-
Story
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
None
Story (Required)
As a developer who is going to use the Software Templates and create a Component, I would like to use the vLLM model server. But I dont really know how much system specs I need to run a vLLM model.
Background (Required)
Currently when we choose vLLM, we just say:
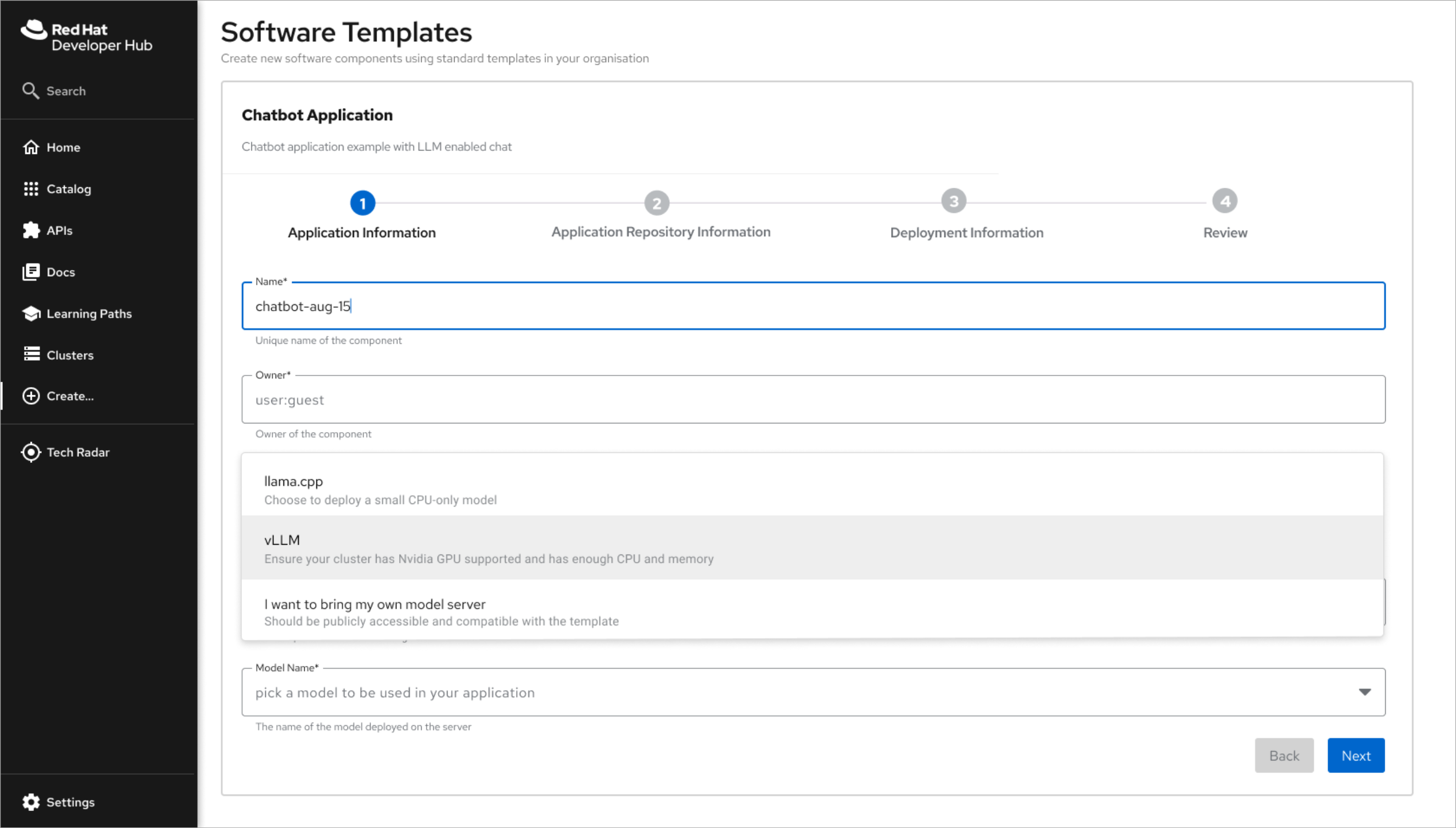
If you choose vLLM, ensure your cluster has Nvidia GPU supported, and is with enough cpu and memory
We need to be a bit more specifc according to the UX, to help user understand the requirements.
Out of scope
<Defines what is not included in this story>
Approach (Required)
- Figure out what the bare minimum is to run the vLLM model servers
- Since we use the vLLM image uay.io/rh-aiservices-bu/vllm-openai-ubi9:0.4.2, we need to figure out if there is anything specific for this image
Dependencies
<Describes what this story depends on. Dependent Stories and EPICs should be linked to the story.>
Acceptance Criteria (Required)
- Figure out the bare minimum spec requirements like CPU, memory and GPU to run the vLLM model servers
- Follow UX recommendation of having the Model Server desc to be under each name in the dropbox rather than below the dropbox field
Done Checklist
![]() Code is completed, reviewed, documented and checked in
Code is completed, reviewed, documented and checked in
![]() Unit and integration test automation have been delivered and running cleanly in continuous integration/staging/canary environment
Unit and integration test automation have been delivered and running cleanly in continuous integration/staging/canary environment
![]() Continuous Delivery pipeline(s) is able to proceed with new code included
Continuous Delivery pipeline(s) is able to proceed with new code included
![]() Customer facing documentation, API docs, design docs etc. are produced/updated, reviewed and published
Customer facing documentation, API docs, design docs etc. are produced/updated, reviewed and published
![]() Acceptance criteria are met
Acceptance criteria are met
![]() If the Grafana dashboard is updated, ensure the corresponding SOP is updated as well
If the Grafana dashboard is updated, ensure the corresponding SOP is updated as well