-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
None
-
False
-
-
False
-
None
-
Release Notes
-
Testable
-
Yes
-
-
-
-
-
-
-
No
-
-
Bug Fix
-
No
-
Yes
-
None
-
-
-
RHODS 1.20
Description of problem:
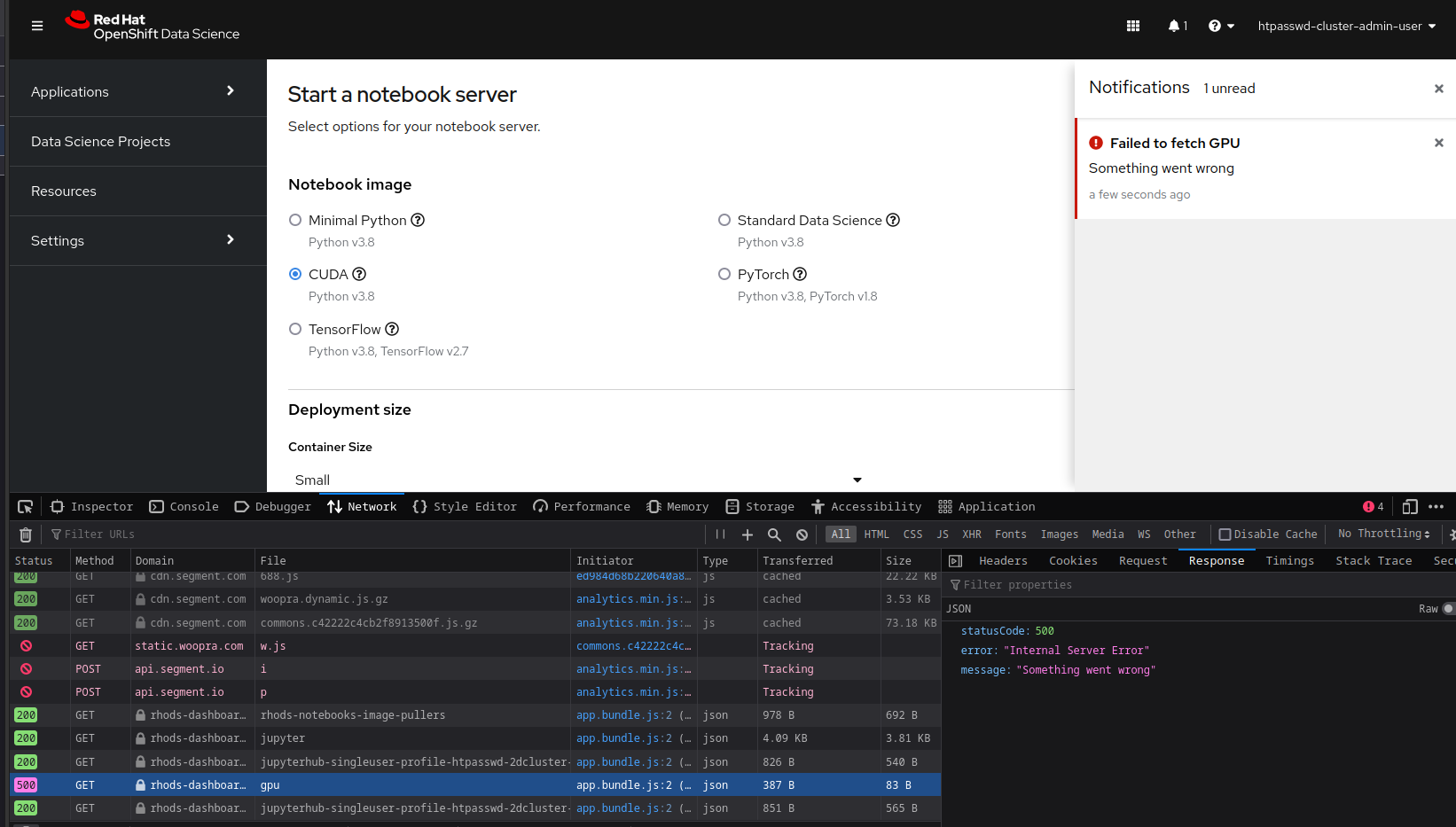
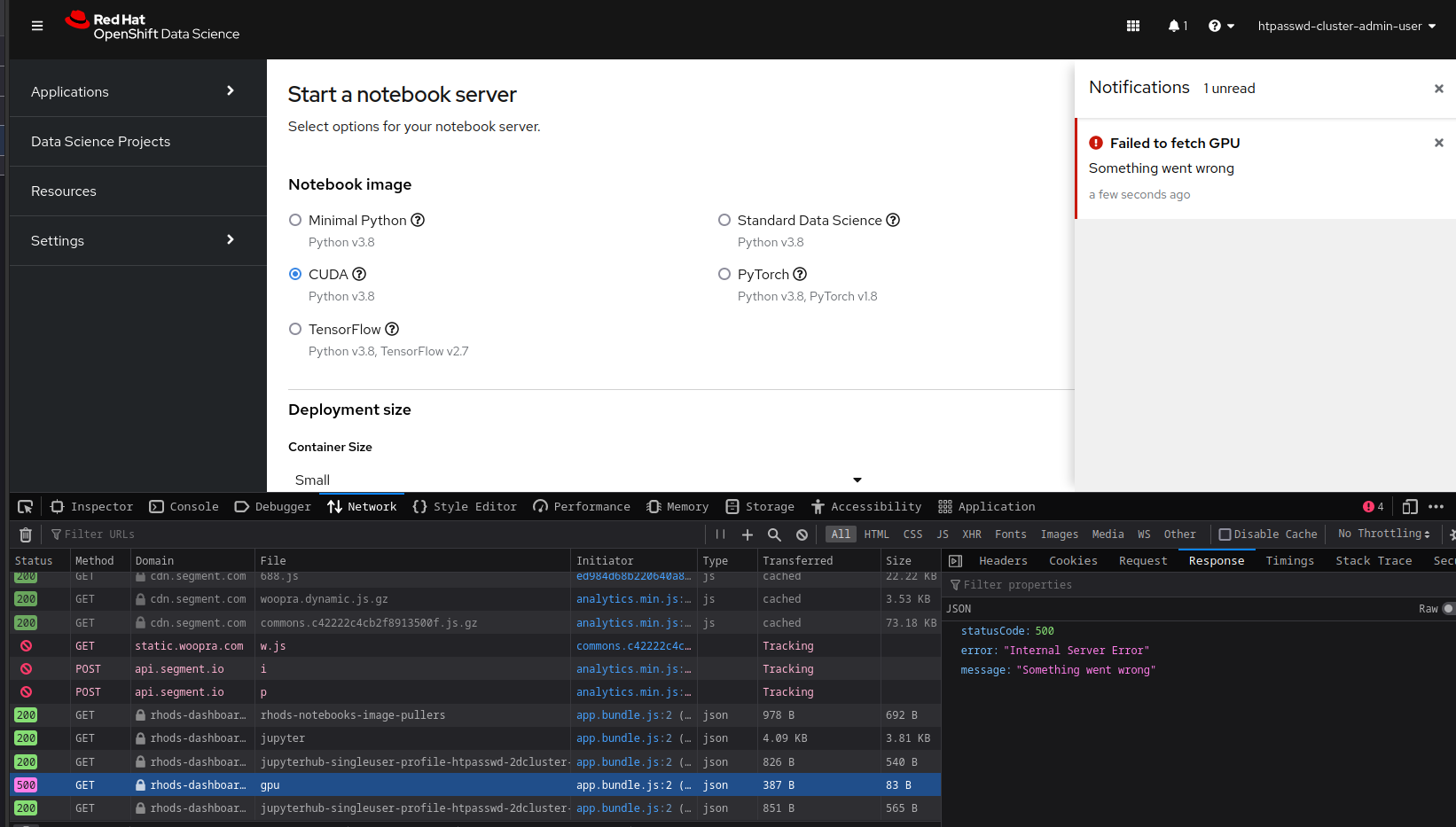
in the latest RHODS 1.19 RC (1.19.0-14), the spawner page will show an error up every time the page is loaded if there is a provisioned GPU node on the cluster
 This happens either with a node directly provisioned with its own machine pool, or with a node provisioned with an autoscaler.
This happens either with a node directly provisioned with its own machine pool, or with a node provisioned with an autoscaler.
