Description of problem:
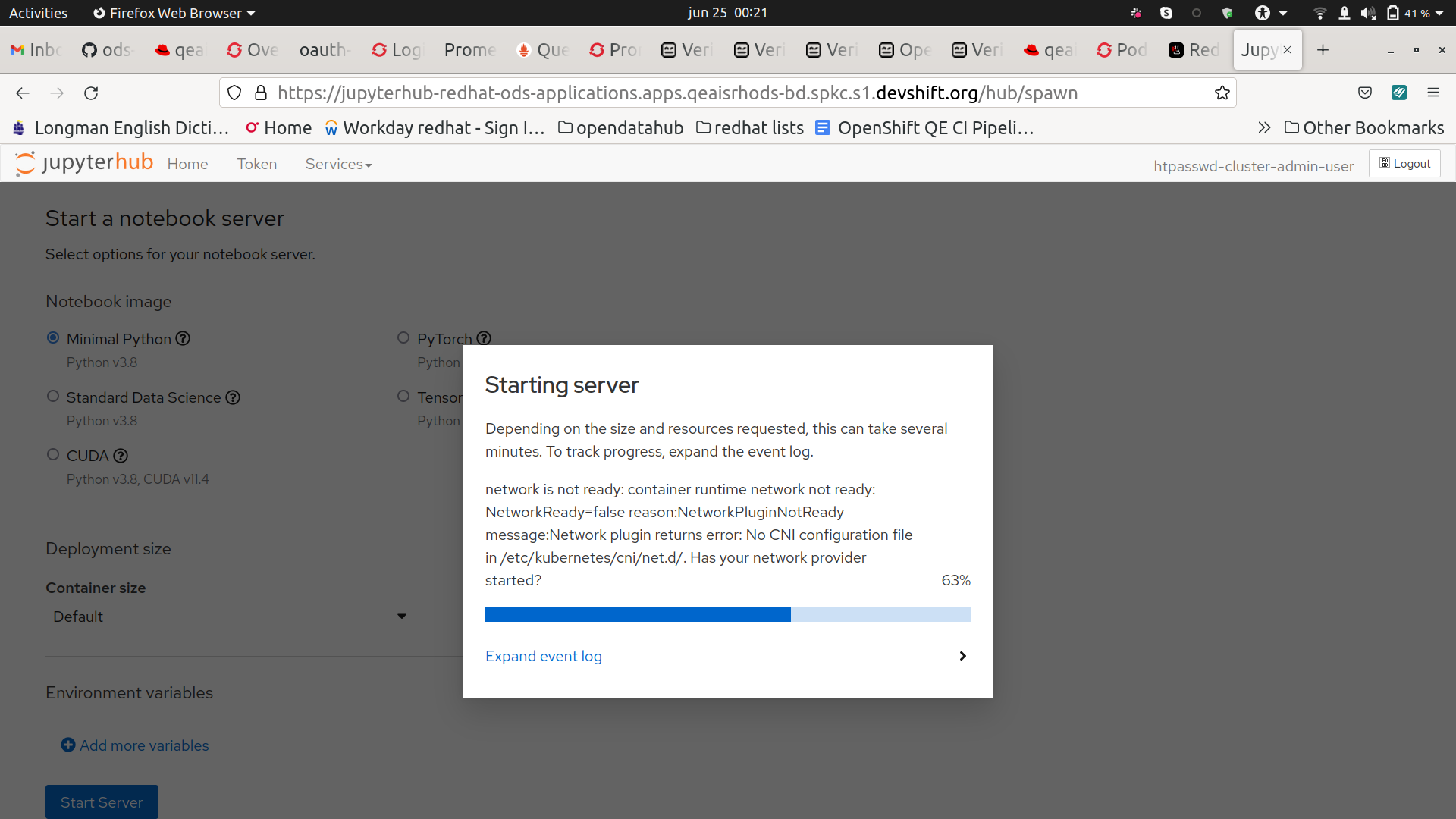
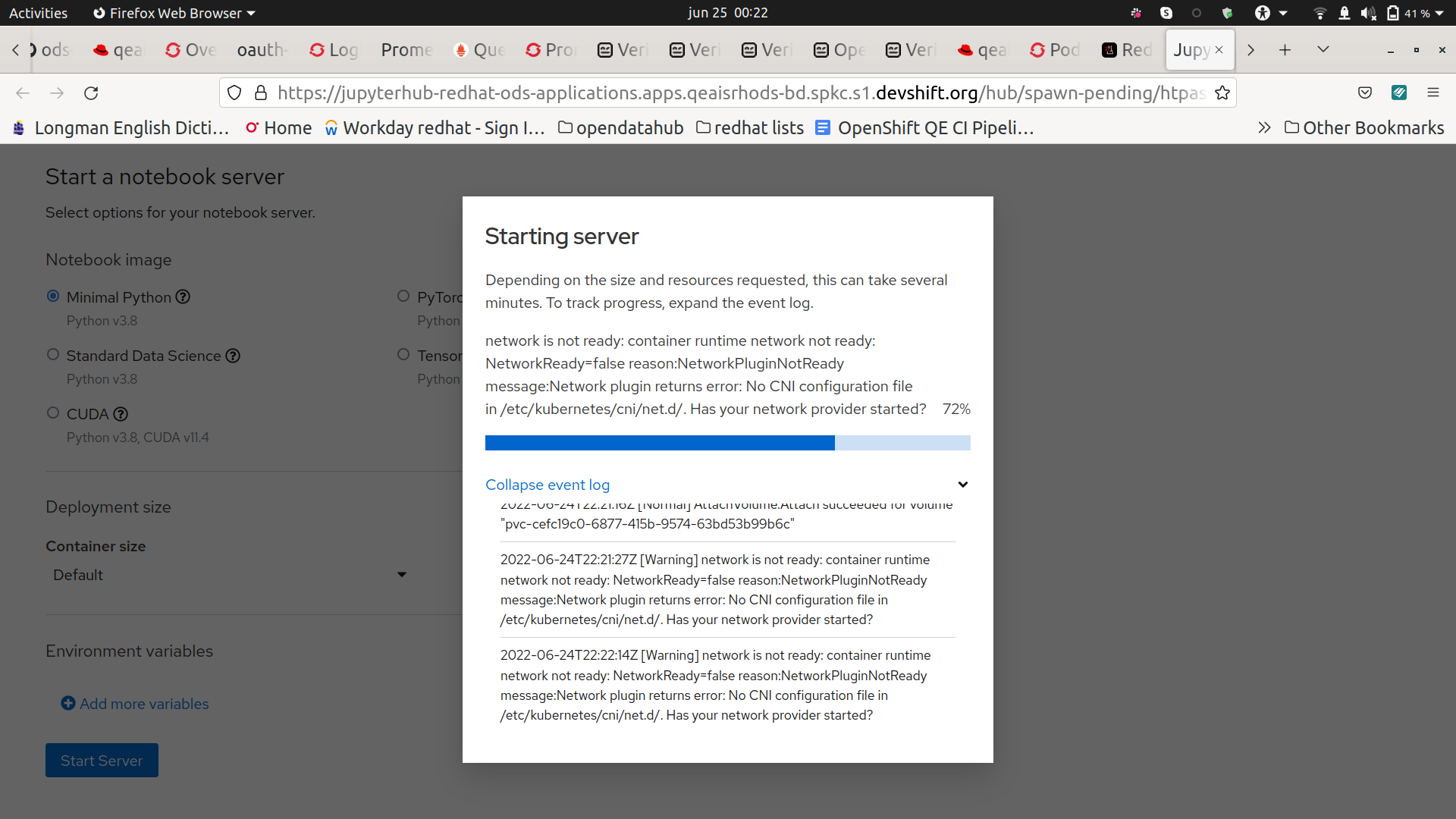
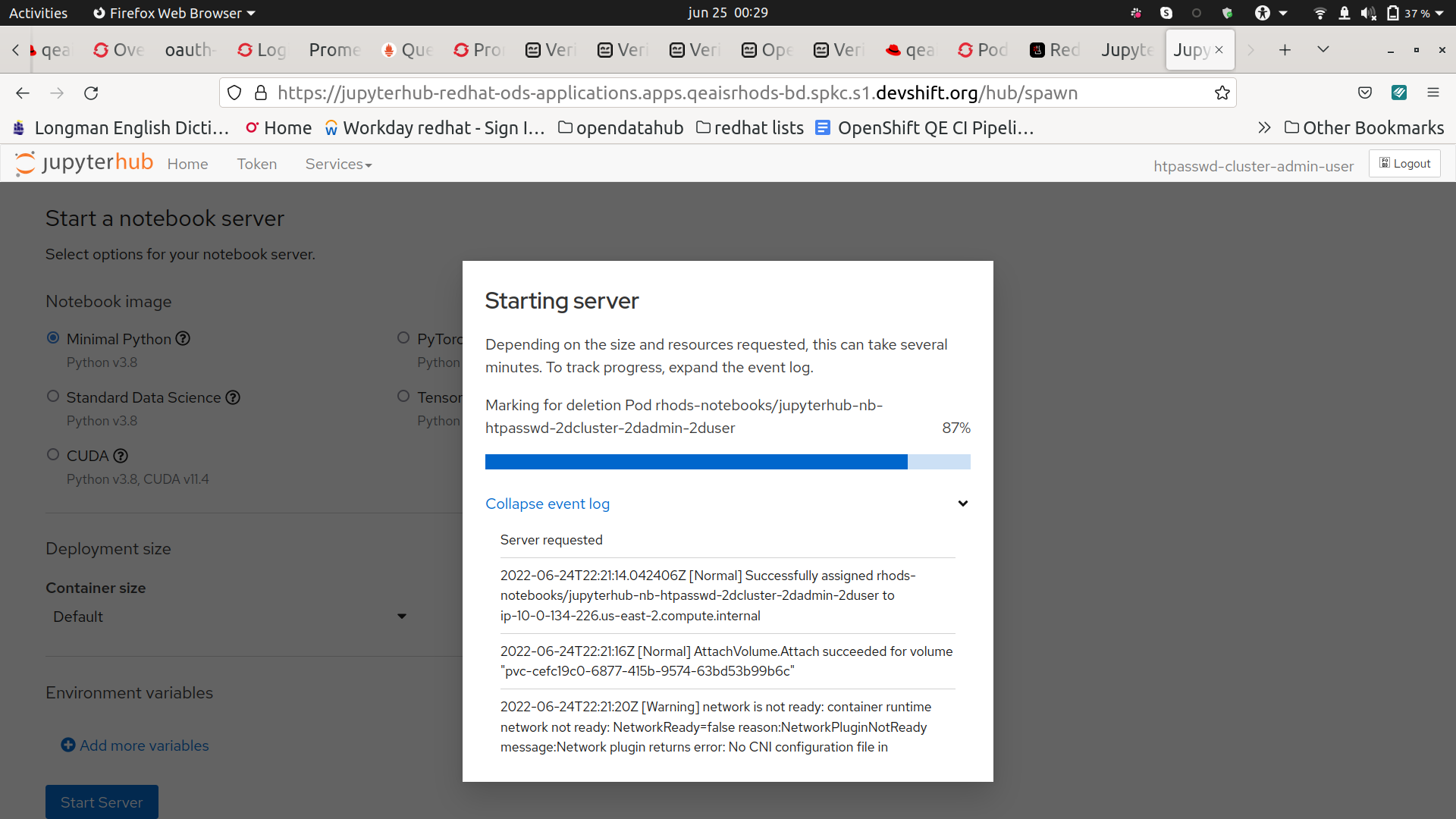
The restart of the node lasted 7 minutes and there were 7 minutes of downtime. It looks like this could happen because the pods of some services are all in the same node, causing a loss of service while the node is restarting. For example, in the test I did, the black-box pods were down, and also when trying to spawn a notebook, the notebook only started when the node started again.
