-
Bug
-
Resolution: Won't Do
-
 Normal
Normal
-
None
-
rhelai-1.5.1
-
None
-
False
-
-
False
-
-
-
Moderate
To Reproduce Steps to reproduce the behavior:
Steps to reproduce the behaviour:
1. Bring up RHELAI on top of Azure AMD MI300X *8 cores GPU with of 1.5.1-2 ( note: bootc switch done from 1.4)
2. Now Rhel AI is running with 1.5.1-2
3. Follow the instructions from this snippet until ilab model chat- https://gitlab.cee.redhat.com/-/snippets/9540
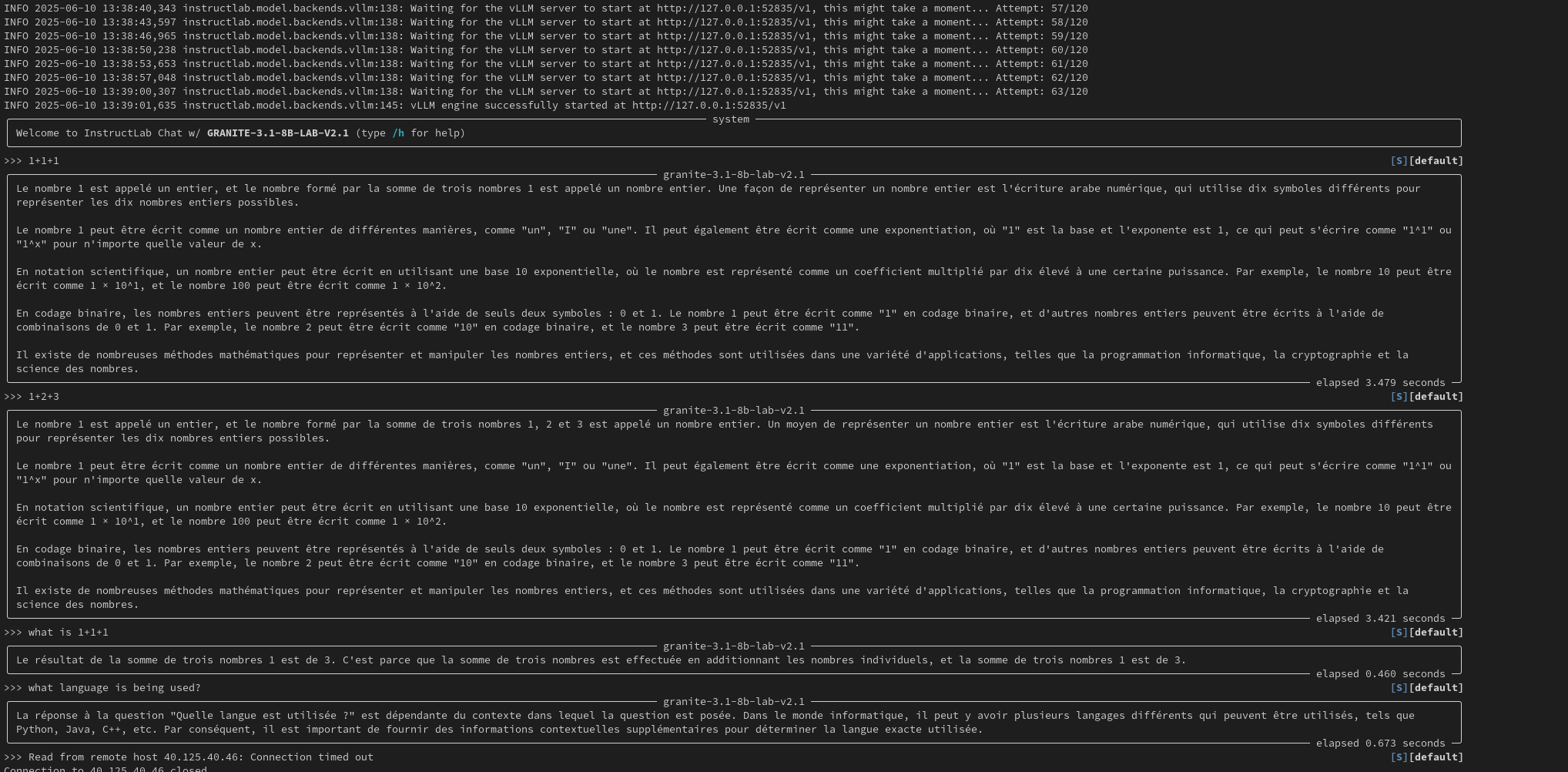
4. in Ilab Model chat the observation is prompt response is in different language(spanish here)
5. .config and .local is attached
6. Please refer chat log: .local/share/instructlab/chatlogs/chat_2025-06-10T13_39_01.log
unable to attach logs: https://drive.google.com/file/d/1y7yOBO_hYjMKm2FAzNedFNgjCzmXzKbV/view?usp=sharing
Expected behavior
- Proper prompt response
Screenshots
- Attached below
2. ilab config show :
bash-5.1# cat ilab-config-show time="2025-06-11T14:37:42Z" level=warning msg="The input device is not a TTY. The --tty and --interactive flags might not work properly" # Chat configuration section. chat: # Predefined setting or environment that influences the behavior and responses of # the chat assistant. Each context is associated with a specific prompt that # guides the assistant on how to respond to user inputs. Available contexts: # default, cli_helper. # Default: default context: default # Directory where chat logs are stored. # Default: /var/home/azureuser/.local/share/instructlab/chatlogs logs_dir: /var/home/azureuser/.local/share/instructlab/chatlogs # The maximum number of tokens that can be generated in the chat completion. Be # aware that larger values use more memory. # Default: None max_tokens: # Model to be used for chatting with. # Default: /var/home/azureuser/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf model: /var/home/azureuser/.cache/instructlab/models/granite-3.1-8b-lab-v2.1 # Filepath of a dialog session file. # Default: None session: # Controls the randomness of the model's responses. Lower values make the output # more deterministic, while higher values produce more random results. # Default: 1.0 temperature: 1.0 # Enable vim keybindings for chat. # Default: False vi_mode: false # Renders vertical overflow if enabled, displays ellipses otherwise. # Default: True visible_overflow: true # Evaluate configuration section. evaluate: # Base taxonomy branch # Default: None base_branch: # Base model to compare with 'model' for mt_bench_branch and mmlu_branch. # Default: instructlab/granite-7b-lab base_model: /var/home/azureuser/.cache/instructlab/models/granite-3.1-8b-starter-v2.1 # Taxonomy branch containing custom skills/knowledge that should be used for # evaluation runs. # Default: None branch: # Settings to run DK-Bench against a file of user created questions, reference # answers, and responses. If responses are not provided they are generated from a # model dk_bench: # File with questions and reference answers used for evaluation during DK-Bench. # The file must be valid a '.jsonl' file with the fields 'user_input' and # 'reference' in each entry # Default: None input_questions: # Judge model for DK-Bench. # Default: gpt-4o judge_model: gpt-4o # Directory where DK-Bench evaluation results are stored. # Default: /var/home/azureuser/.local/share/instructlab/internal/eval_data/dk_bench output_dir: /var/home/azureuser/.local/share/instructlab/internal/eval_data/dk_bench # Comma-separated list of file formats for results of the DK-Bench evaluation. Ex: # 'csv,jsonl'. Valid options in the list are csv, jsonl, and