-
Bug
-
Resolution: Done
-
 Blocker
Blocker
-
RHODS_1.1_GA
-
2
-
False
-
False
-
None
-
No
-
-
-
-
-
-
1.1.1-34
-
No
-
-
No
-
Yes
-
None
-
-
IDH Sprint 7, IDH Sprint 8, IDH Sprint 9
As we have implemented High Availability on Jupyterhub, we shifted from 1 to 3 containers with the Leader Election strategy.
With this implementation, we could bump into inconsistencies given that one Pod could be thinking he's still the leader elected, but others could have replaced it due to network problems.
Implement a check to detect if a pod running is still the leader elected, and if not, delete it.
In the following diagram we can detail the error:
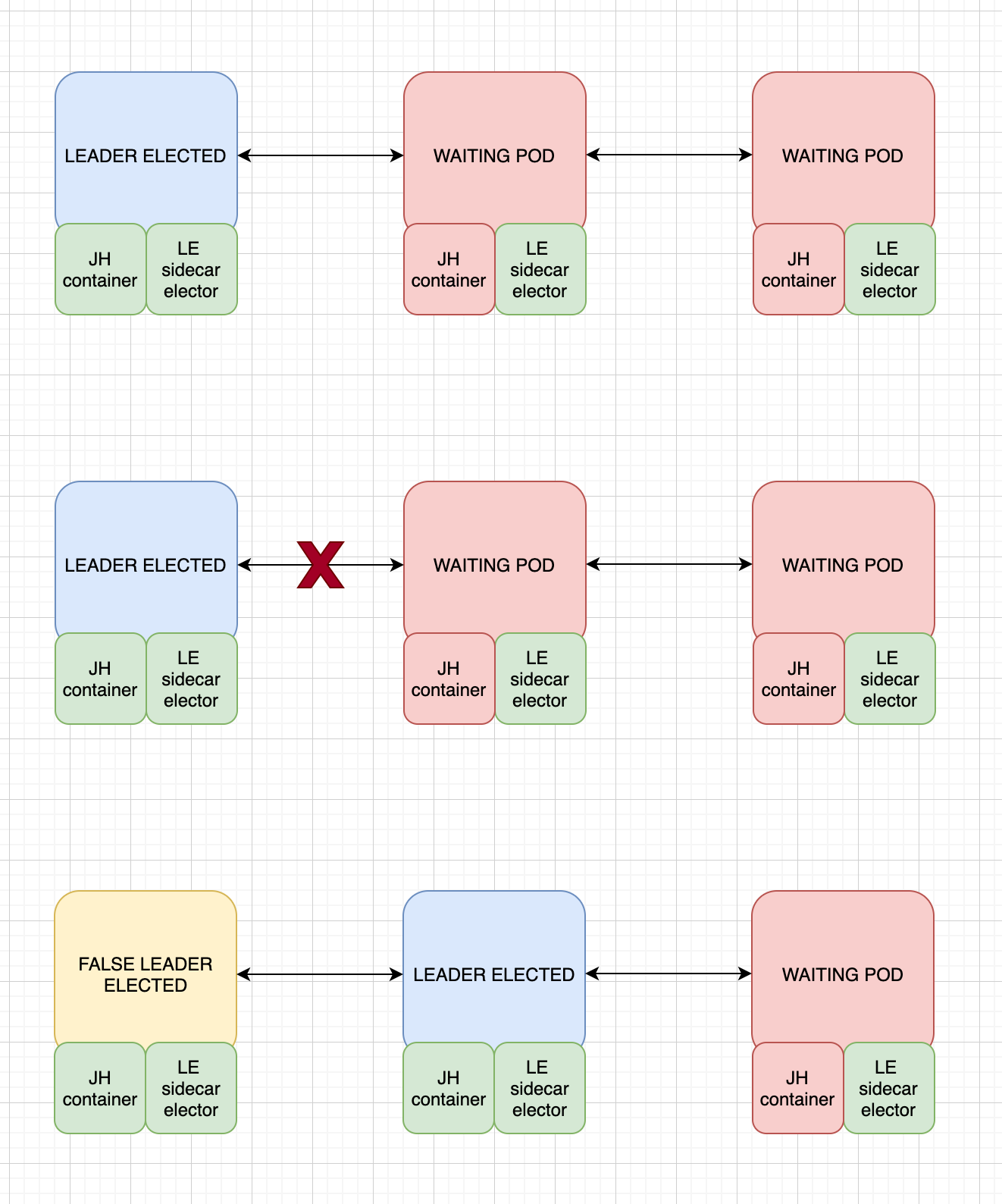
If somehow the pods bump into network problems, it might trigger a new election while the old container still thinks it's the leader, once the network issues are fixed, there will be two leaders, as there is no mechanism to probe the leader election an restart the pod.
[SPIKE] We have already thought about using a liveness probe script -> https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
The main issue with this exploration is that we could isolate the pod with the readinessProbe (not passing traffic ) and restart the container with the livenessProbe, but all of this only works on the container level, not the pod level. This won't acknowledge the problem in the sidecar container of the image.

- is duplicated by
-
-
- Closed
-
- relates to
-
-
- Closed
-