-
Bug
-
Resolution: Not a Bug
-
 Normal
Normal
-
None
-
RHODS_1.1_GA
-
None
-
False
-
False
-
N/A
-
-
-
-
-
-
No
-
No
-
N/A
-
None
-
Description of problem:
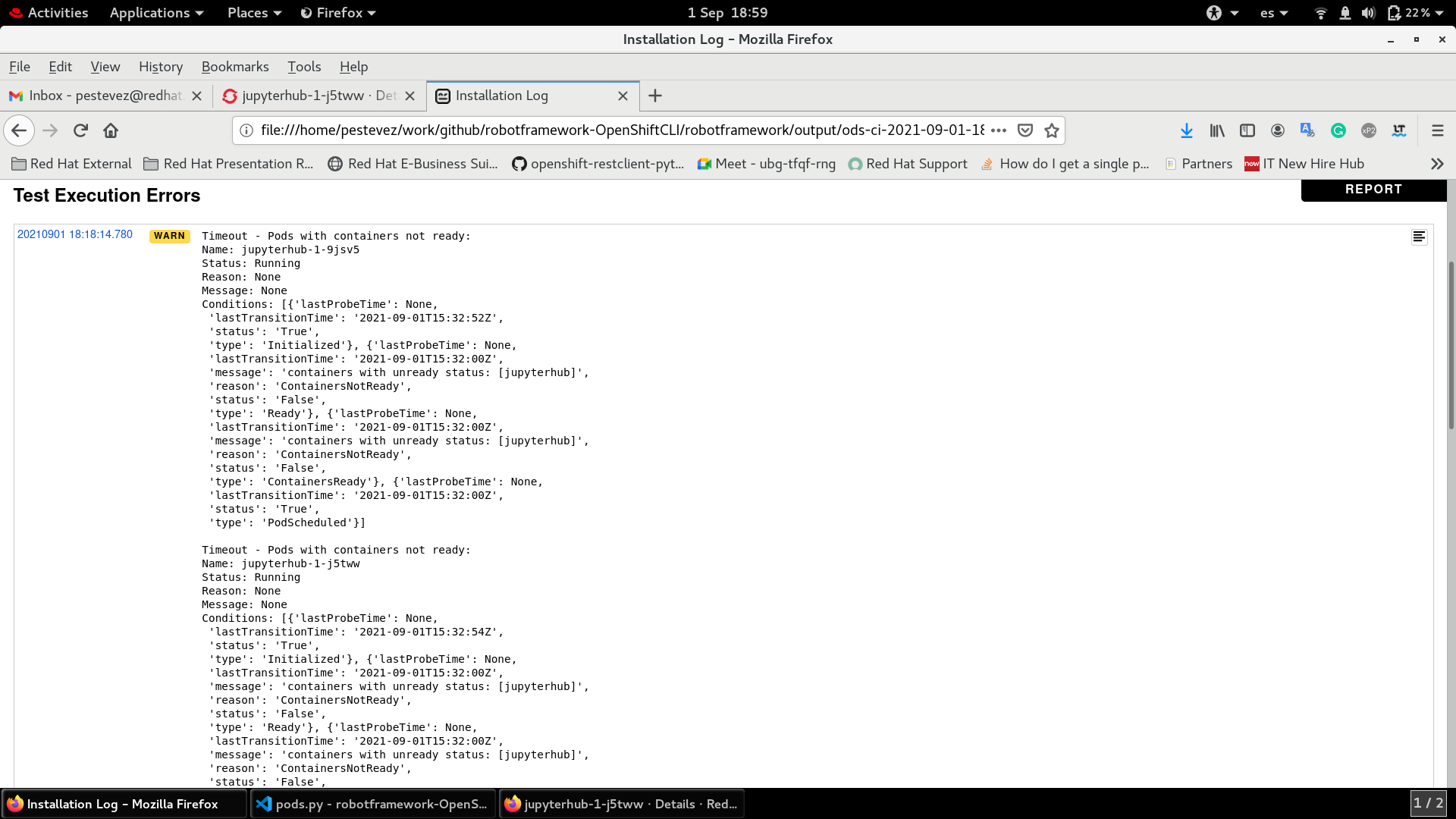
After installing RHODS version 1.1.1-21 only the leader of Jupyterhub pods have all containers in ready status, the other two pods have one container with status ContainersNotReady.
Looking into the logs of the leader pod, this message appears:
leaderelection.go:253] error retrieving endpoint: Get "https://172.30.0.1:443/api/v1/namespaces/redhat-ods-applications/endpoints/jupyterhub-ha-election": http2: no cached connection was available
Looking the events of the pods with Containersnotready status there is this message:
Readiness probe failed: dial tcp 10.129.2.66:8081: connect: connection refused
and looking in the logs this one:
jupyterhub-1-vjwsj is the leader
I0901 15:32:55.041204 1 leaderelection.go:296] lock is held by jupyterhub-1-vjwsj and has not yet expired
I've seen the same behaviour in two differents OSD clusters
Prerequisites (if any, like setup, operators/versions):
OSD fresh installation
Steps to Reproduce
- Install rhods 1.1.1-21
Actual results:
Some Jupyterhub pods are in ContainersNotReady Status
Expected results:
All containers are up and running in the jupyterhub pods
Reproducibility (Always/Intermittent/Only Once):
Always