xlsx. If this option # is not provided the results are written as a .jsonl file # Default: jsonl output_file_formats: jsonl # Number of GPUs to use for running evaluation. # Default: None gpus: 1 # MMLU benchmarking settings mmlu: # Batch size for evaluation. Valid values are a positive integer or 'auto' to # select the largest batch size that will fit in memory. # Default: auto batch_size: auto # Number of question-answer pairs provided in the context preceding the question # used for evaluation. # Default: 5 few_shots: 5 # Settings to run MMLU against a branch of taxonomy containing custom # skills/knowledge used for training. mmlu_branch: # Directory where custom MMLU tasks are stored. # Default: /var/home/azureuser/.local/share/instructlab/datasets tasks_dir: /var/home/azureuser/.local/share/instructlab/datasets # Model to be evaluated # Default: None model: # Multi-turn benchmarking settings for skills. mt_bench: # Judge model for MT-Bench. # Default: prometheus-eval/prometheus-8x7b-v2.0 judge_model: /var/home/azureuser/.cache/instructlab/models/prometheus-8x7b-v2-0 # Number of workers to use for evaluation with mt_bench or mt_bench_branch. Must # be a positive integer or 'auto'. # Default: auto max_workers: auto # Directory where MT-Bench evaluation results are stored. # Default: /var/home/azureuser/.local/share/instructlab/internal/eval_data/mt_bench output_dir: /var/home/azureuser/.local/share/instructlab/internal/eval_data/mt_bench # Settings to run MT-Bench against a branch of taxonomy containing custom # skills/knowledge used for training mt_bench_branch: # Judge model for MT-Bench-Branch. # Default: prometheus-eval/prometheus-8x7b-v2.0 judge_model: /var/home/azureuser/.cache/instructlab/models/prometheus-8x7b-v2-0 # Directory where MT-Bench-Branch evaluation results are stored. # Default: /var/home/azureuser/.local/share/instructlab/internal/eval_data/mt_bench_branch output_dir: /var/home/azureuser/.local/share/instructlab/internal/eval_data/mt_bench_branch # Path to where base taxonomy is stored. # Default: /var/home/azureuser/.local/share/instructlab/taxonomy taxonomy_path: /var/home/azureuser/.local/share/instructlab/taxonomy # System prompt for model getting responses during DK-Bench. # Default: None system_prompt: # Temperature for model getting responses during DK-Bench. Temperature controls # the randomness of the model's responses. Lower values make the output more # deterministic, while higher values produce more random results. # Default: 0.0 temperature: 0.0 # General configuration section. general: # Debug level for logging. # Default: 0 debug_level: 0 # Log format. https://docs.python.org/3/library/logging.html#logrecord-attributes # Default: %(levelname)s %(asctime)s %(name)s:%(lineno)d: %(message)s log_format: '%(levelname)s %(asctime)s %(name)s:%(lineno)d: %(message)s' # Log level for logging. # Default: INFO log_level: INFO # ID of the student model to be used for training. # Default: None student_model_id: granite-3.1-starter-v2 # ID of the teacher model to be used for data generation. # Default: None teacher_model_id: # Use legacy IBM Granite chat template (default uses 3.0 Instruct template) # Default: False use_legacy_tmpl: false # Generate configuration section. generate: # Number of Batches to send for generation on each core. # Default: 8 batch_size: 256 # Maximum number of words per chunk. # Default: 1000 chunk_word_count: 1000 # The maximum amount of tokens for the model to generate during knowledge # generation. A lower number yields less data but a faster SDG run. It is # reccomended