-
Bug
-
Resolution: Not a Bug
-
 Undefined
Undefined
-
None
-
rhelai-1.4.3
-
None
-
False
-
-
False
-
-
To Reproduce Steps to reproduce the behavior:
Run short training with phased_num_epochs reduced to 2
Expected behavior
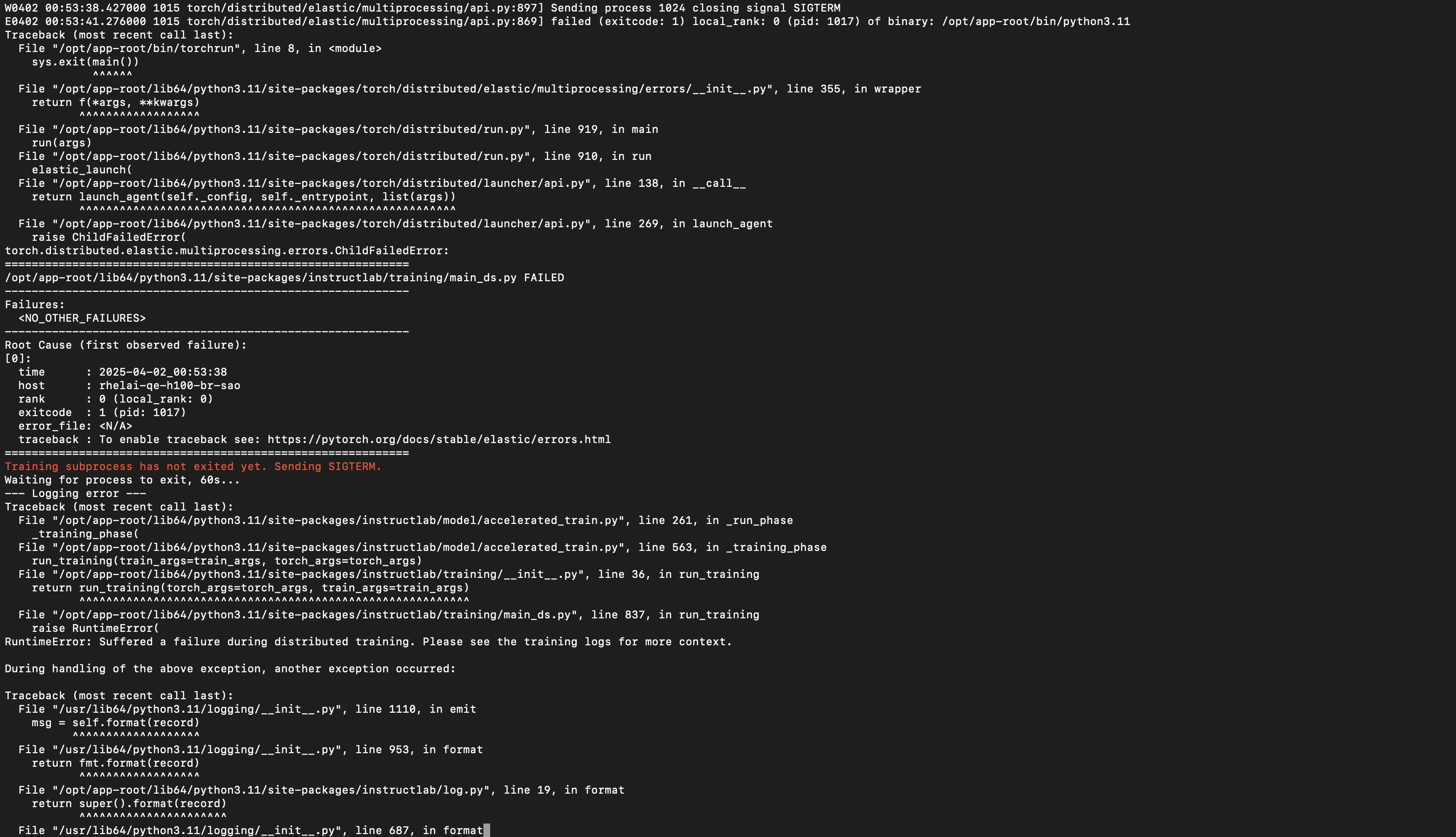
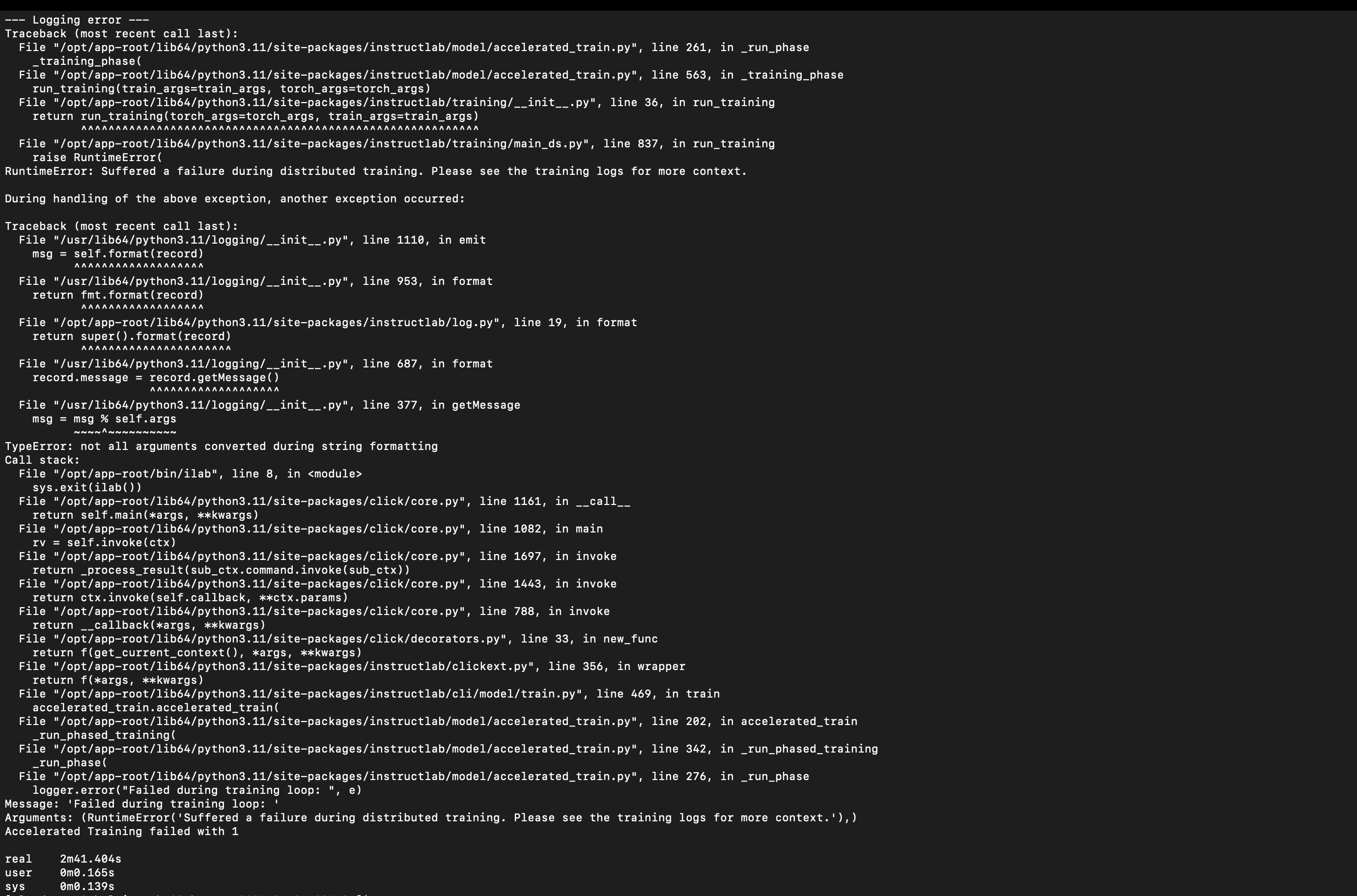
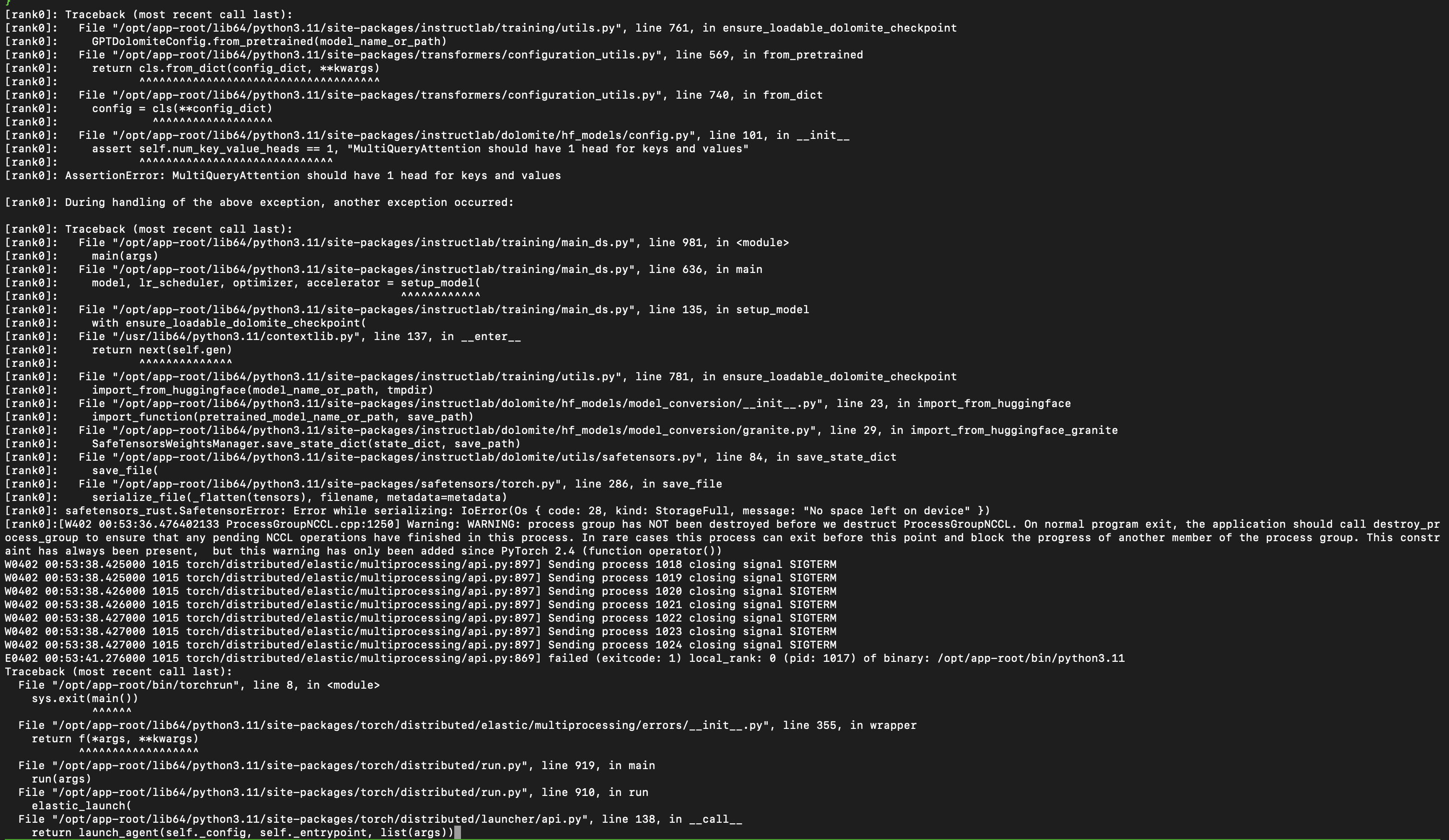
- AssertionError: MultiQueryAttention should have 1 head for keys and values
Screenshots
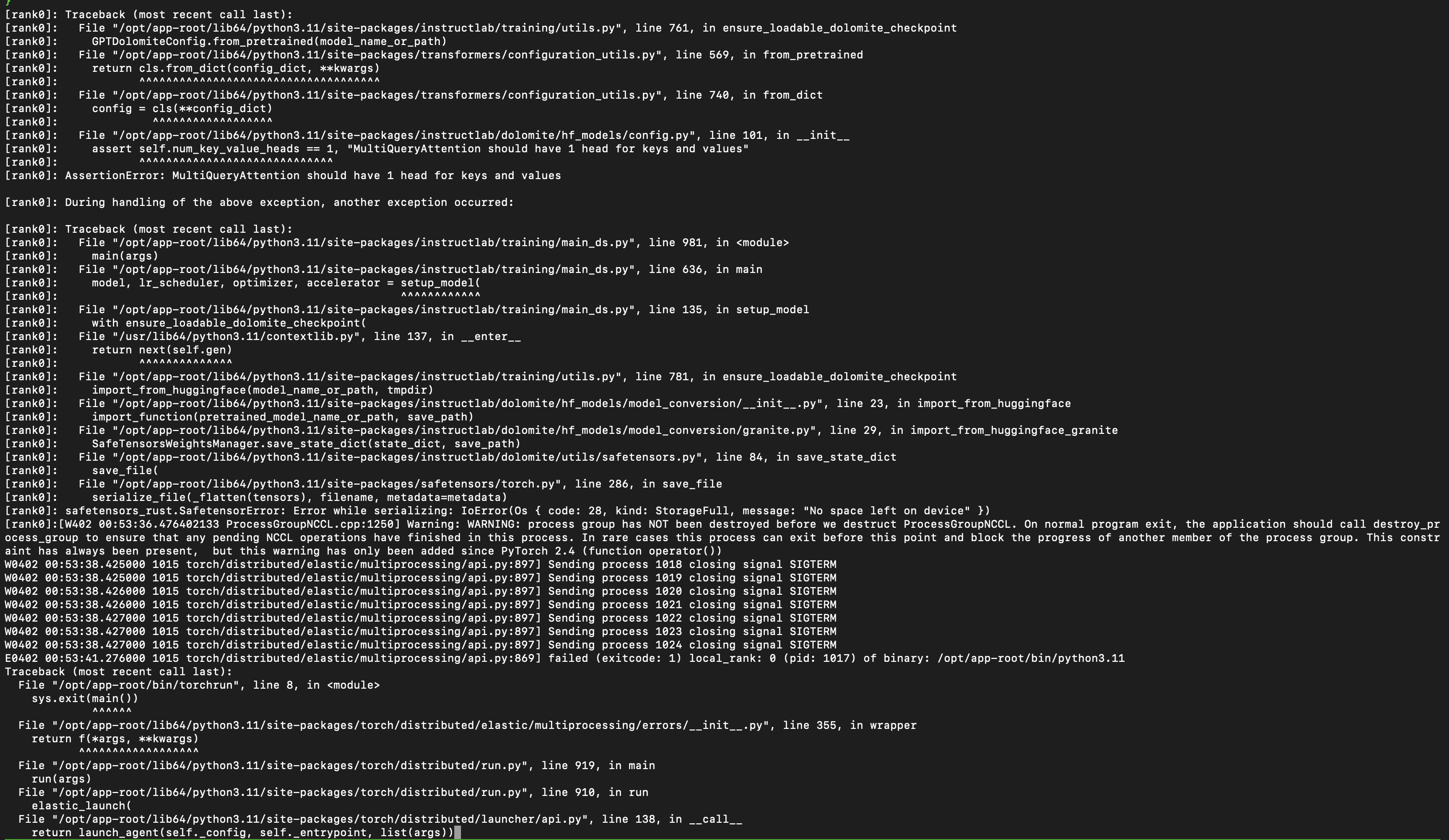
Device Info (please complete the following information):
- Hardware Specs: IBM Cloud instance (8 H100 GPU)
- OS Version: RHEL AI 1.4
- InstructLab Version: 0.23.5
- Provide the output of these two commands:
- sudo bootc status --format json | jq .status.booted.image.image.image to print the name and tag of the bootc image, should look like registry.stage.redhat.io/rhelai1/bootc-intel-rhel9:1.3-1732894187
- "registry.redhat.io/rhelai1/bootc-nvidia-rhel9:1.4"
- sudo bootc status --format json | jq .status.booted.image.image.image to print the name and tag of the bootc image, should look like registry.stage.redhat.io/rhelai1/bootc-intel-rhel9:1.3-1732894187
-
- ilab system info
- platform.node: rhelai-qe-h100-br-sao
- ilab system info
platform.python_version: 3.11.7
os-release.ID: rhel
os-release.VERSION_ID: 9.4
os-release.PRETTY_NAME: Red Hat Enterprise Linux 9.4 (Plow)
memory.total: 1763.83 GB
memory.available: 1752.49 GB
memory.used: 3.41 GB
InstructLab:
instructlab.version: 0.23.5
instructlab-dolomite.version: 0.2.0
instructlab-eval.version: 0.5.1
instructlab-quantize.version: 0.1.0
instructlab-schema.version: 0.4.2
instructlab-sdg.version: 0.7.2
instructlab-training.version: 0.7.0
Torch:
torch.version: 2.5.1
torch.backends.cpu.capability: AVX512
torch.version.cuda: 12.4
torch.version.hip: None
torch.cuda.available: True
torch.backends.cuda.is_built: True
torch.backends.mps.is_built: False
torch.backends.mps.is_available: False
torch.cuda.bf16: True
torch.cuda.current.device: 0
torch.cuda.0.name: NVIDIA H100 80GB HBM3
torch.cuda.0.free: 78.6 GB
torch.cuda.0.total: 79.1 GB
torch.cuda.0.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.1.name: NVIDIA H100 80GB HBM3
