-
Bug
-
Resolution: Done
-
 Critical
Critical
-
RHODS_1.1_GA
-
2
-
False
-
False
-
- If exists, I would like to have a link to a user document with the minimal cluster requirements
- If my actual cluster size is supported, a fix to the CUDA build process to make it succeed without manual interventions
-
No
-
-
-
-
-
-
-
No
-
Undefined
-
Yes
-
Yes
-
None
-
-
MODH Sprint 27, MODH Sprint 28, MODH Sprint 29
Note: this bug is probably the same as RHODS-1526, but that one is in a PSI cluster and this one is in a OpenShift Dedicated cluster
Description of problem:
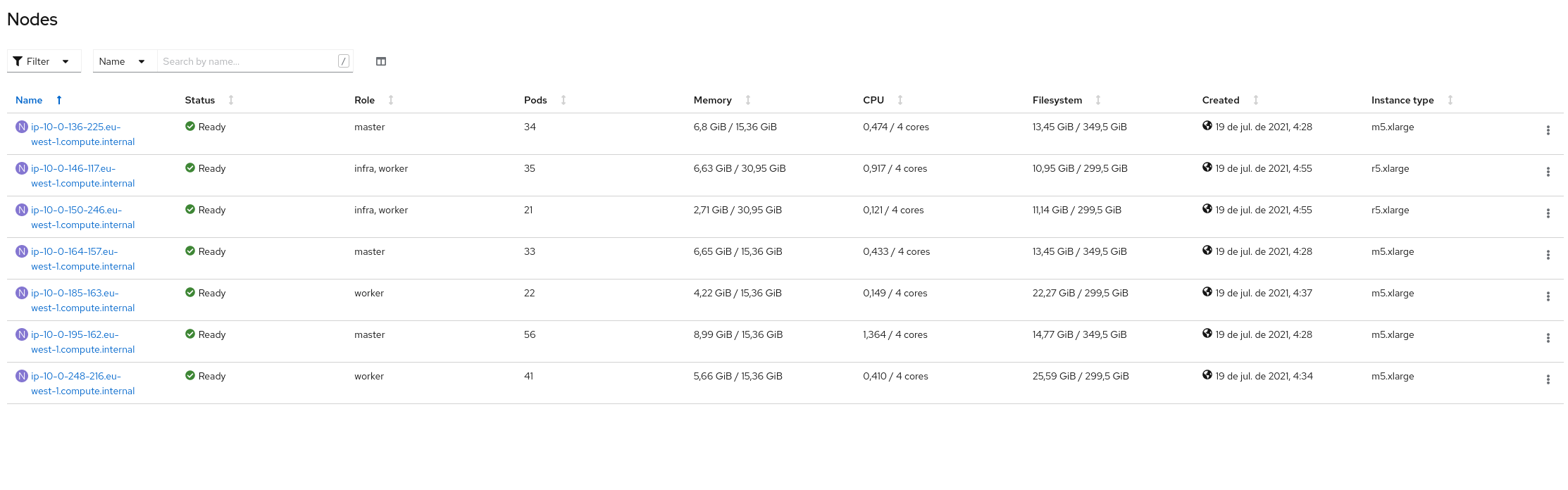
We have a cluster in OpenShift Dedicated with:
- 3 master nodes (m5.xlarge: 4 cpu 16GB RAM)
- 2 infra,worker nodes (r5.xlarge: 4cpu 32GB RAM)
- 3 worker nodes (m5.xlarge: 4 cpu 16GB RAM)
