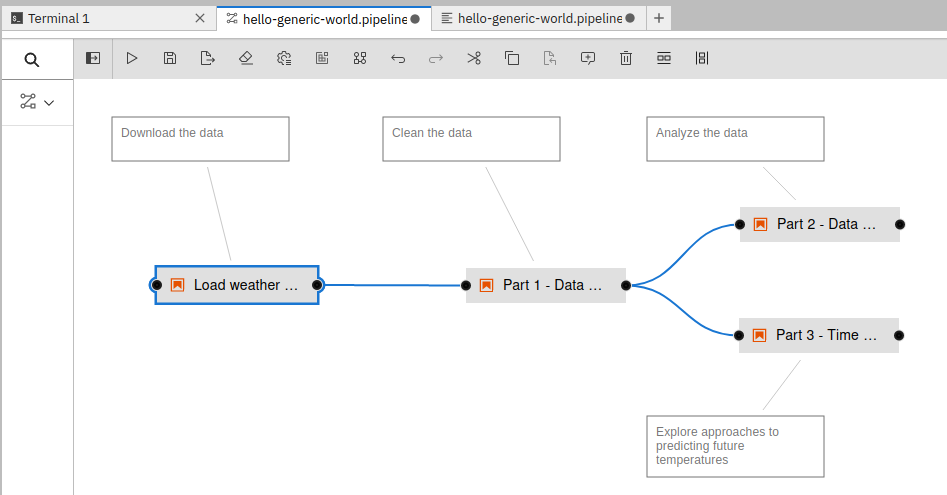
metadata: labels: elyra/experiment-name: "" elyra/node-name: Load_weather_data elyra/node-type: notebook-script elyra/pipeline-name: hello-generic-world elyra/pipeline-version: "" pipelines.kubeflow.org/cache_enabled: "true" annotations: elyra/node-file-name: data-science-pipeline-example/run-pipelines-on-data-science-pipelines/load_data.ipynb elyra/node-user-doc: Download the data elyra/pipeline-source: hello-generic-world.pipeline pipelines.kubeflow.org/component_spec_digest: '{"name": "Run a file", "outputs": [], "version": "Run a file@sha256=27d56f1aeb449022952e389834b4332b0c8b06a075c81ddbe1f648a11fc7257f"}' pipelines.kubeflow.org/task_display_name: Load weather data
[D 15:00:51.733] Parsing Arguments..... [I 15:00:51.735] 'hello-generic-world':'load_data' - starting operation
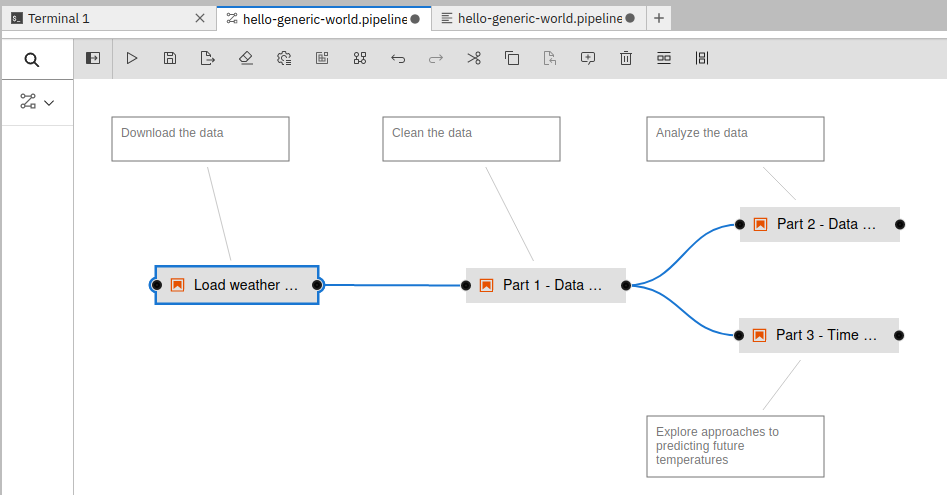
when starting from a pipeline that looks like this in Elyra:
Prerequisites (if any, like setup, operators/versions):
RHODS 1.28 RC
Steps to Reproduce
- Set up DS Project
- Set up DS Pipelines
- Create Data Connection / Pipeline Server
- Start Workbench with image that includes Elyra (e.g. Standard Data Science, v2023.1)
- Clone repo with pipeline example (https://github.com/harshad16/data-science-pipeline-example)
- Open hello-world pipeline
- Submit pipeline to be run using runtime config "Data Science Pipeline"
- Go to Run details in RHODS / PipelineRun details in OCP
Actual results:
All the steps have the name `run-a-file-N`
Expected results:
Steps have the same names shown in Elyra
Reproducibility (Always/Intermittent/Only Once):
Always
Build Details:
Workaround:
Additional info:

- duplicates
-
RHODS-9445 imported Elyra pipeline shows generic text for all steps in visualization
-

- Closed
-