torch.cuda.1.free: 78.6 GB
torch.cuda.1.total: 79.1 GB
torch.cuda.1.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.2.name: NVIDIA H100 80GB HBM3
torch.cuda.2.free: 78.6 GB
torch.cuda.2.total: 79.1 GB
torch.cuda.2.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.3.name: NVIDIA H100 80GB HBM3
torch.cuda.3.free: 78.6 GB
torch.cuda.3.total: 79.1 GB
torch.cuda.3.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.4.name: NVIDIA H100 80GB HBM3
torch.cuda.4.free: 78.6 GB
torch.cuda.4.total: 79.1 GB
torch.cuda.4.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.5.name: NVIDIA H100 80GB HBM3
torch.cuda.5.free: 78.6 GB
torch.cuda.5.total: 79.1 GB
torch.cuda.5.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.6.name: NVIDIA H100 80GB HBM3
torch.cuda.6.free: 78.6 GB
torch.cuda.6.total: 79.1 GB
torch.cuda.6.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
torch.cuda.7.name: NVIDIA H100 80GB HBM3
torch.cuda.7.free: 78.6 GB
torch.cuda.7.total: 79.1 GB
torch.cuda.7.capability: 9.0 (see https://developer.nvidia.com/cuda-gpus#compute)
llama_cpp_python:
llama_cpp_python.version: 0.3.2
llama_cpp_python.supports_gpu_offload: True
Bug impact
- Please provide information on the impact of this bug to the end user.
Known workaround
- Please add any known workarounds.
Additional context
- <your text here>
- …
{kind=link}
{kind=link}
{kind=link}
- is related to
-
-
- Resolved
-