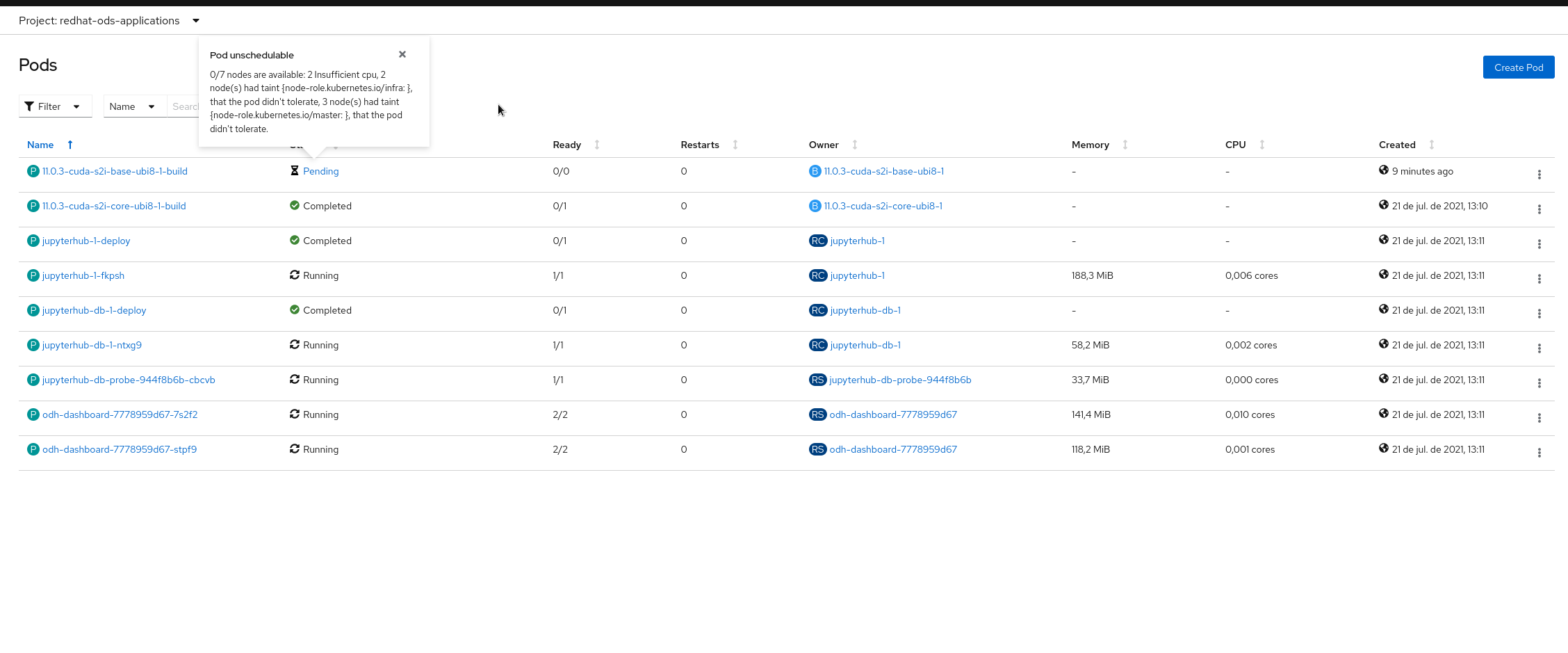
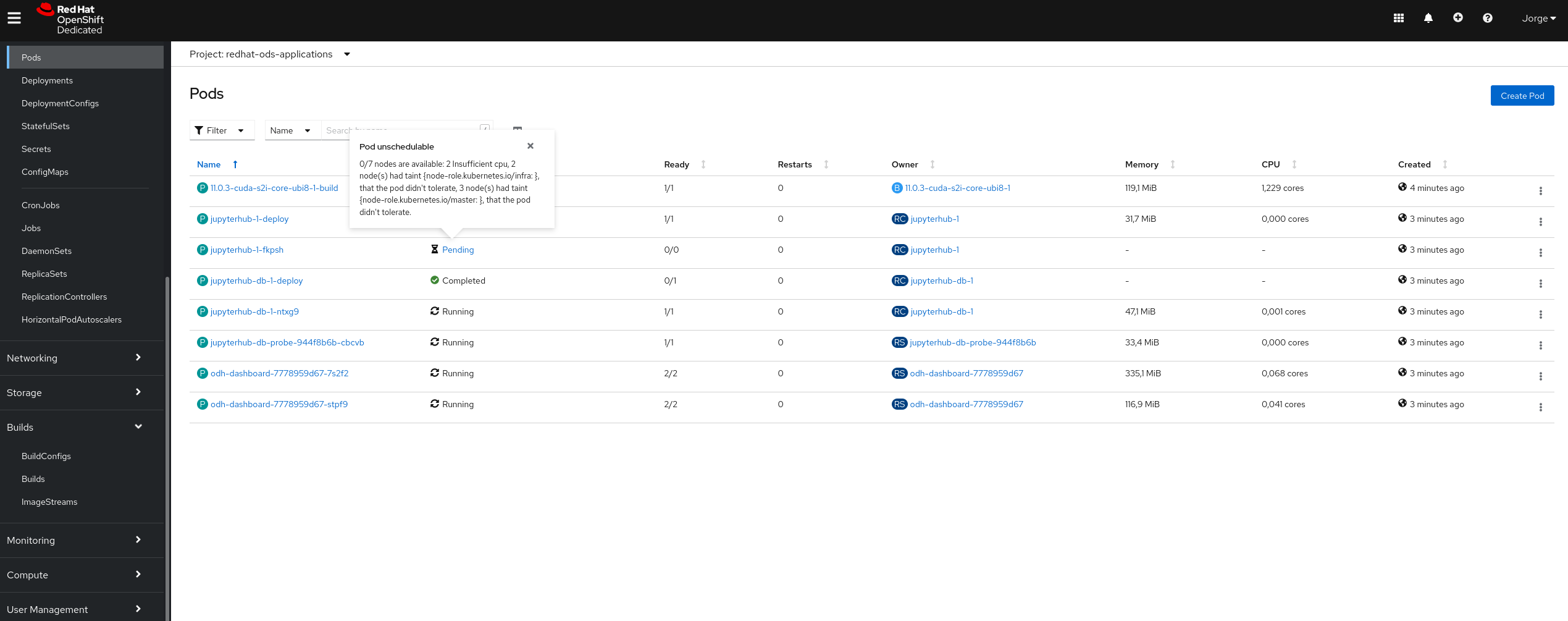
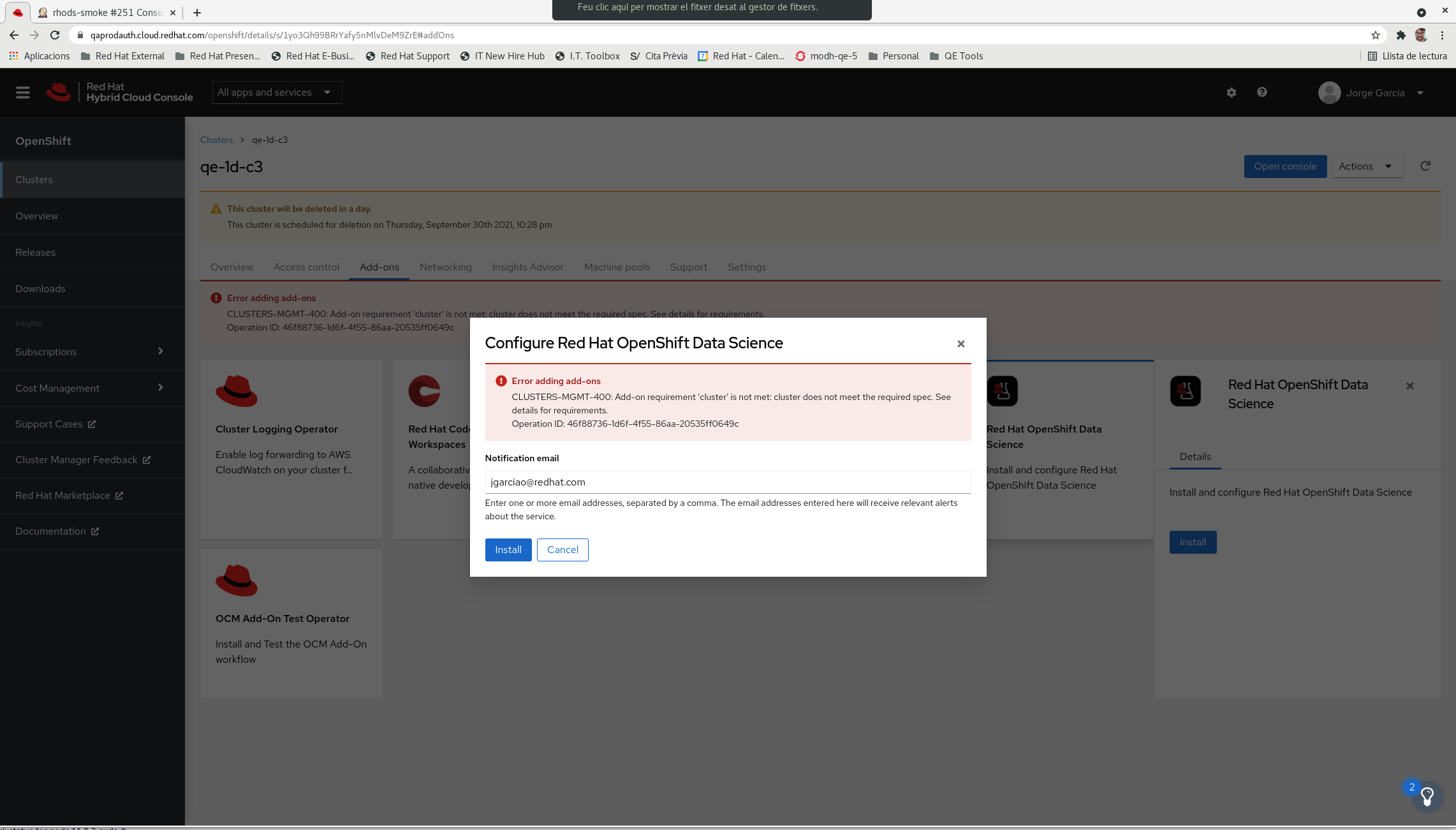
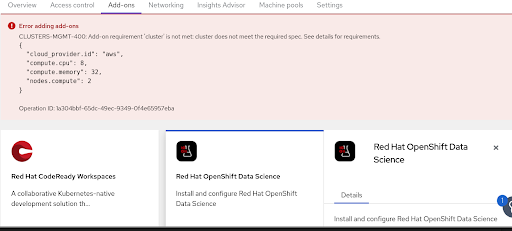
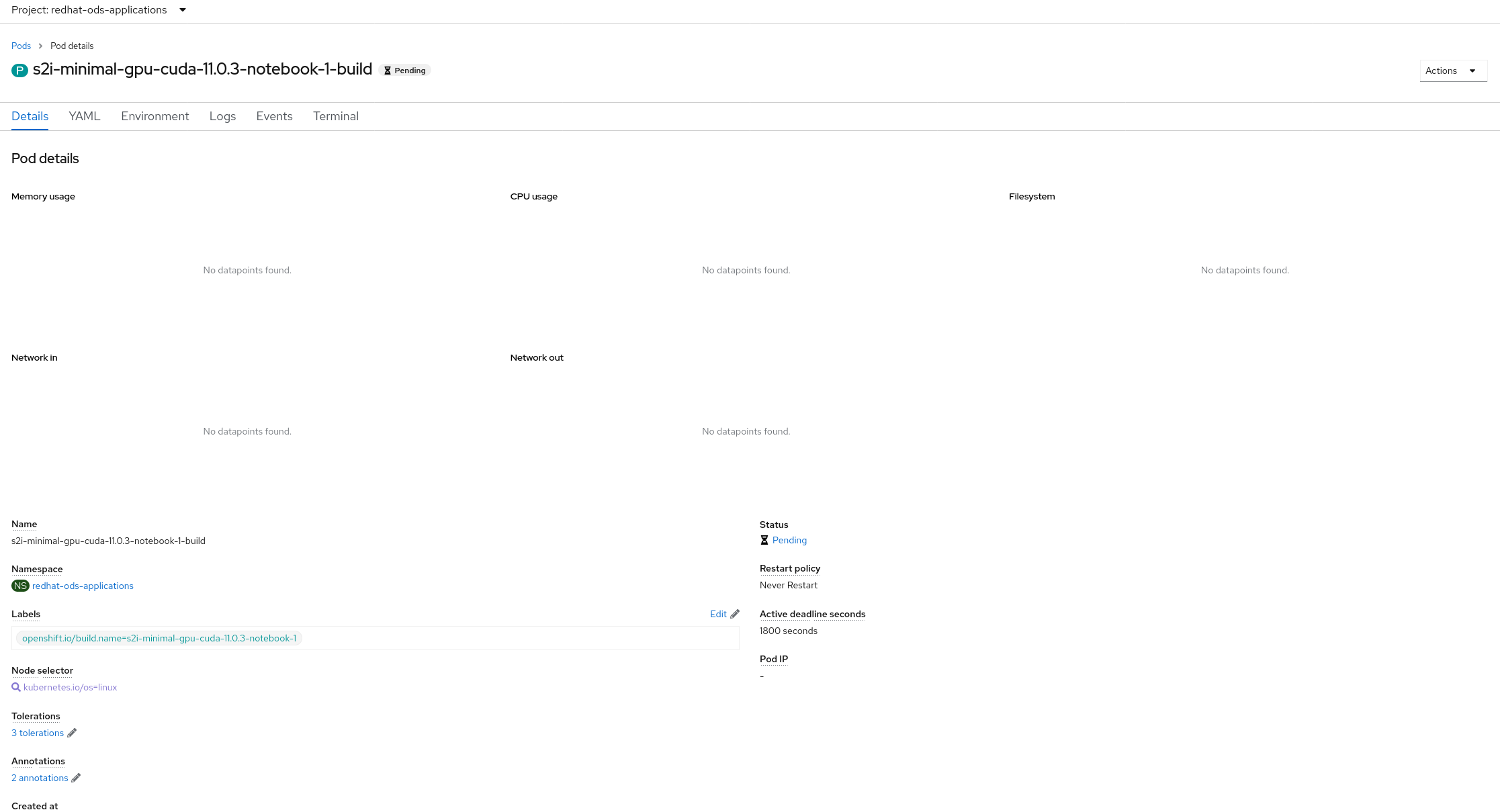
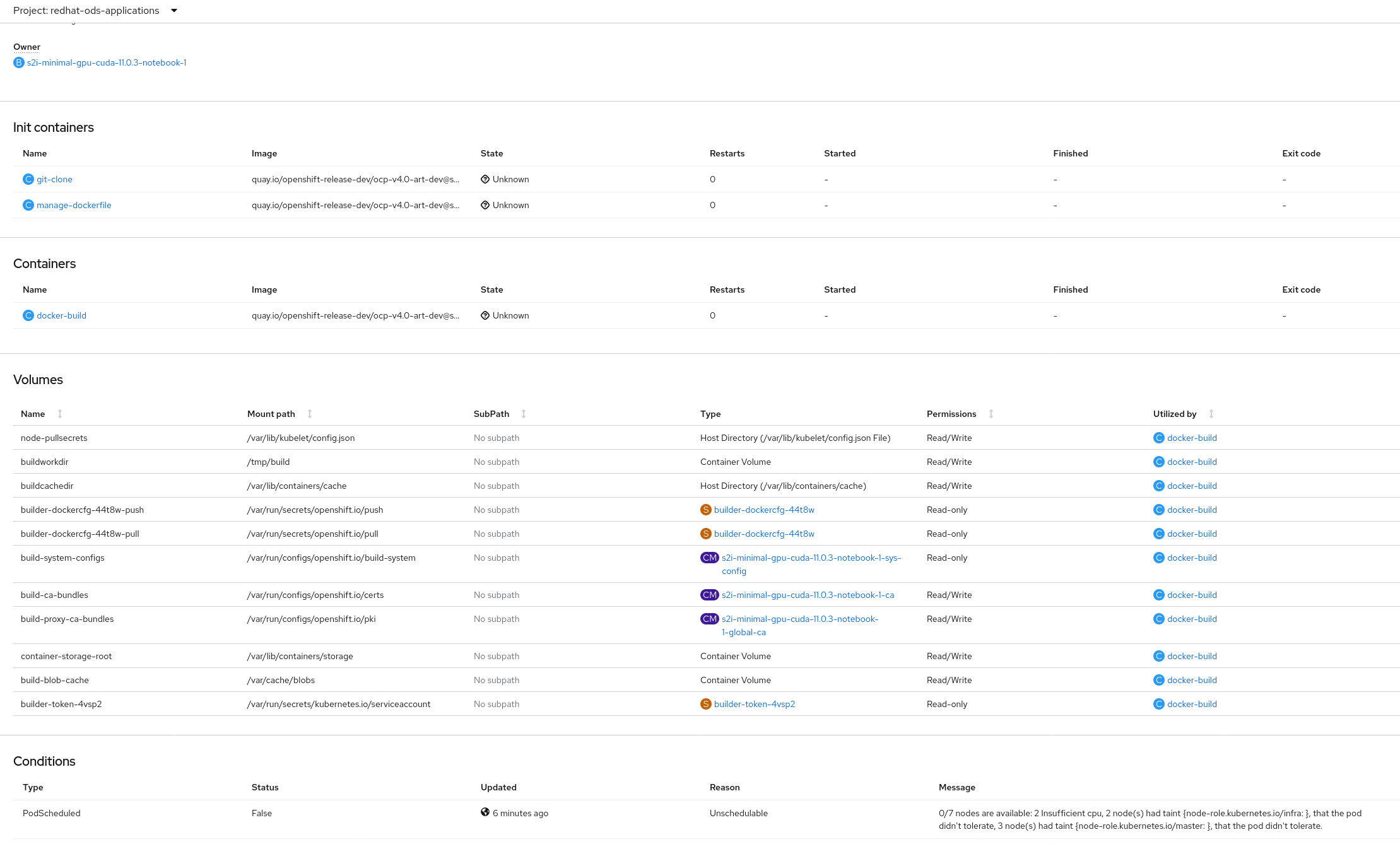
When we install RHODS using the Add-On in OpenShift Cluster Manager the CUDA builds are not able to finish due to insufficient cpu (see attached screenshots)
