-
Bug
-
Resolution: Not a Bug
-
 Undefined
Undefined
-
None
-
rhel-10.0.beta
-
Yes
-
None
-
ssg_platform_tools
-
5
-
False
-
False
-
-
No
-
None
-
None
-
None
-
Unspecified Release Note Type - Unknown
-
None
When comparing RHEL-10 performance against RHEL-9 performance, Phoronix mt-dgemm benchmark runs 2x slower than in RHEL-9. This is using all available CPUs (OpenMP binary). Results from Intel Icelake and AMD Rome:
Phoronix mt-dgemm benchmark:
https://openbenchmarking.org/innhold/47c3d58042d95b8544390d6d5889f79529caba87
https://openbenchmarking.org/test/pts/mt-dgemm
I was able to track down the problem to the GCC version. The issue can be reproduced on RHEL-9, and using only 1 thread:
scl enable gcc-toolset-12 'bash'
export OMP_NUM_THREADS=1
The critical section of the code:
132 #pragma omp parallel for private(sum) 133 for(i = 0; i < N; i++) { 134 for(j = 0; j < N; j++) { 135 sum = 0; 136 137 for(k = 0; k < N; k++) { 138 sum += matrixA[i*N + k] * matrixB[k*N + j]; 139 } 140 141 matrixC[i*N + j] = (alpha * sum) + (beta * matrixC[i*N + j]); 142 } 143 }
Compiled with
gcc -g -O3 -march=native -fopenmp -fopt-info -o "${bin}" mt-dgemm/src/mt-dgemm.c
I see the following differences in optimizations:
GCC V11:
mt-dgemm/src/mt-dgemm.c:132:11: optimized: basic block part vectorized using 32 byte vectors
GCC V12:
mt-dgemm/src/mt-dgemm.c:137:18: optimized: loop vectorized using 16 byte vectors
mt-dgemm/src/mt-dgemm.c:137:18: optimized: loop turned into non-loop; it never loops
perf annotate shows the following differences:
GCC V11 - FMA instruction is used (operates only on low double-precision floating-point value from xmm register)
92.63% : 4017c0: vfmadd231sd (%rdx),%xmm5,%xmm0 0.04% : 4017c5: add %rsi,%rdx 0.00% : 4017c8: cmp %rax,%rcx 7.27% : 4017cb: jne 4017b8 <main._omp_fn.1+0xe8>
GCC V12 - vector instructions are used, operating on a pair of double-precision values. Most of the time is spent executing vmovhpd (Vector Move High Packed Double-Precision) instruction. It's used to move one double-precision floating-point value from a memory location or XMM register to the high half of another XMM register:
30.72% : 4017b8: vmovsd (%rax),%xmm0 0.01% : 4017bc: add $0x10,%rdx 40.83% : 4017c0: vmovhpd (%rax,%r9,1),%xmm0,%xmm0 3.57% : 4017c6: vmulpd -0x10(%rdx),%xmm0,%xmm0 0.00% : 4017cb: add %r10,%rax 8.37% : 4017ce: vaddsd %xmm0,%xmm1,%xmm1 0.01% : 4017d2: vunpckhpd %xmm0,%xmm0,%xmm0 13.16% : 4017d6: vaddsd %xmm1,%xmm0,%xmm1 0.00% : 4017da: cmp %r8,%rdx 3.27% : 4017dd: jne 4017b8 <main._omp_fn.1+0xf8>
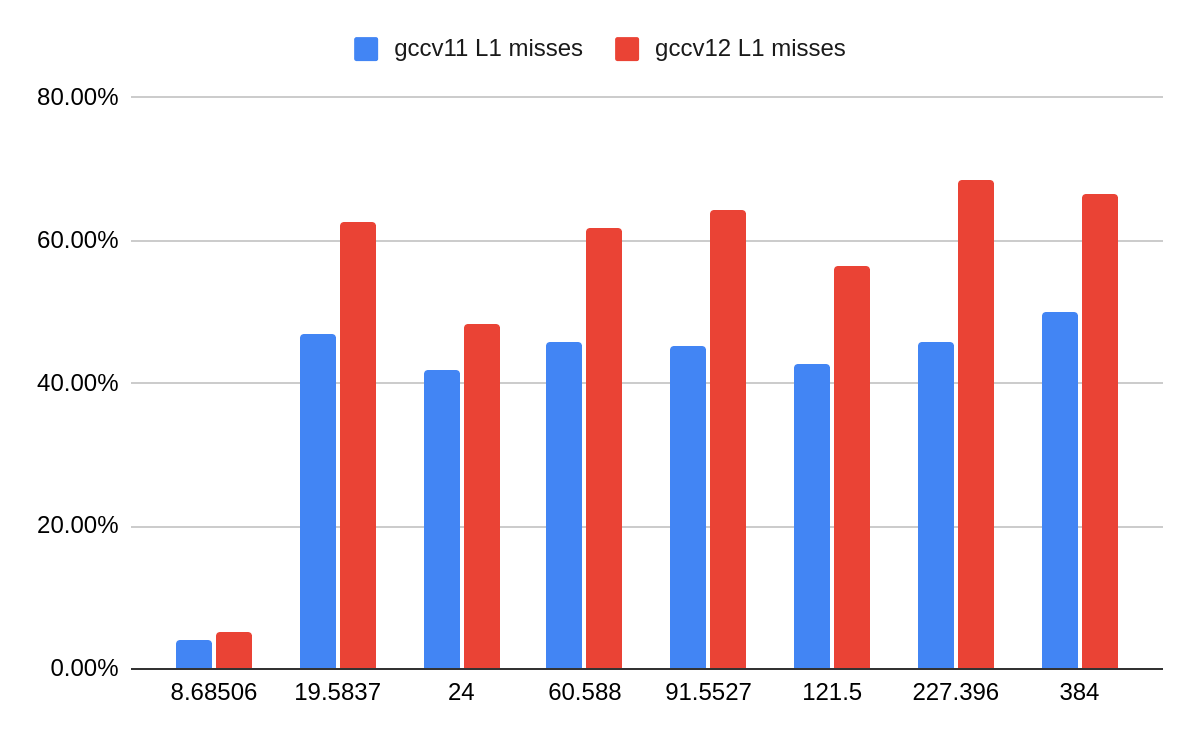
perf stat -d shows an increase in L1-dcache-load-misses and LLC-load-misses:
GCC v11:
98,178,107,989 L1-dcache-loads # 506.997 M/sec (90.91%) 49,241,071,195 L1-dcache-load-misses # 50.15% of all L1-dcache accesses (90.91%) 46,841,599,720 LLC-loads # 241.892 M/se (90.91%) 6,874,313,062 LLC-load-misses # 14.68% of all L1-icache accesses (90.91%) 193.679625668 seconds time elapsed
GCC v12:
73,771,414,994 L1-dcache-loads # 340.012 M/sec (90.91%) 49,468,808,201 L1-dcache-load-misses # 67.06% of all L1-dcache accesses (90.91%) 46,849,369,007 LLC-loads # 215.929 M/sec (90.91%) 10,372,074,893 LLC-load-misses # 22.14% of all L1-icache accesses (90.91%) 217.005472851 seconds time elapsed
I'm going to upload the results from the Intel Icelake server https://beaker.engineering.redhat.com/view/formir1.slevarna.tpb.lab.eng.brq.redhat.com#details
running RHEL-9.4.0-20240413.1 with
gcc (GCC) 11.4.1 20231218 (Red Hat 11.4.1-3)
and
gcc (GCC) 12.2.1 20221121 (Red Hat 12.2.1-7)
To reproduce the issue, run the following:
./run.sh
scl enable gcc-toolset-12 'bash'
./run.sh
All log files have the GCC version in the name. Files to check:
perf stat output: mtdgemm-gcc-11.4.1-3_1.log
gcc optimization logs: mtdgemm-gcc-11.4.1-3_compilation.log
perf annotate: mtdgemm-gcc-11.4.1-3.perf.annotate
Could you please investigate if gcc V12 can produce faster code that runs as fast as compiled with gcc V11?
Thanks a lot
Jirka