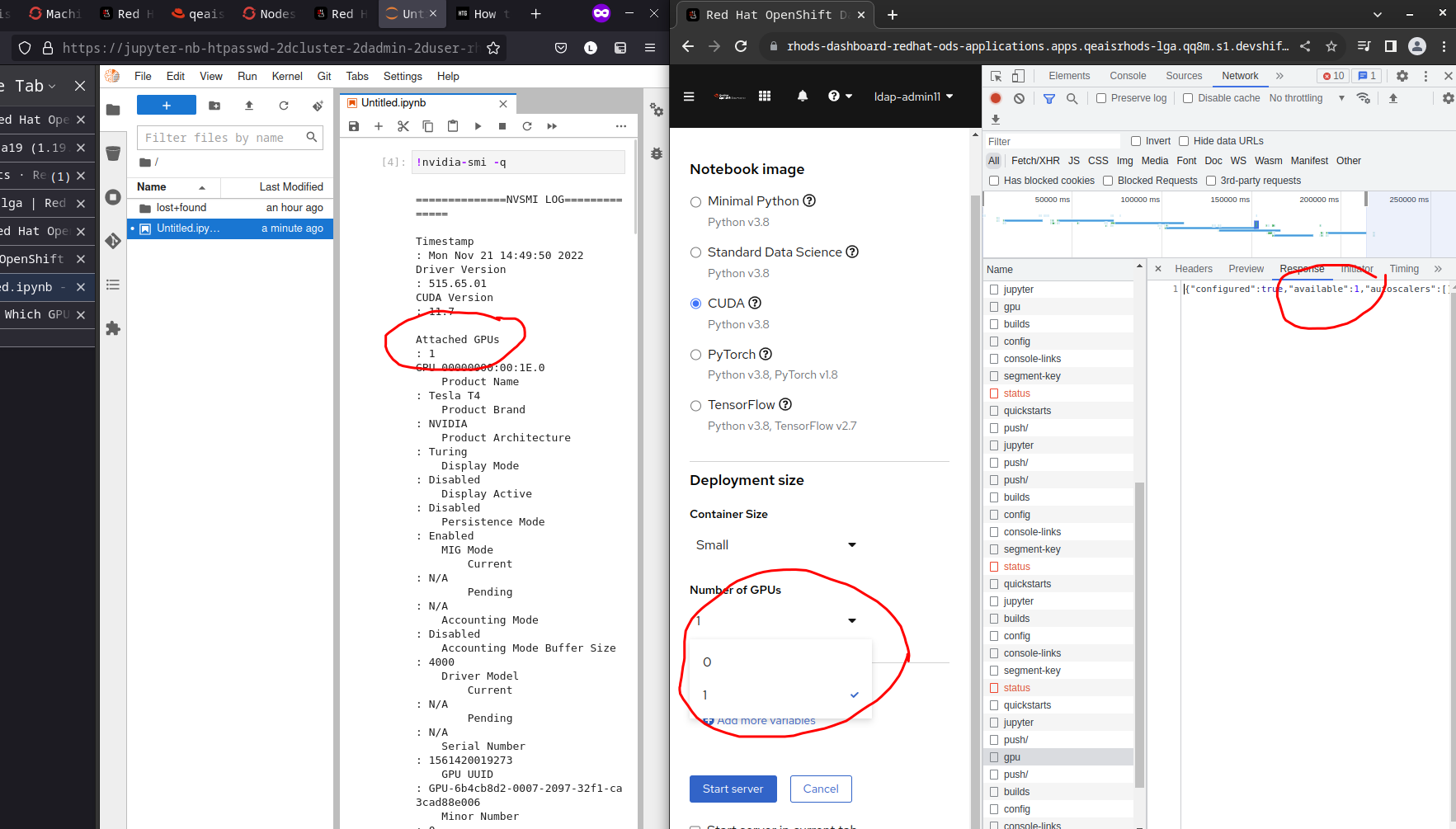
The error also disables the GPU dropdown (in the default "autodetect" version) making it impossible to request a GPU by default.
These are the pod logs from one of the dashboard pods:
rhods-dashboard-c79597765-brvhh-rhods-dashboard.log![]()
Which show that the Prometheus request made by the dashboard to get the number of GPUs triggers a response showing the OpenShift login page.
