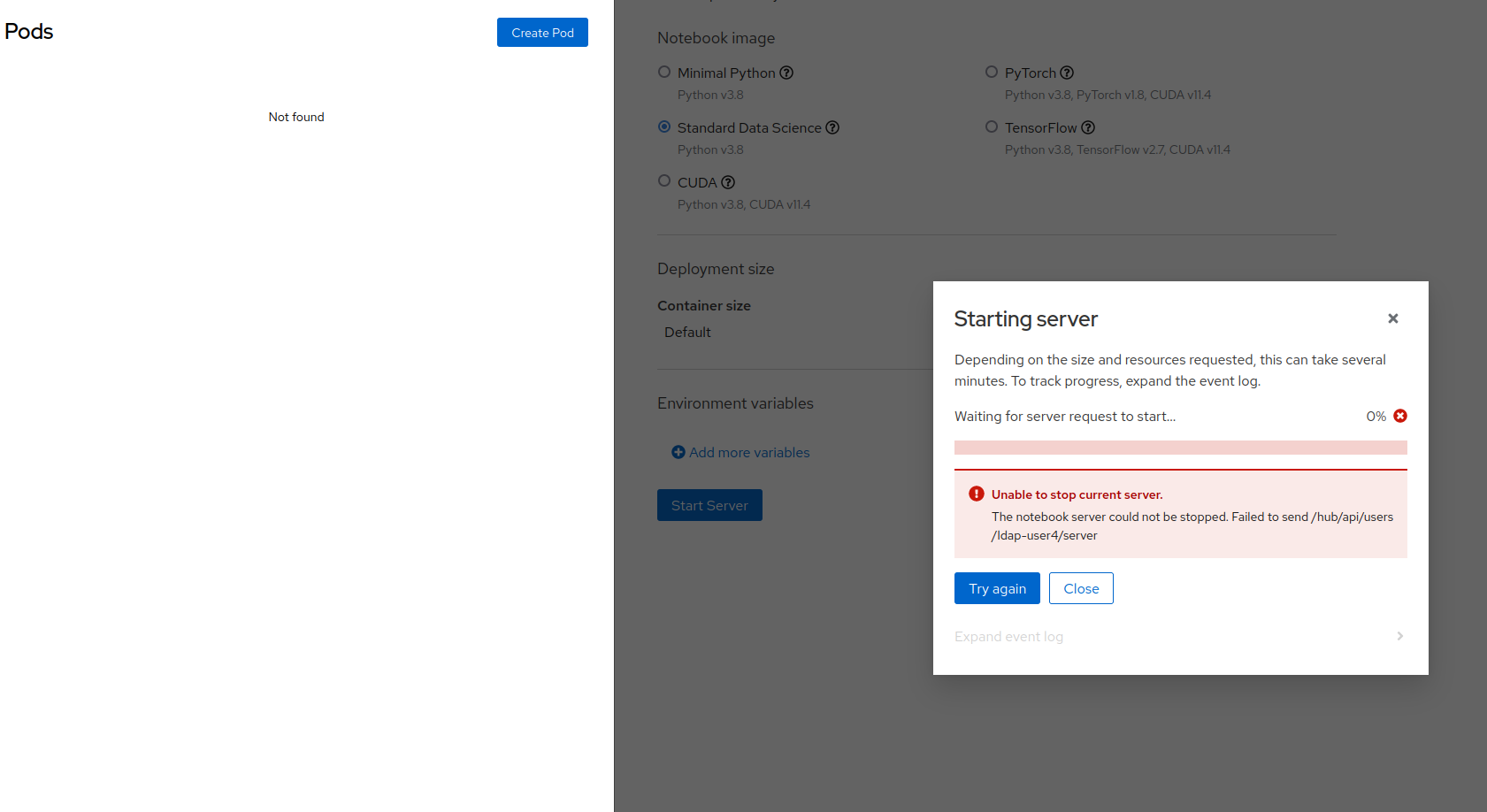
Description of problem:
If the leader JH pod dies while a user is trying to spawn a notebook server, the user will not be redirected to their server but instead be stuck with an error message that does not seem fixable in any way other than waiting the default 10m timeout for the spawner.