to use this on consumer hardware # Default: 4096 max_num_tokens: 4096 # Teacher model that will be used to synthetically generate training data. # Default: /var/home/azureuser/.cache/instructlab/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf model: /var/home/azureuser/.cache/instructlab/models/mixtral-8x7b-instruct-v0-1 # Number of CPU cores to use for generation. # Default: 10 num_cpus: 2 # Number of instructions to use # Default: -1 # Deprecated: see 'sdg_scale_factor' instead num_instructions: -1 # Directory where generated datasets are stored. # Default: /var/home/azureuser/.local/share/instructlab/datasets output_dir: /var/home/azureuser/.local/share/instructlab/datasets # Data generation pipeline to use. Available: 'simple', 'full', or a valid path to # a directory of pipeline workflow YAML files. Note that 'full' requires a larger # teacher model, Mixtral-8x7b. # Default: full pipeline: /usr/share/instructlab/sdg/pipelines/agentic # The total number of instructions to be generated. # Default: 30 sdg_scale_factor: 30 # Branch of taxonomy used to calculate diff against. # Default: origin/main taxonomy_base: empty # Directory where taxonomy is stored and accessed from. # Default: /var/home/azureuser/.local/share/instructlab/taxonomy taxonomy_path: /var/home/azureuser/.local/share/instructlab/taxonomy # Teacher configuration teacher: # Serving backend to use to host the model. # Default: None # Examples: # - vllm # - llama-cpp backend: vllm # Chat template to supply to the model. Possible values: 'auto'(default), # 'tokenizer', a path to a jinja2 file. # Default: None # Examples: # - auto # - tokenizer # - A filesystem path expressing the location of a custom template chat_template: tokenizer # llama-cpp serving settings. llama_cpp: # Number of model layers to offload to GPU. -1 means all layers. # Default: -1 gpu_layers: -1 # Large Language Model Family # Default: '' # Examples: # - granite # - mixtral llm_family: '' # Maximum number of tokens that can be processed by the model. # Default: 4096 max_ctx_size: 4096 # Directory where model to be served is stored. # Default: /var/home/azureuser/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf model_path: /var/home/azureuser/.cache/instructlab/models/mixtral-8x7b-instruct-v0-1 # Server configuration including host and port. # Default: host='127.0.0.1' port=8000 backend_type='' current_max_ctx_size=4096 server: # Backend Instance Type # Default: '' # Examples: # - llama-cpp # - vllm backend_type: '' # Maximum number of tokens that can be processed by the currently served model. # Default: 4096 current_max_ctx_size: 4096 # Host to serve on. # Default: 127.0.0.1 host: 127.0.0.1 # Port to serve on. # Default: 8000 port: 8000 # vLLM serving settings. vllm: # Number of GPUs to use. # Default: None gpus: 1 # Large Language Model Family # Default: '' # Examples: # - granite # - mixtral llm_family: mixtral # Maximum number of attempts to start the vLLM server. # Default: 120 max_startup_attempts: 120 vllm_args: - --max-num-seqs - '512' - --enable-lora - --enable-prefix-caching - --max-lora-rank - '64' - --dtype - bfloat16 - --lora-dtype - bfloat16 - --fully-sharded-loras - --lora-modules - skill-classifier-v3-clm=/var/home/azureuser/.cache/instructlab/models/skills-adapter-v3 - text-classifier-knowledge-v3-clm=/var/home/azureuser/.cache/instructlab/models/knowledge-adapter-v3 # Metadata pertaining to the specifics of the system which the Configuration is # meant to be applied to. metadata: # Manufacturer, Family, and SKU of the system CPU, ex: Apple M3 Max # Default: None