-
Bug
-
Resolution: Not a Bug
-
 Undefined
Undefined
-
None
-
rhel-10.2
-
None
-
None
-
None
-
rhel-virt-storage
-
None
-
False
-
False
-
-
None
-
None
-
None
-
None
-
Unspecified
-
Unspecified
-
Unspecified
-
None
What were you trying to do that didn't work?
Choose the Windows Failover Cluster (WSFC ) that owns the shared disk.
Execute IO on the shared disk and keep it running.
Live-migrate the node to another host.
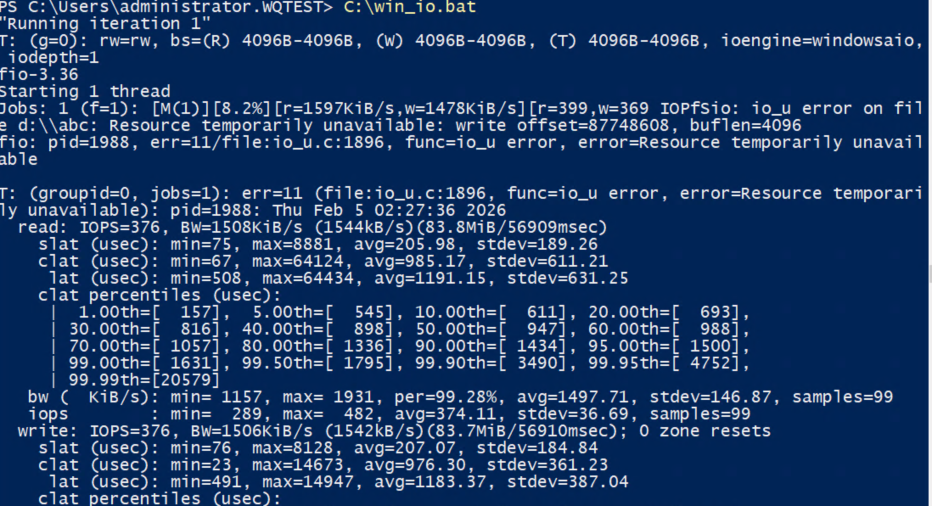
The PR is migrated, but the IO in the node has failed due to "Resource Temporarily unavailable"
wait aboult 1 minute, rerun the io it may be successful.
What is the impact of this issue to you?
Affect the cluster node application behavior
Please provide the package NVR for which the bug is seen:
Red Hat Enterprise Linux release 10.2 Beta (Coughlan)
6.12.0-191.el10.x86_64
device-mapper-1.02.206-3.el10.x86_64
device-mapper-multipath-0.9.9-15.el10.x86_64
qemu-kvm-10.1.0-7.el10.stefanha202601211325.x86_64
seabios-bin-1.17.0-1.el10.noarch
edk2-ovmf-20251114-2.el10.noarch
How reproducible is this bug?:
100%
Steps to reproduce
- Boot Domain nodes
virsh start start vm-msdomain
virsh start start vm-msnode1
virsh start start vm-msnode2
(The domain and cluster is build finished)
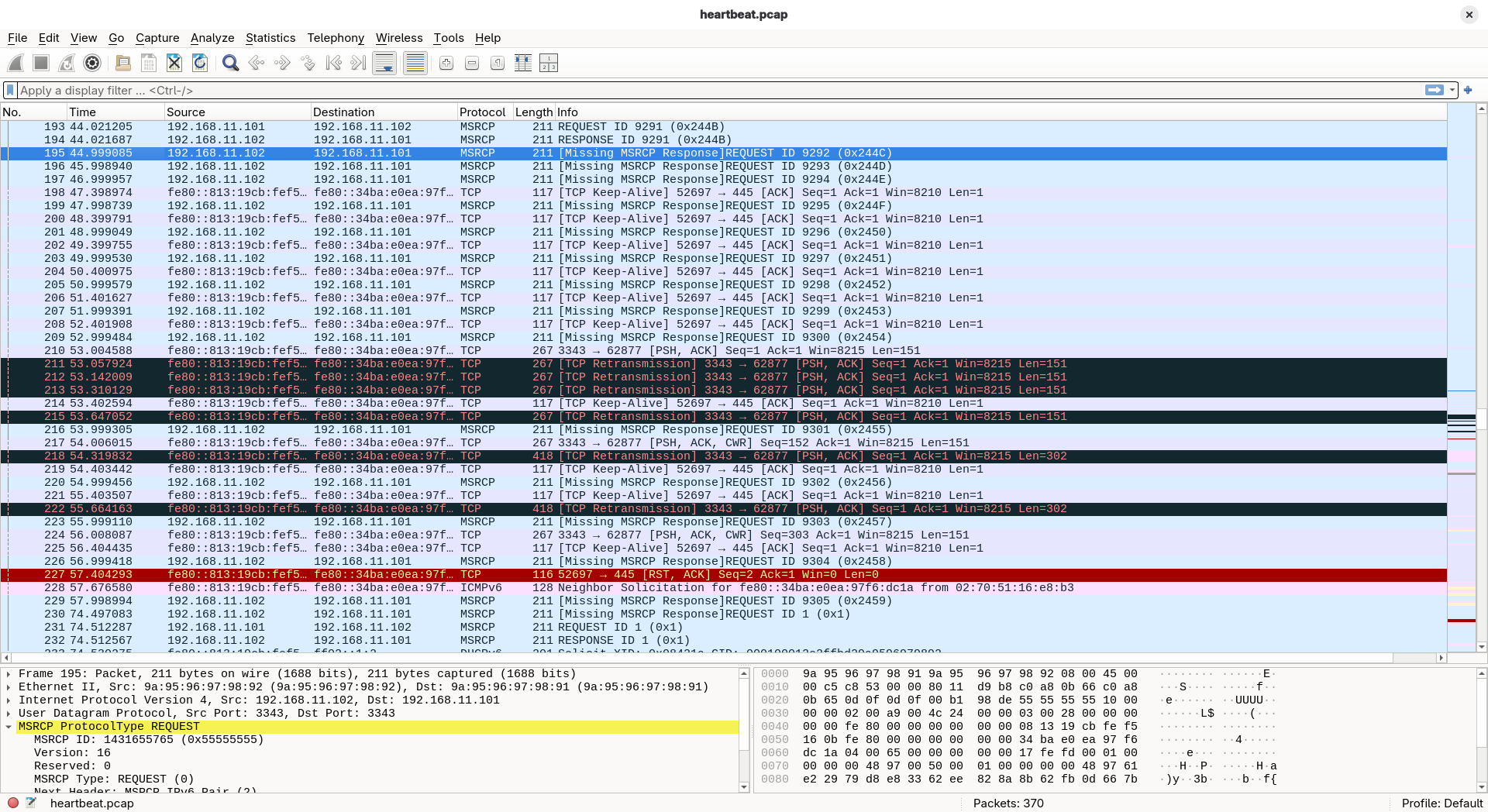
- Access the node that owns the shared disk
- Execute io on the disk
c:\win_io.bat - live migration of the node to another host
virsh migrate --live vm-msnode1 qemu+ssh://root@vmx3/system --verbose - Check the io in the node
- Check the io in the host
IO error on the source host
IO succeeds on the target host
Expected results
Step 4 no affect
Actual results
step 4 io error exit