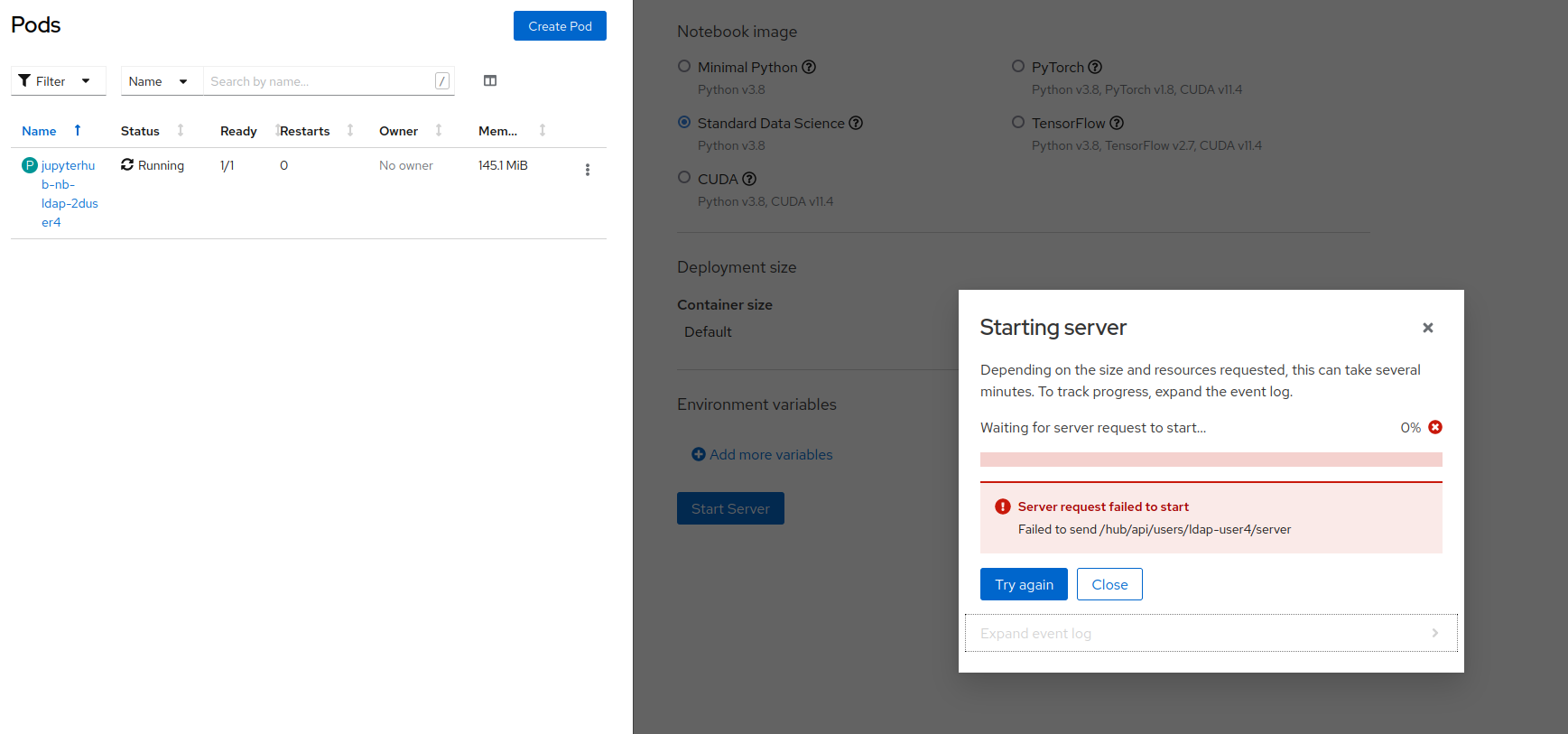
When the leader pod dies during spawn, we see the server pod being created in the rhods-notebook namespace but an error message in the JH spawner about failing to start the server.
