-
Bug
-
Resolution: Done
-
 Critical
Critical
-
RHODS_1.23.0_GA
-
1
-
False
-
-
False
-
None
-
Release Notes
-
Testable
-
No
-
-
-
-
-
-
-
1.31.0
-
No
-
-
Known Issue
-
Done
-
No
-
Pending
-
None
-
-
-
RHODS 1.30, RHODS 1.31
-
Important
Description of problem:
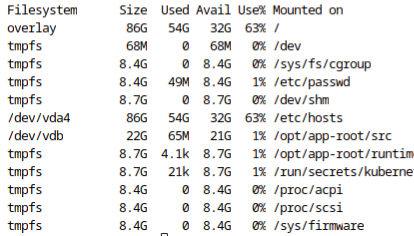
Jupyter notebooks deployed by RHODS has the shared memory (/dev/shm) set to 64Mb. There doesn't appear to be any way to change this default. This creates issues with Pytorch running multiple workers on GPU enabled nodes. Multiple workers significantly speeds up training tasks, but a 64Mb limit forces the user to disable multiple workers. The increase in performance can be an order of magnitude faster and utilizes GPUs more optimally.
Prerequisites (if any, like setup, operators/versions):
Steps to Reproduce
- Deploy a Jupyter notebook.
- Clone a repo that uses Pytorch. In my case https://github.com/ultralytics/yolov5
- After running "pip install -r requirements.txt" run "python train.py" with no arguments.
Actual results:
Jupyter will report "no space left on device" and you will notice /dev/smh is full.
Expected results:
The training script should begin running 100 epochs on the training data without error.
Reproducibility (Always/Intermittent/Only Once):
Always
Build Details:
Workaround:
Run with no workers