-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
None
-
1.4.1, 1.8.0
-
None
-
3
-
False
-
-
False
-
-
Known Issue
-
Done
-
RHDH Install 3270, RHDH Install 3271, RHDH Install 3272, RHDH Install 3273, RHDH Install 3274, RHDH Install 3275, RHDH Install 3281, RHDH Install 3282, RHDH Install 3283, RHDH Install 3284
-
Critical
Description of problem:
After installing the Operator version 1.4.1 the deployment rhdh-operator becomes briefly healthy before being killed and restarted with an OOM error.
Prerequisites (if any, like setup, operators/versions):
The operator manages a single Backstage Instance.
Steps to Reproduce
- Install the Operator version with a single Backstage instance present
- Observe that the rhdh-operator deployment requests 128Mi of memory with a 1Gi limit
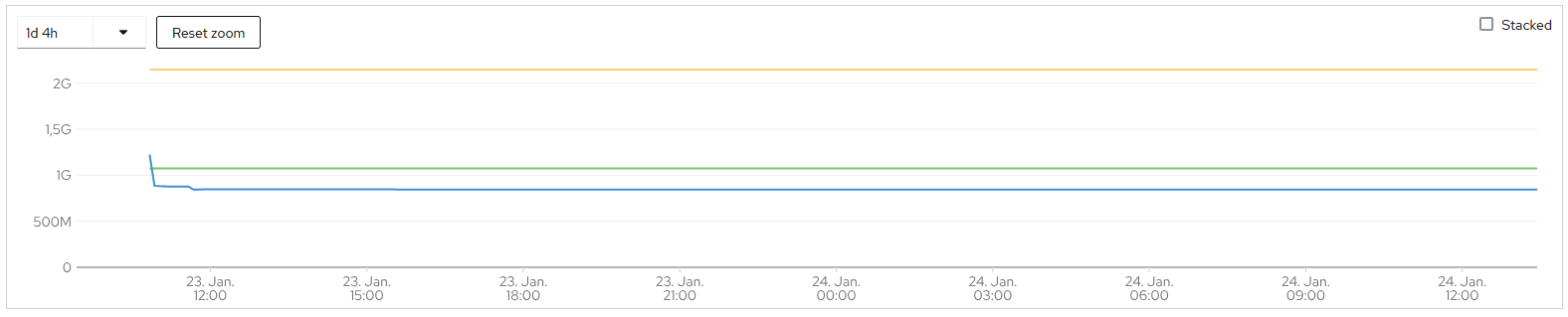
- Observe that the operator becomes healthy for less than 10 seconds before being OOM killed
- Manually set the memory request to 1Gi and the limit to 2Gi
- Observe that the pod now becomes healthy and that the memory tops out at 1.22 Gi and stabilizes at 1.07 Gi
- With the next operator update/reconciliation the memory is reset and the game starts anew
Actual results:
see above
Expected results:
The operator should have a valid memory configuration out of the box for all common use cases.
Reproducibility (Always/Intermittent/Only Once):
Always
Build Details:
Additional info (Such as Logs, Screenshots, etc):
- is cloned by
-
-
- Release Pending
-