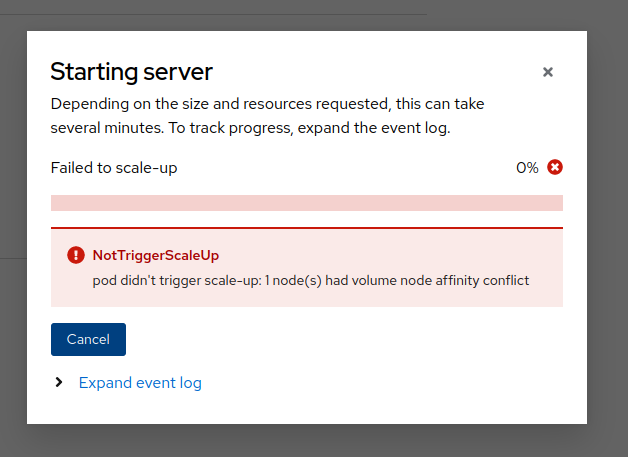
There seem to be two workaround to spawn a server on a gpu node:
- Create an autoscaler with a minimum of 0 nodes
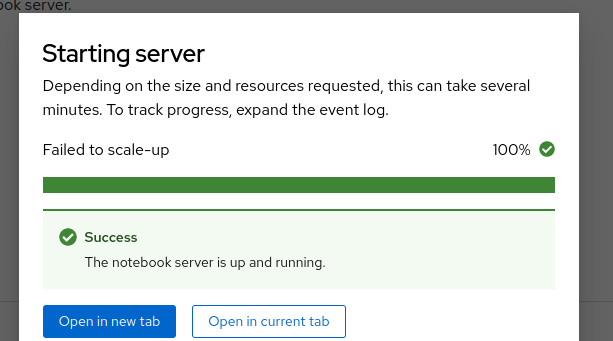
- Once the spawner page shows the option to request a GPU, try spawning a server
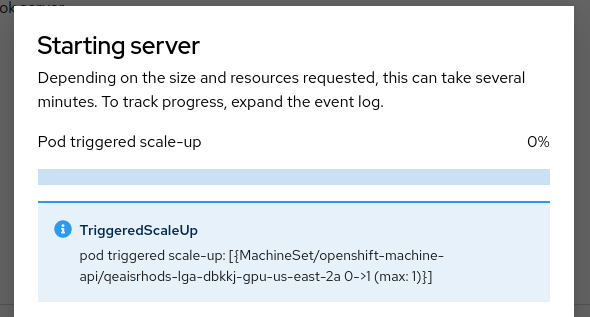
- this should trigger an autoscale request, provisioning GPU nodes
- Once the node is provisioned and the GPU addon has installed the CUDA driver, the server pod should be scheduled on the node
- After this point other users won't be able to request GPUs since the node has been provisioned and the spawner will start showing the error and hiding the dropdown on each page load
- From the spawner modal, choose to open the server in the same/another tab
- use the gpuSetting field in the OdhDashboardConfig CR
- set the gpuSetting in the CR to '1' (or max number of GPUs in your nodes)
- Provision a node (or more) with the same number of GPUs per node
- Once the node is running and labeled by the nvidia gpu addon, start a spawn request with 1 or more GPUs attached
- OpenShift should correctly place the server pod on the gpu node.
Prerequisites (if any, like setup, operators/versions):
RHODS 1.19.0-14
OCP 4.10 (the latest version of 4.11, i.e. 4.11.12 at the time of writing, is incompatible with the nvidia gpu addon)
Steps to Reproduce
- install RHODS 1.19.0-14
- Provision gpu node / autoscaling machine pool with min>=1
- Install GPU addon
- Visit RHODS spawner page
Actual results:
An error popup is shown "Failed to fetch GPU, something went wrong"
the gpu dropdown is hidden
Expected results:
No error popup on page load, gpu dropdown correctly showing the maximum number of gpus that can be requested
Reproducibility (Always/Intermittent/Only Once):
Always on one cluster
Build Details:
rhods 1.19.0-14 on OCP 4.10 latest
Workaround:
There seem to be two workaround to spawn a gpu node:
- Create an autoscaler with a minimum of 0 nodes
- Once the spawner page shows the option to request a GPU, try spawning a server
- this should trigger an autoscale request, provisioning GPU nodes
- Once the node is provisioned and the GPU addon has installed the CUDA driver, the server pod should be scheduled on the node
- After this point other users won't be able to request GPUs since the node has been provisioned and the spawner will start showing the error and hiding the dropdown on each page load
- From the spawner modal, choose to open the server in the same/another tab, which should redirect/load to the server with gpu attached
- use the gpuSetting field in the OdhDashboardConfig CR
- set the gpuSetting in the CR to '1' (or max number of GPUs in your nodes)
- Provision a node (or more) with the same number of GPUs per node
- Once the node is running and labeled by the nvidia gpu addon, start a spawn request with 1 or more GPUs attached
- OpenShift should correctly place the server pod on the gpu node.