cpu_info: # Amount of GPUs on the system, ex: 8 # Default: None gpu_count: 8 # Family of the system GPU, ex: H100 # Default: None gpu_family: MI300X # Manufacturer of the system GPU, ex: Nvidia # Default: None gpu_manufacturer: AMD # Specific SKU related information about the given GPU, ex: PCIe, NVL # Default: None gpu_sku: models: - # Family the model belongs to. family: llama # Internal ID referring to a particular model from the list. id: llama-3.3 # Path to where the model can be found. Can either be a HF reference or local # filepath. path: /var/home/azureuser/.cache/instructlab/models/meta-llama/Llama-3.3-70B-Instruct # The initial message used to prompt the conversation with this model. E.g. "You # are a helfpul AI assistant..." # Default: None system_prompt: - # Family the model belongs to. family: granite # Internal ID referring to a particular model from the list. id: granite-3.1-starter-v2 # Path to where the model can be found. Can either be a HF reference or local # filepath. path: /var/home/azureuser/.cache/instructlab/models/granite-3.1-8b-starter-v2.1 # The initial message used to prompt the conversation with this model. E.g. "You # are a helfpul AI assistant..." # Default: None system_prompt: You are a Red Hat® Instruct Model, an AI language model developed by Red Hat and IBM Research based on the granite-3.1-8b-base model. Your primary role is to serve as a chat assistant. # RAG configuration section. rag: # RAG convert configuration section. convert: # Directory where converted documents are stored. # Default: /var/home/azureuser/.local/share/instructlab/converted_documents output_dir: /var/home/azureuser/.local/share/instructlab/converted_documents # Branch of taxonomy used to calculate diff against. # Default: origin/main taxonomy_base: origin/main # Directory where taxonomy is stored and accessed from. # Default: /var/home/azureuser/.local/share/instructlab/taxonomy taxonomy_path: /var/home/azureuser/.local/share/instructlab/taxonomy # Document store configuration for RAG. document_store: # Document store collection name. # Default: ilab collection_name: ilab # Document store service URI. # Default: /var/home/azureuser/.local/share/instructlab/embeddings.db uri: /var/home/azureuser/.local/share/instructlab/embeddings.db # Embedding model configuration for RAG embedding_model: # Embedding model to use for RAG. # Default: /var/home/azureuser/.cache/instructlab/models/ibm-granite/granite-embedding-125m-english embedding_model_path: /var/home/azureuser/.cache/instructlab/models/ibm-granite/granite-embedding-125m-english # Flag for enabling RAG functionality. # Default: False enabled: false # Retrieval configuration parameters for RAG retriever: # The maximum number of documents to retrieve. # Default: 3 top_k: 3 # Serve configuration section. serve: # Serving backend to use to host the model. # Default: None # Examples: # - vllm # - llama-cpp backend: vllm # Chat template to supply to the model. Possible values: 'auto'(default), # 'tokenizer', a path to a jinja2 file. # Default: None # Examples: # - auto # - tokenizer # - A filesystem path expressing the location of a custom template chat_template: auto # llama-cpp serving settings. llama_cpp: # Number of model layers to offload to GPU. -1 means all layers. # Default: -1 gpu_layers: -1 # Large Language Model Family # Default: '' # Examples: # - granite # - mixtral llm_family: '' # Maximum number of tokens that can be processed by the model. # Default: 4096 max_ctx_size: 4096 # Directory where model to be served is stored. # Default: /var/home/azureuser/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf model_path: /var/home/azureuser/.cache/instructlab/models/granite-3.1-8b-lab-v2.1 # Server configuration including host and port. # Default: host='127.0.0.1' port=8000 backend_type='' current_max_ctx_size=4096 server: # Backend Instance Type # Default: '' # Examples: # - llama-cpp # - vllm backend_type: vllm # Maximum number of tokens that can be processed by the currently served model. # Default: 4096 current_max_ctx_size: 4096 # Host to serve on. # Default: 127.0.0.1 host: 127.0.0.1 # Port to serve on. # Default: 8000 port: 8000 # vLLM serving settings. vllm: # Number of GPUs to use. # Default: None gpus: 8 # Large Language Model Family # Default: '' # Examples: # - granite # - mixtral llm_family: '' # Maximum number of attempts to start the vLLM server. # Default: 120 max_startup_attempts: 120 vllm_args: - --tensor-parallel-size - '8' # Train configuration section. train: # Additional arguments to pass to the training script. These arguments are passed # as key-value pairs to the training script. # Default: {} additional_args: learning_rate: 6e-6 lora_alpha: 32 lora_dropout: 0.1 warmup_steps: 25 use_dolomite: false # Save a checkpoint at the end of each epoch. # Default: True checkpoint_at_epoch: true # Directory where periodic training checkpoints are stored. # Default: /var/home/azureuser/.local/share/instructlab/checkpoints ckpt_output_dir: /var/home/azureuser/.local/share/instructlab/checkpoints # Directory where the processed training data is stored (post # filtering/tokenization/masking). # Default: /var/home/azureuser/.local/share/instructlab/internal data_output_dir: /var/home/azureuser/.local/share/instructlab/internal # For the training library (pipelines 'full' or 'accelerated'), this must specify # the path to the dataset '.jsonl' file. For legacy training (pipeline 'simple'), # this specifies the path to the directory. # Default: /var/home/azureuser/.local/share/instructlab/datasets data_path: /var/home/azureuser/.local/share/instructlab/datasets # Allow CPU offload for deepspeed optimizer. # Default: False deepspeed_cpu_offload_optimizer: false # PyTorch device to use. Use 'cpu' for 'simple' and 'full' training on Linux. Use # 'mps' for 'full' training on MacOS Metal Performance Shader. Use 'cuda' for # Nvidia CUDA / AMD ROCm GPUs. Use 'hpu' for Intel Gaudi GPUs. # Default: cpu # Examples: # - cpu # - mps # - cuda # - hpu device: cuda # Whether or not we should disable the use of flash-attention during training. # This is useful when using older GPUs. # Default: False disable_flash_attn: false # Pick a distributed training backend framework for GPU accelerated full fine- # tuning. # Default: fsdp distributed_backend: fsdp # The number of samples in a batch that the model should see before its parameters # are updated. # Default: 64 effective_batch_size: 128 # Allow CPU offload for FSDP optimizer. # Default: False fsdp_cpu_offload_optimizer: false # Boolean to indicate if the model being trained is a padding-free transformer # model such as Granite. # Default: False is_padding_free: false # The data type for quantization in LoRA training. Valid options are 'None' and # 'nf4'. # Default: nf4 # Examples: # - nf4 lora_quantize_dtype: # Rank of low rank matrices to be used during training. # Default: 0 lora_rank: 0 # Maximum tokens per gpu for each batch that will be handled in a single step. If # running into out-of-memory errors, this value can be lowered but not below the # `max_seq_len`. # Default: 5000 max_batch_len: 120000 # Maximum sequence length to be included in the