-
Bug
-
Resolution: Not a Bug
-
 Normal
Normal
-
None
-
None
-
False
-
False
-
None
-
No
-
-
-
-
-
-
No
-
No
-
N/A
-
None
-
Description of problem:
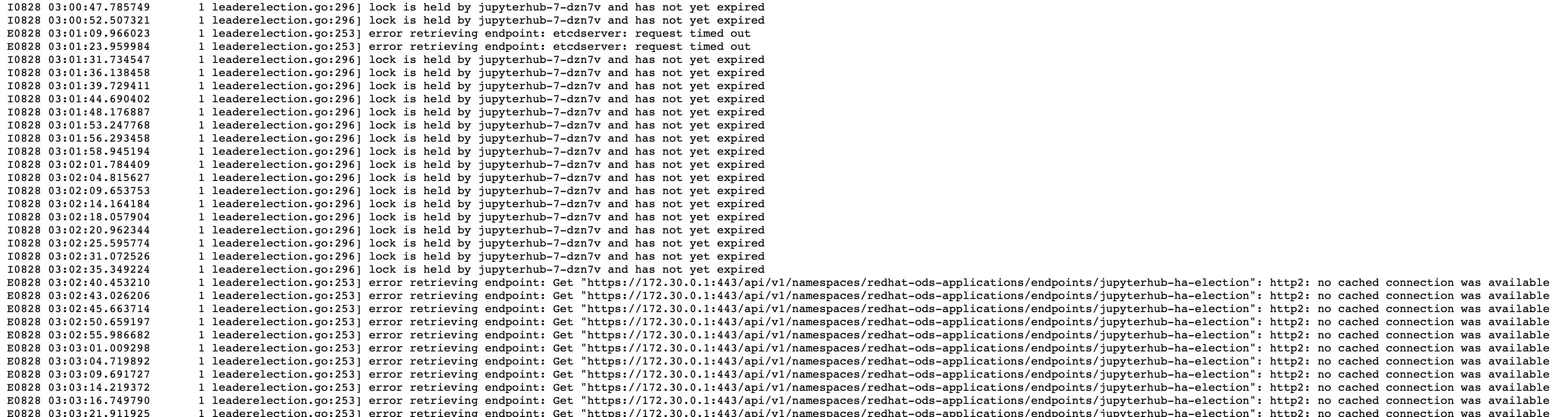
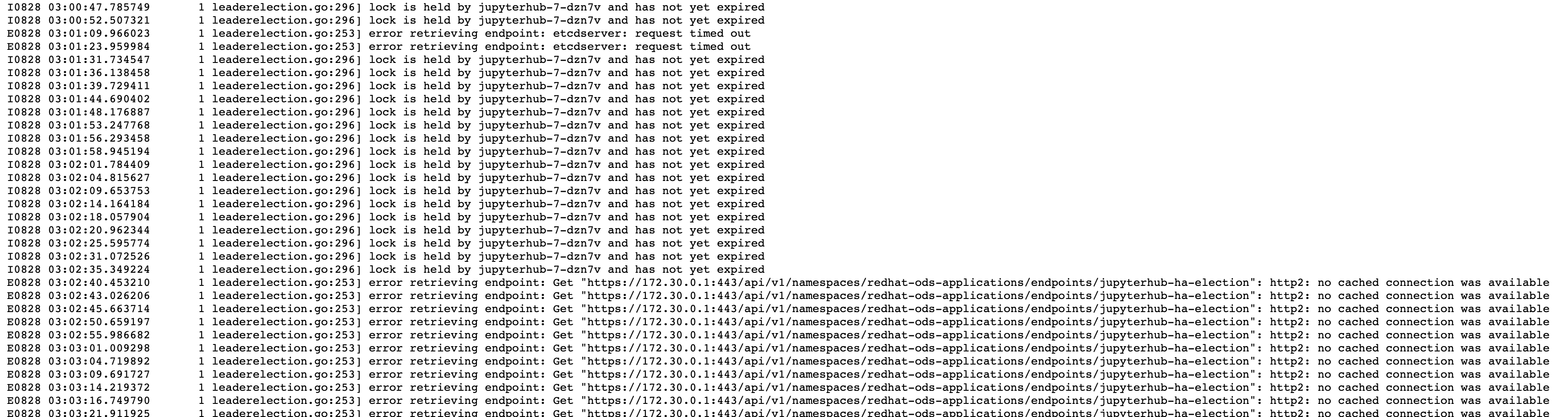
After an extreme CPU pressure that affected etcd, the sidecar container' script for the leader election stopped working, displaying the following message:
Prerequisites (if any, like setup, operators/versions):
This happened in my OSIA cluster with OpenShift 4.x.

Steps to Reproduce
- Install the RHODS operator in the Cluster.
- Force a CPU outage that affects etcd (mine happened due to odh-dashboard issues).
- Wait until all three sidecar containers fail and display that message.
- Restart container to check if it still works.
E0828 03:02:40.453210 1 leaderelection.go:253] error retrieving endpoint: Get "https://172.30.0.1:443/api/v1/namespaces/redhat-ods-applications/endpoints/jupyterhub-ha-election": http2: no cached connection was available
Actual results:
After restarting the sidecar container (restarting only the container, not killing the pod), the script worked again.
Expected results:
The Leader Election script should always work. This shouldn't be happening to the container.