Prerequisites (if any, like setup, operators/versions):
Steps to Reproduce
- Login to https://qaprodauth.cloud.redhat.com
- Go to OpenShift OpenShift Cluster Manager
- Click into an existing cluster
- Add-ons
- Install RHODS
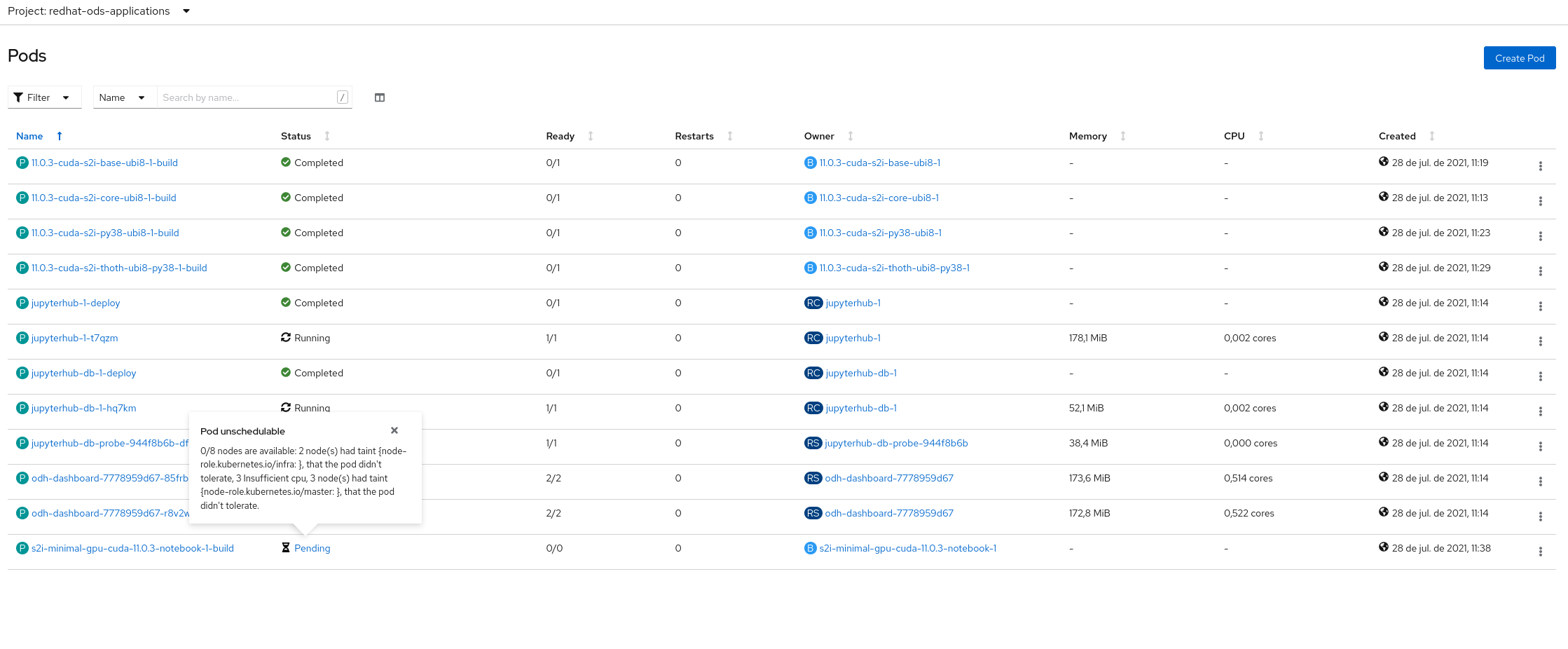
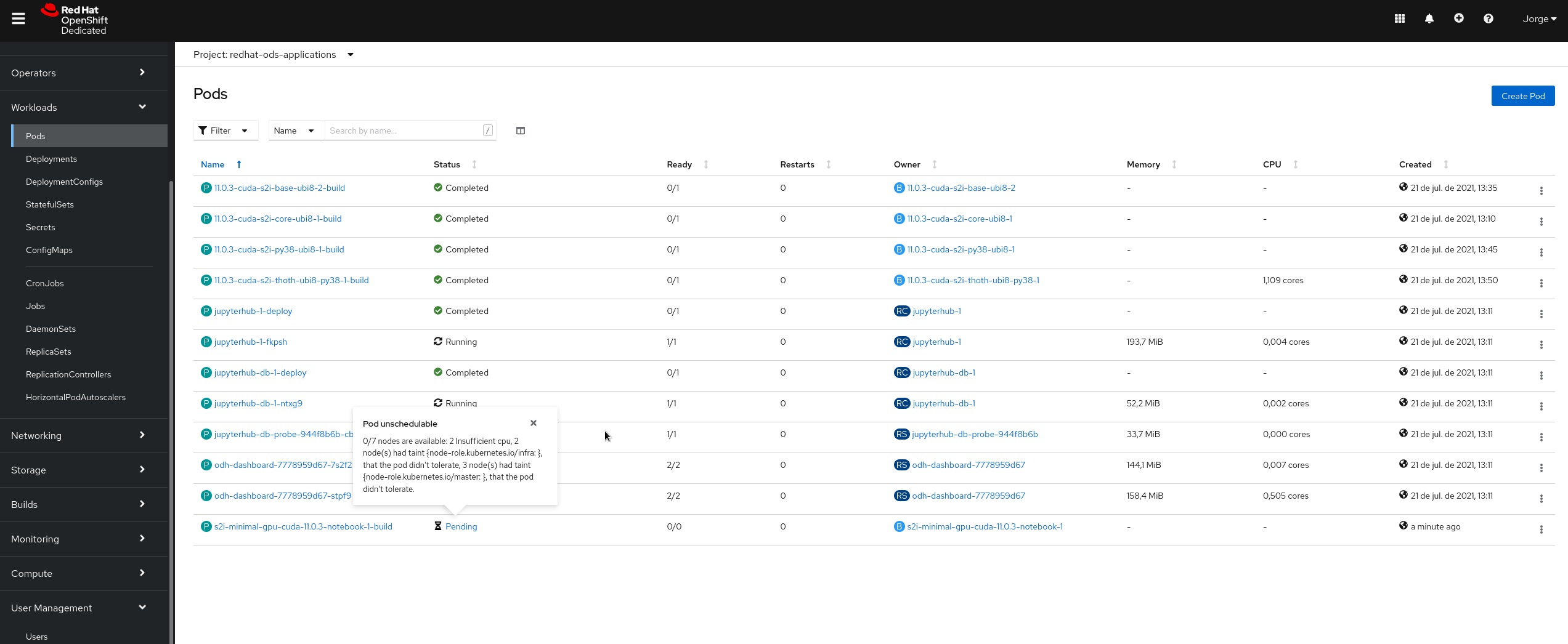