Prerequisites (if any, like setup, operators/versions):
RHODS installed in a cluster with 2 worker nodes
Steps to Reproduce
- Install RHODS
- restart a node
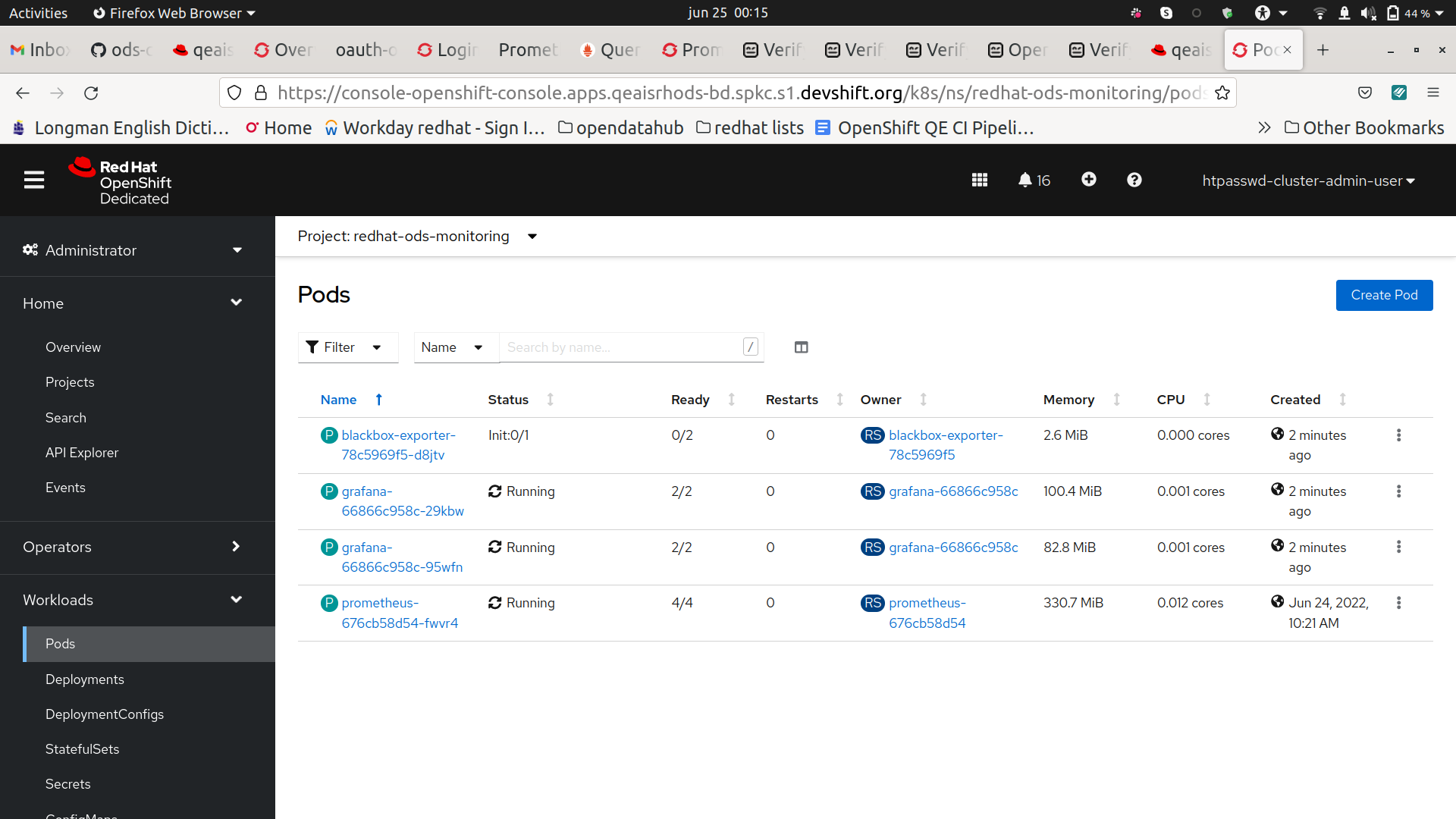