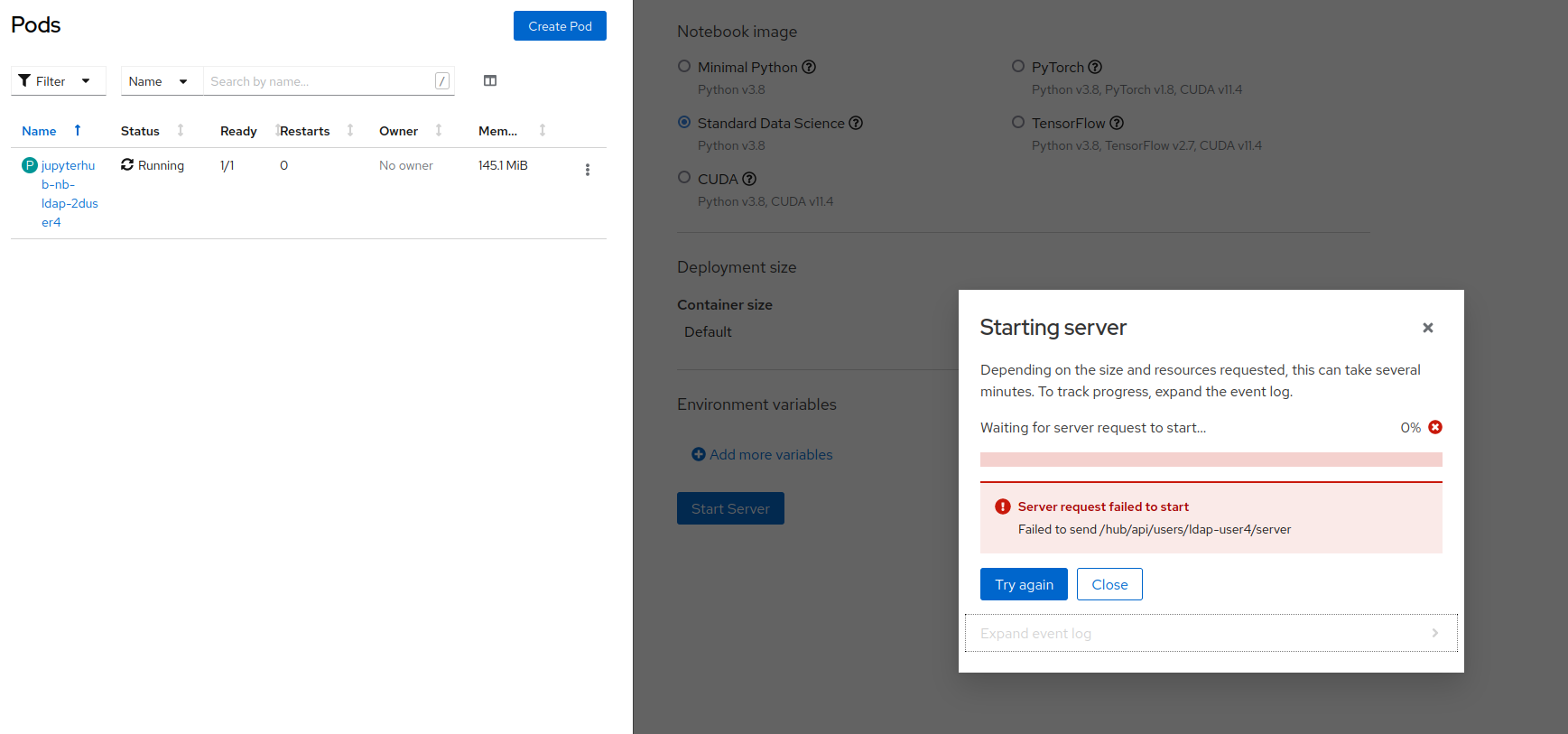
Usually this could be fixed by reloading the page and the user would be redirected to their running server. However now the user is always brought back to the spawner page and the same error message is shown.