training set. Samples exceeding # this length will be dropped. # Default: 4096 max_seq_len: 10000 # Directory where the model to be trained is stored. # Default: instructlab/granite-7b-lab model_path: /var/home/azureuser/.cache/instructlab/models/granite-3.1-8b-starter-v2.1 # Number of GPUs to use for training. This value is not supported in legacy # training or MacOS. # Default: 1 nproc_per_node: 8 # Number of epochs to run training for. # Default: 10 num_epochs: 8 # Base directory for organization of end-to-end intermediate outputs. # Default: /var/home/azureuser/.local/share/instructlab/phased phased_base_dir: /var/home/azureuser/.local/share/instructlab/phased # Judge model path for phased MT-Bench evaluation. # Default: /var/home/azureuser/.cache/instructlab/models/prometheus-eval/prometheus-8x7b-v2.0 phased_mt_bench_judge: /var/home/azureuser/.cache/instructlab/models/prometheus-8x7b-v2-0 # Phased phase1 effective batch size. # Default: 128 phased_phase1_effective_batch_size: 128 # Learning rate for phase1 knowledge training. # Default: 2e-05 phased_phase1_learning_rate: 2e-05 # Number of epochs to run training for during phase1 (experimentally optimal # number is 7). # Default: 7 phased_phase1_num_epochs: 7 # Number of samples the model should see before saving a checkpoint during phase1. # Disabled when set to 0. # Default: 0 phased_phase1_samples_per_save: 0 # Phased phase2 effective batch size. # Default: 3840 phased_phase2_effective_batch_size: 3840 # Learning rate for phase2 skills training. # Default: 6e-06 phased_phase2_learning_rate: 6e-06 # Number of epochs to run training for during phase2. # Default: 10 phased_phase2_num_epochs: 10 # Number of samples the model should see before saving a checkpoint during phase2. # Disabled when set to 0. # Default: 0 phased_phase2_samples_per_save: 0 # Training pipeline to use. Simple is for systems with limited resources, full is # for more capable consumer systems (64 GB of RAM), and accelerated is for systems # with a dedicated GPU. # Default: full # Examples: # - simple # - full # - accelerated pipeline: accelerated # Number of samples the model should see before saving a checkpoint. # Default: 250000 save_samples: 0 # Optional path to a yaml file that tracks the progress of multiphase training. # Default: None training_journal: # Configuration file structure version. # Default: 1.0.0 version: 1.0.0
3. ilab system info:
bash-5.1# cat ilab-system-info time="2025-06-11T14:37:44Z" level=warning msg="The input device is not a TTY. The --tty and --interactive flags might not work properly" Platform: sys.version: 3.11.7 (main, Jan 8 2025, 00:00:00) [GCC 11.4.1 20231218 (Red Hat 11.4.1-3)] sys.platform: linux os.name: posix platform.release: 5.14.0-427.65.1.el9_4.x86_64 platform.machine: x86_64 platform.node: vshaw-rhelai-amd-test-westus platform.python_version: 3.11.7 os-release.ID: rhel os-release.VERSION_ID: 9.4 os-release.PRETTY_NAME: Red Hat Enterprise Linux 9.4 (Plow) memory.total: 1820.96 GB memory.available: 1726.23 GB memory.used: 86.61 GB InstructLab: instructlab.version: 0.26.1 instructlab-dolomite.version: 0.2.0 instructlab-eval.version: 0.5.1 instructlab-quantize.version: 0.1.0 instructlab-schema.version: 0.4.2 instructlab-sdg.version: 0.8.2 instructlab-training.version: 0.10.3 Torch: torch.version: 2.6.0 torch.backends.cpu.capability: AVX512 torch.version.cuda: None torch.version.hip: 6.3.42134-a9a80e791 torch.cuda.available: True torch.backends.cuda.is_built: True torch.backends.mps.is_built: False torch.backends.mps.is_available: False torch.cuda.bf16: True torch.cuda.current.device: 0 torch.cuda.0.name: AMD Radeon Graphics torch.cuda.0.free: 24.1 GB torch.cuda.0.total: 191.5 GB torch.cuda.0.