- While installing, log-in into the cluster as cluster-admin and go to Workload > Pods
- Project: redhat-ods-applications
- Check status for pods 11.0.3-cuda-*
- After a while after starting the installation, this pods should be Running or Completed, but usually they are Pending because of "Pod unschedulable: 2 Insufficient cpu ..." (see attached screenshot)
Sometimes, to make the pod start I scale down the Grafana pods from 2 to 0. Freeing this 2 slots makes the CUDA build start and finish successfully.
For the last 3 CUDA builds (s2i-minimal-gpu-cuda, s2i-pytorch-cuda and s2i-tensorflow-gpu) this is not enough because they require even more cpus. What I do to make those builds start is to manually modify their BuildConfig to reduce the amount of requested cpus and start a new build after:
Original BuildConfig:
resources:
limits:
cpu: '4'
memory: 8Gi
requests:
cpu: '2'
memory: 6Gi
Modified BuildConfig:
resources:
limits:
cpu: '4'
memory: 8Gi
requests:
cpu: '1'
memory: 6Gi
In Getting started with Red Hat OpenShift Data Science I haven't seen any section where it says what is the minimal cluster size required to install and run RHODS, but I think it should be specified there.
Also, I think the CUDA builds should be somehow optimized to reduce the amount of simultaneous cpus requested to avoid this problem
Actual results:
Expected results:
Reproducibility (Always/Intermittent/Only Once):
Build Details: RHODS 1.0.17 in OpenShift Dedicated. It also happened in previous versions
Additional info:
- is related to
-
-

- Closed
-
-
-
- Closed
-
- mentioned on