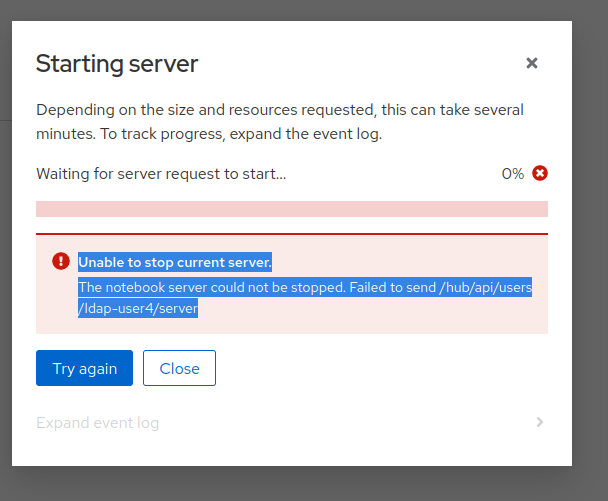
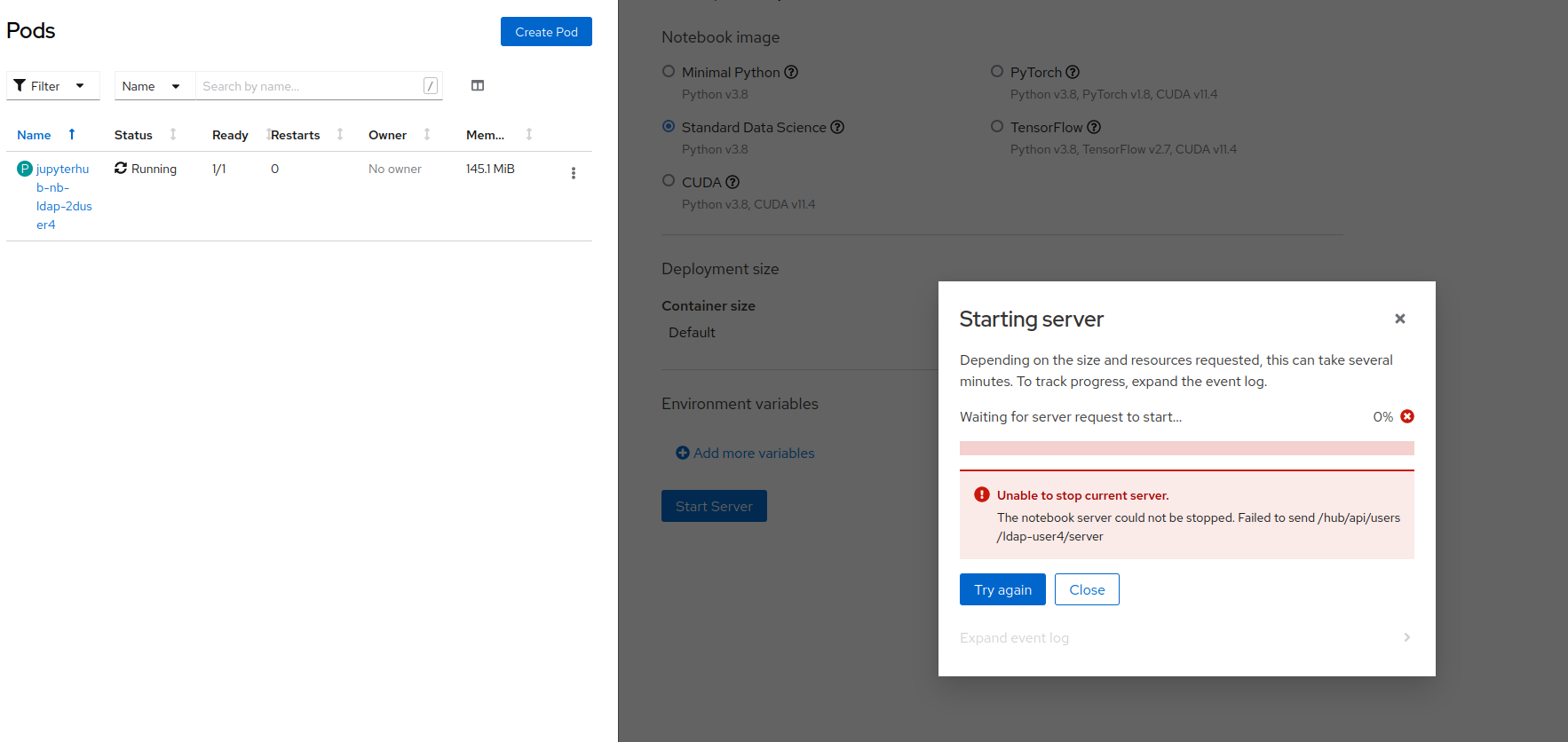
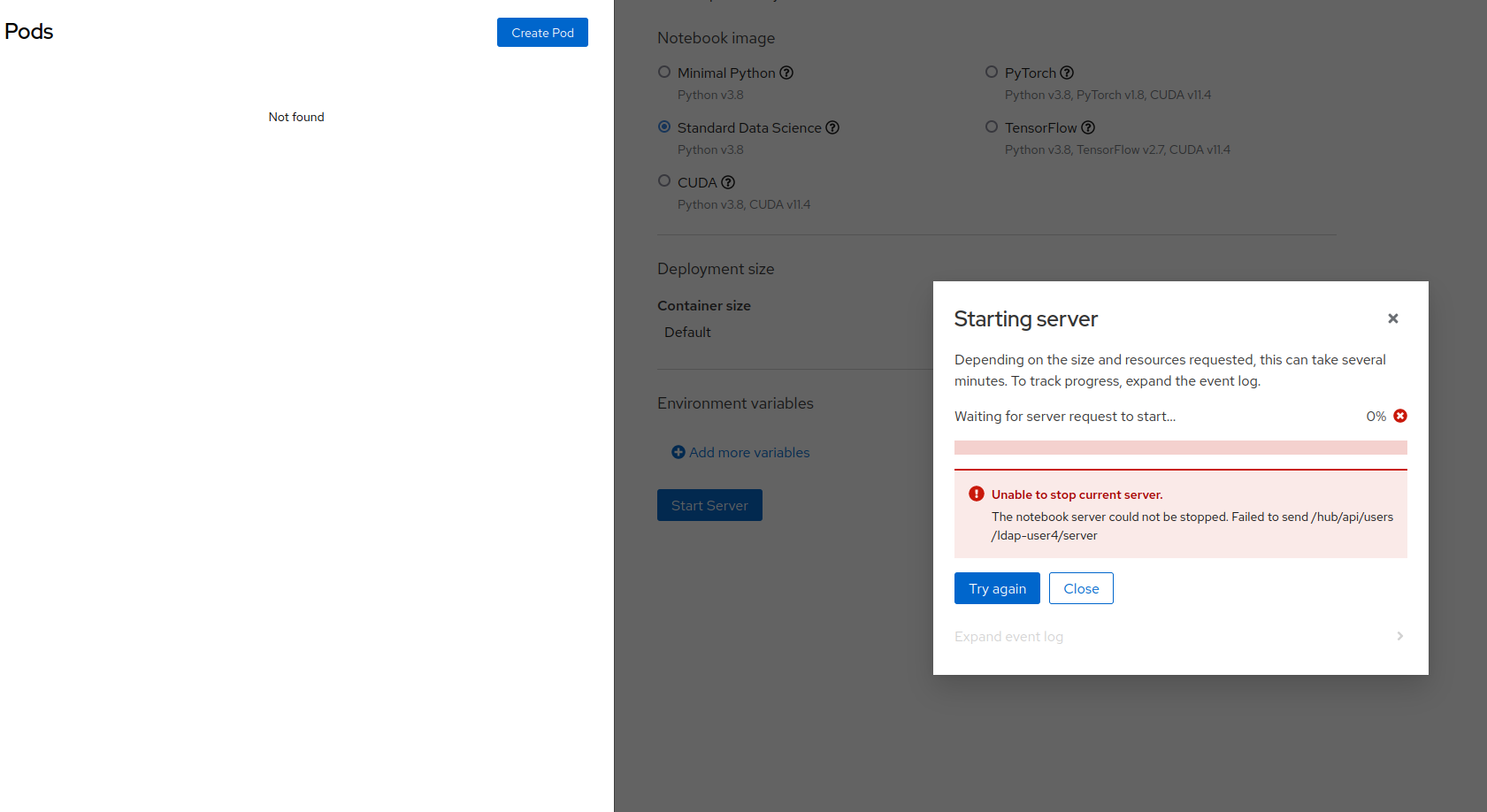
Furthermore, if clicking on "Try Again" the user is shown a different error message about failing to stop the current server