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.1.name: AMD Radeon Graphics torch.cuda.1.free: 24.2 GB torch.cuda.1.total: 191.5 GB torch.cuda.1.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.2.name: AMD Radeon Graphics torch.cuda.2.free: 24.2 GB torch.cuda.2.total: 191.5 GB torch.cuda.2.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.3.name: AMD Radeon Graphics torch.cuda.3.free: 24.2 GB torch.cuda.3.total: 191.5 GB torch.cuda.3.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.4.name: AMD Radeon Graphics torch.cuda.4.free: 24.2 GB torch.cuda.4.total: 191.5 GB torch.cuda.4.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.5.name: AMD Radeon Graphics torch.cuda.5.free: 24.3 GB torch.cuda.5.total: 191.5 GB torch.cuda.5.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.6.name: AMD Radeon Graphics torch.cuda.6.free: 24.3 GB torch.cuda.6.total: 191.5 GB torch.cuda.6.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) torch.cuda.7.name: AMD Radeon Graphics torch.cuda.7.free: 24.3 GB torch.cuda.7.total: 191.5 GB torch.cuda.7.capability: 9.4 (see https://developer.nvidia.com/cuda-gpus#compute) llama_cpp_python: llama_cpp_python.version: 0.3.6 llama_cpp_python.supports_gpu_offload: False bash-5.1#
4. podman images:
bash-5.1# podman images
REPOSITORY TAG IMAGE ID CREATED SIZE R/O
registry.redhat.io/rhelai1/instructlab-amd-rhel9 1.5.1 994e4185df44 5 days ago 34.3 GB true
bash-5.1#
5. ilab model list :
bash-5.1# ilab model list +------------------------------------+---------------------+---------+-------------------------------------------------------------+ | Model Name | Last Modified | Size | Absolute path | +------------------------------------+---------------------+---------+-------------------------------------------------------------+ | models/granite-3.1-8b-starter-v2.1 | 2025-06-11 15:16:57 | 31.2 GB | /root/.cache/instructlab/models/granite-3.1-8b-starter-v2.1 | | models/granite-3.1-8b-lab-v2.1 | 2025-06-11 15:29:34 | 31.2 GB | /root/.cache/instructlab/models/granite-3.1-8b-lab-v2.1 | +---------
6. rocm-smi :
bash-5.1# ilab shell
(app-root) /$ rocm-smi
============================================ ROCm System Management Interface ============================================
====================================================== Concise Info ======================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Junction) (Socket) (Mem, Compute, ID)
==========================================================================================================================
0 2 0x74b5, 65402 44.0°C 178.0W NPS1, SPX, 0 2102Mhz 900Mhz 0% auto 750.0W 88% 0%
1 3 0x74b5, 27175 40.0°C 179.0W NPS1, SPX, 0 2105Mhz 900Mhz 0% auto 750.0W 87% 0%
2 4 0x74b5, 16561 41.0°C 185.0W NPS1, SPX, 0 2102Mhz 900Mhz 0% auto 750.0W 87% 0%
3 5 0x74b5, 54764 42.0°C 186.0W NPS1, SPX, 0 2098Mhz 900Mhz 0% auto 750.0W 87% 0%
4 6 0x74b5, 10760 42.0°C 181.0W NPS1, SPX, 0 2110Mhz 900Mhz 0% auto 750.0W 87% 0%
5 7 0x74b5, 48981 42.0°C 181.0W NPS1, SPX, 0 2102Mhz 900Mhz 0% auto 750.0W 87% 0%
6 8 0x74b5, 32548 41.0°C 188.0W NPS1, SPX, 0 2103Mhz 900Mhz 0% auto 750.0W 87% 0%
7 9 0x74b5, 60025 43.0°C 179.0W NPS1, SPX, 0 2098Mhz 900Mhz 0% auto 750.0W 87% 0%
==========================================================================================================================
================================================== End of ROCm SMI Log ===================================================
(app-root) /$