-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
None
-
False
-
-
False
-
None
-
Testable
-
Yes
-
-
-
-
-
-
-
1.20.0-z
-
No
-
No
-
Yes
-
None
-
-
Description of problem:
When configuring a server pod in a DSP for model serving, the pod that is created in the project namespace will often go in CrashLoopBackOff because of failure in the "mm" container regarding the connection to the etcd pod deployed in redhat-ods-applications. This is sometimes fixed automatically when the pod tries restarting, other times it can only be fixed by manually deleting the pod or scaling down/up the deployment, other times nothing seems to fix it.
Prerequisites (if any, like setup, operators/versions):
Latest model serving live build
Steps to Reproduce
- Create DSP
- Configure Server
- Go into DSP namespace and check server pod status
Actual results:
pod is often found in CrashLoopBackOff status (more than 50% of the time)
Expected results:
pod is always deployed successfully
Reproducibility (Always/Intermittent/Only Once):
Intermittent but frequent
Build Details:
Workaround:
Delete pod and wait for RS/Deployment to bring it back up, or scale down/up the number of pods from the deployment. This sometimes fixes the problem, but not always.
Additional info:
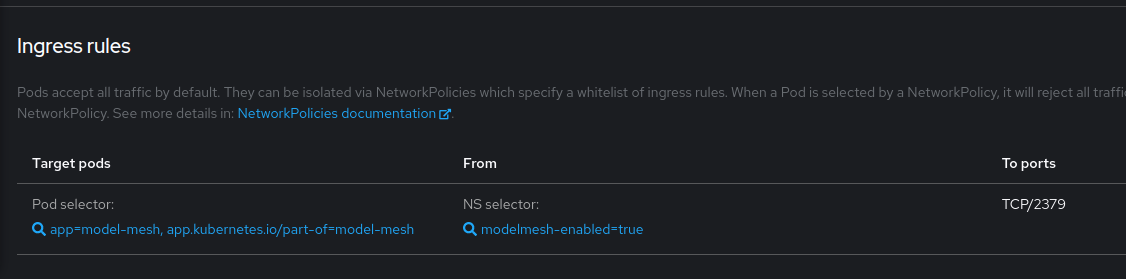
- mentioned on