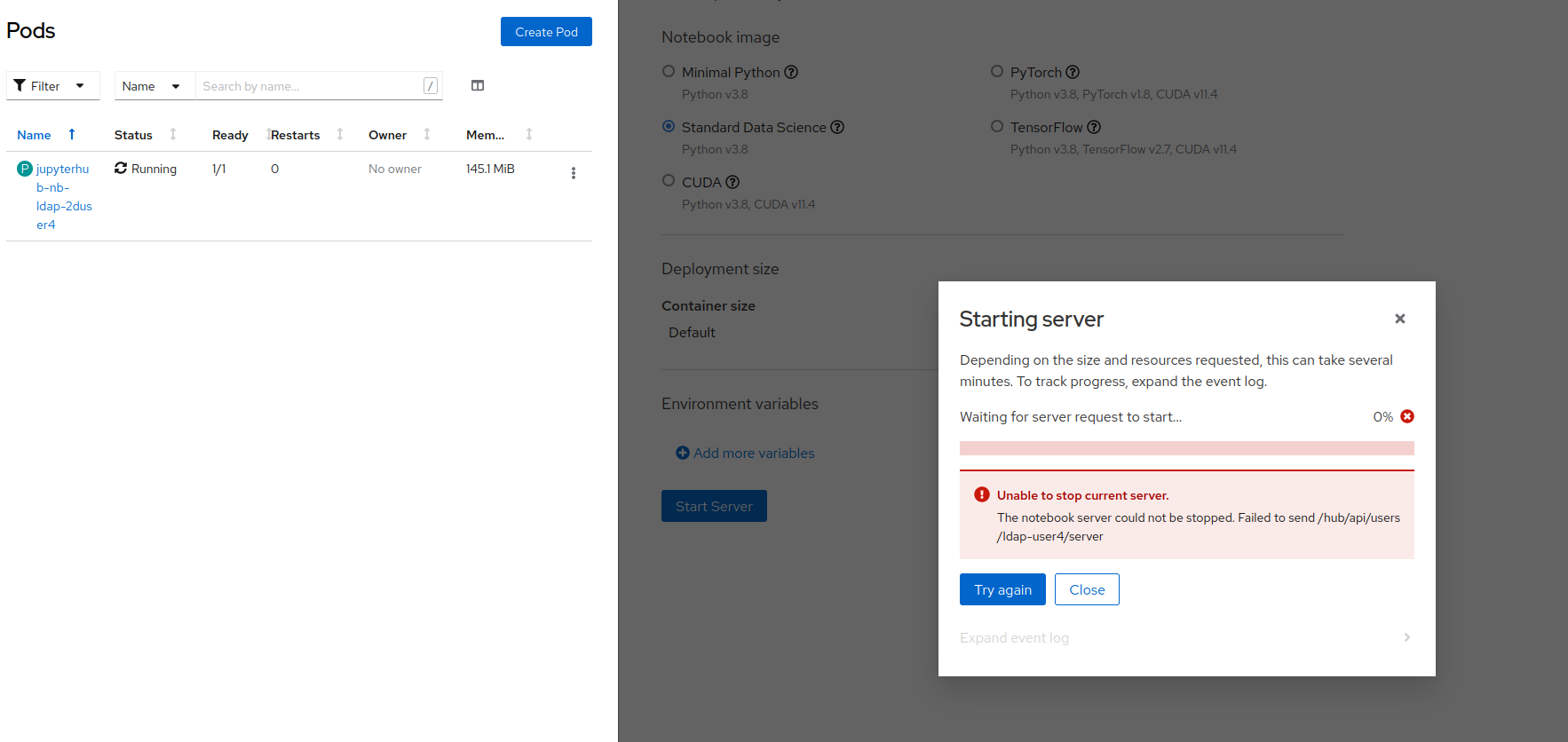
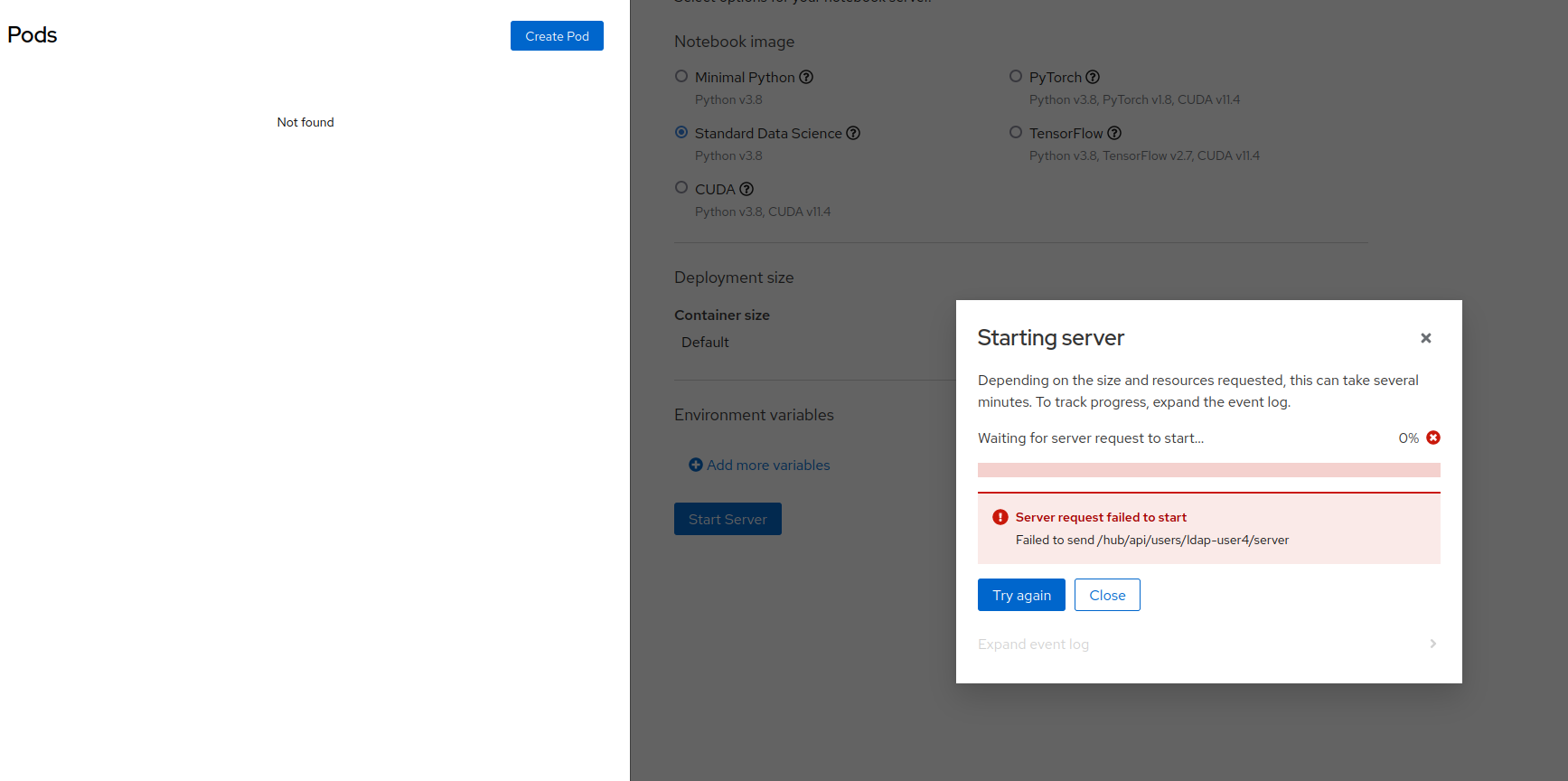
Trying to manually delete the pod to unblock the user does not solve this issue, and even after the pod has been deleted the user is shown the same two error messages:
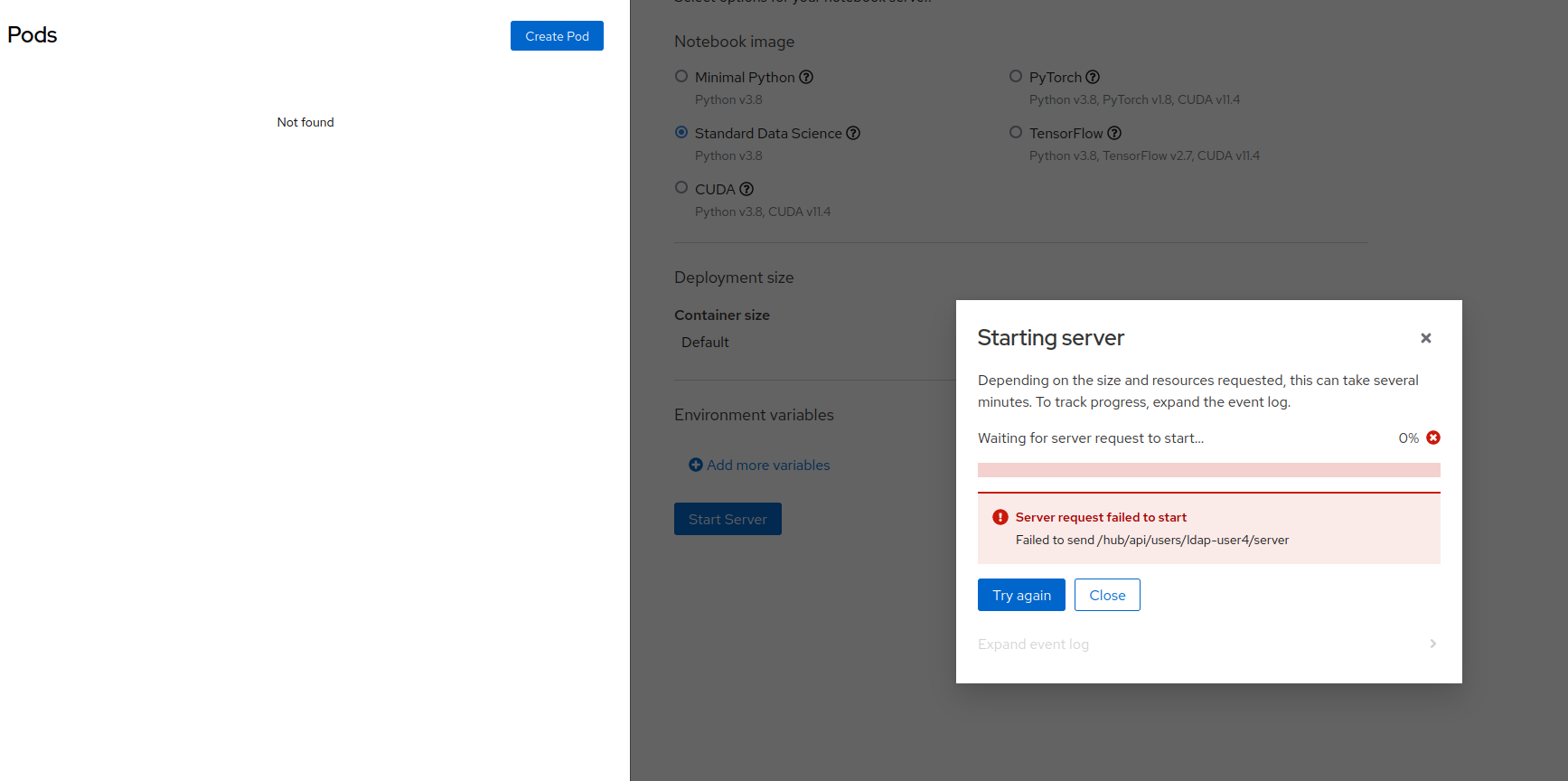
Prerequisites (if any, like setup, operators/versions):
RHODS 1.7.0-5 on OSD running OCP 4.9
Steps to Reproduce
- Start spawning a JL server
- Kill JH leader pod
- Try reloading the page or clicking "Try Again" after the new leader is elected
Actual results:
User is stuck with error messages, does not get redirected to their running server. Furthermore, even after the pod is deleted manually, the user is still stuck with the same error messages.
Expected results:
User redirected to their server after the new leader pod is elected, ideally without having to reload the spawner page.
Reproducibility (Always/Intermittent/Only Once):
Always
Build Details:
RHODS 1.7.0-5 on OSD running OCP 4.9
Workaround:
No known workaround, user has to wait for 10 minutes to be unblocked.