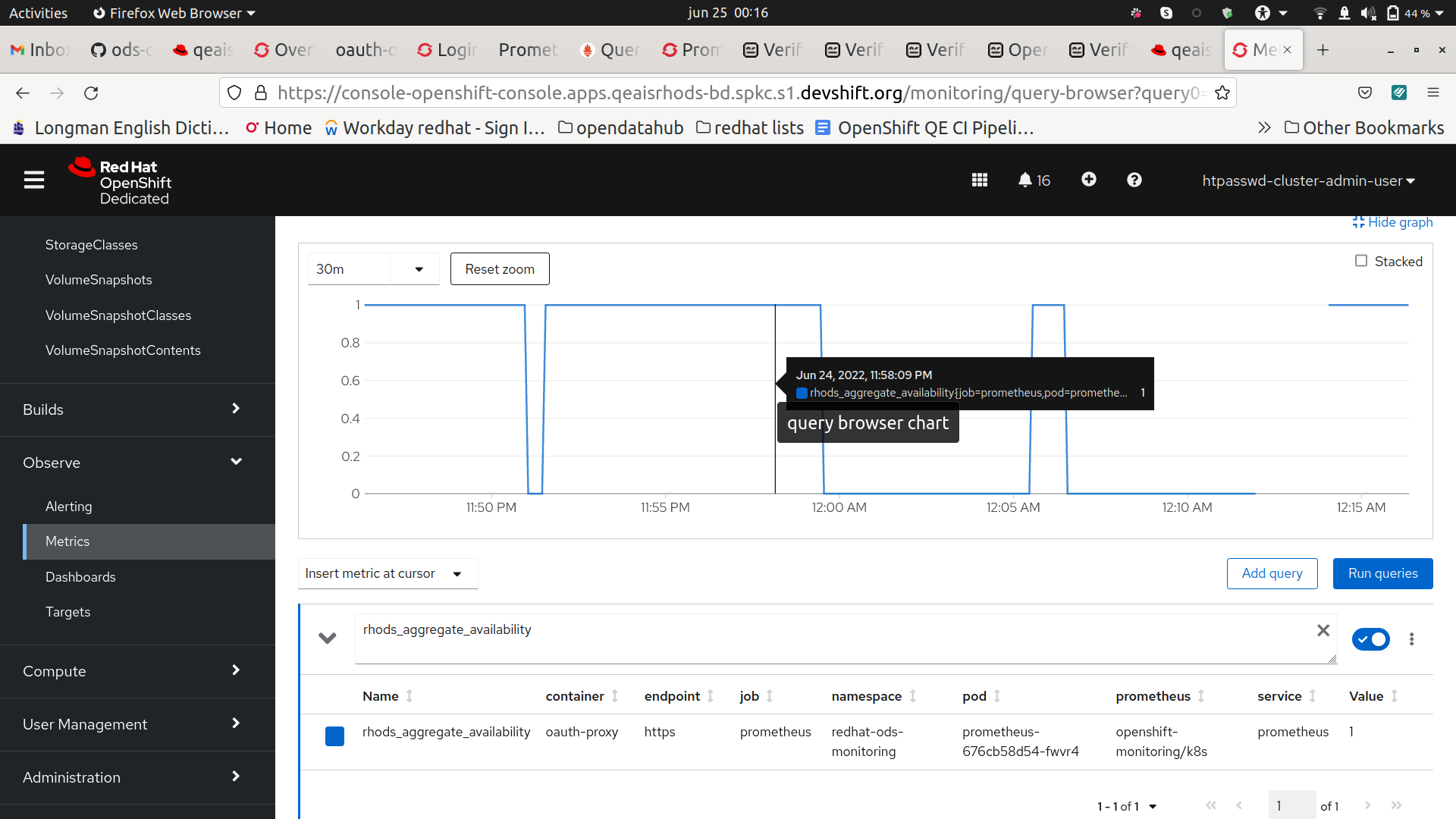
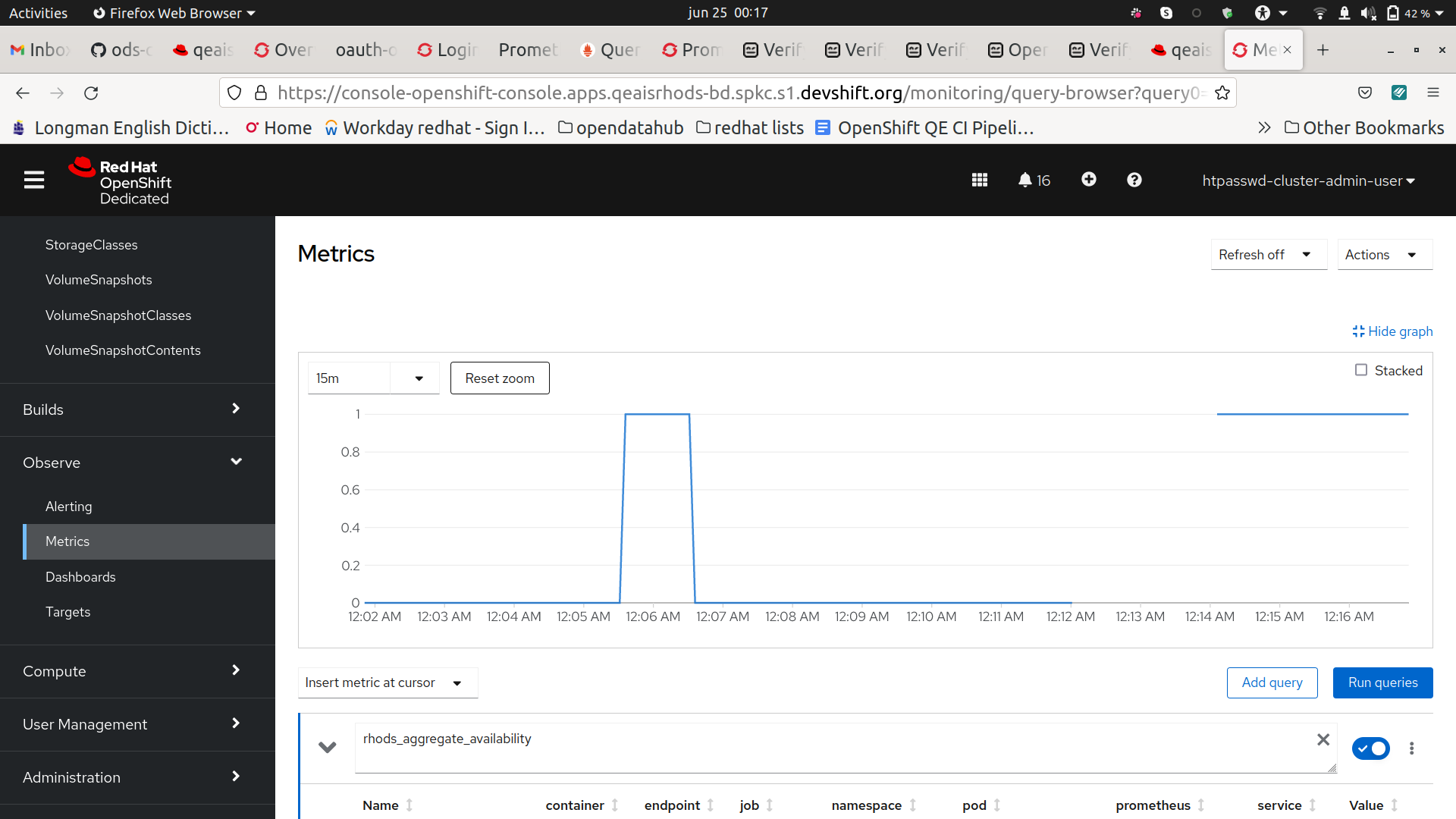
- Verify availability with rhods_aggregate_availability
Actual results:
There is a downtime of 7 minutes
Expected results:
There is no downtime
Reproducibility (Always/Intermittent/Only Once):
intermittent depends on the node that you're deleting
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}