-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
RHODS_1.1_GA
-
3
-
False
-
False
-
None
-
No
-
-
-
-
-
-
No
-
-
Bug Fix
-
Done
-
No
-
Yes
-
None
-
MODH Sprint 31, MODH Sprint 32, MODH Sprint 33, MODH Sprint 34
Description of problem:
If the jupyterhub leader pod dies while a jupyterlab server is spawning, the user will never be able to access the server (although the server pod is running in the rhods-notebooks namespace).
Refreshing the page will empty the progress bar for the spawn and remove all events, and the same happens if clicking on the JupyterHub logo on the upper left.
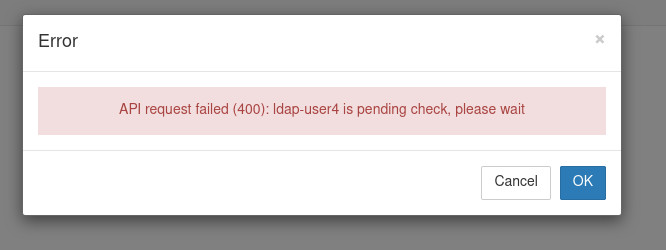
Clicking on the `Home` button next to the logo brings the user to the "Hub Control Panel" with the "Stop My Server"/"My Server" buttons; clicking "My Server" will bring the user back to the progress bar page, clicking "Stop My Server" opens an error pop-up saying:
API request failed (400): {username} is pending check, please wait
which can only be closed. The user is stuck waiting until the server pod is killed by openshift, at which point they will be able to get to the spawner page again.
If the leader pod dies at around the same time the server is ready (i.e. below the progress bar the message "Server ready at /user/{username}/" is shown, the page is trying to redirect to the JL server) the user will be served a 504 Gateway Timeout error page. Refreshing the page will bring the user into the scenario described above.
Prerequisites (if any, like setup, operators/versions):
RHODS 1.1.1-41 on OSD
Steps to Reproduce
- Install RHODS
- Wait for JH to be online, leader pod is elected
- Start spawning a JL server with any image
- Kill/Restart the leader pod while the spawn is in progress (or almost finished for the last paragraph)
Actual results:
The user is never able to reach the spawned server (which is running in its own pod). The user cannot get back to the spawner page until the timeout ends (standard timeout for failed spawns? Not sure, either way the server pod is destroyed after a few minutes of waiting)
Expected results:
User should be able to reach their server even if the leader pod dies during the spawn process. Alternatively, they should be able to kill the server and get back to the spawner without waiting for the timeout
Reproducibility (Always/Intermittent/Only Once):
Always
Build Details:
RHODS 1.1.1-41 on ODS
Additional info:
Attaching the logs for a couple of spawned server pods which contain some error messages; I am almost certain the second pod has an error tied to the leader JH pod not being available, not sure about the other.
- is related to
-
RHODS-2231 [Spike] Investigate possible fix for Gateway Timeout error during server spawn (HA)
-

- New
-
- mentioned on