-
Feature Request
-
Resolution: Unresolved
-
 Undefined
Undefined
-
None
-
None
-
None
-
Product / Portfolio Work
-
None
-
False
-
-
None
-
None
-
None
-
-
None
-
None
-
None
-
None
-
None
1. Proposed title of this feature request
TNF/ODF for NIS(Network-in-a-Server)
2. What is the nature and description of the request?
This feature request proposes the definition, validation, and official support of a 2-node High Availability (HA) TNF/ODF architecture for NIS (Network-in-a-Server) targeting Telco use cases.
3. Why does the customer need this? (List the business requirements here)
Samsung would like to move forward with the commercial deployment of NIS in TNF/ODF
4. List any affected packages or components.
Server Configuration: (AMD Siena-based vDU)
Server: Supermicro AS-1115S-FDWTRT
CPU: AMD EPYC 8004 Series (64C, TBD GHz, 70 - 225W)
AVX CPU Clock: TBD GHz for all cores
Memory: 4 X 128GB (512GB)
Storage: 2 x SSD 0.96TB (TBD)
PCIe: PCIe 5.0 2 x16 FHFL/ x16 Riser Kit
NIC card: Westport NIC:
- 25G xSFP28 x4port, GM support, 2EA
- Additional NIC: 25G xSFP28 x4port
Accelerator: N/A
Dimensions: 1.7’’ x 17.2” wide x 16.9” depth
Power: 100-240 VAC input, 800 W
Cooling: Front to rear
Environmental:
- NEBS Level 3 support
- ASHRAE Class 3 and Class 4 compliance
- Targets GR 3108 Class 1 compliance
Site Configuration:
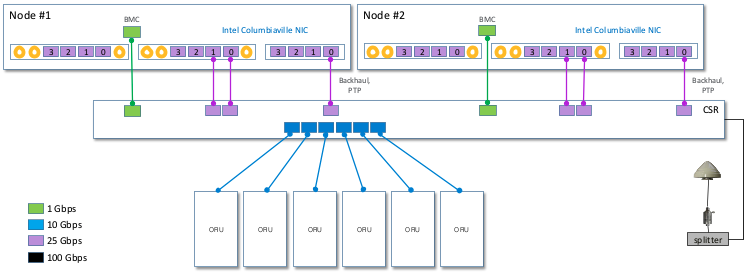
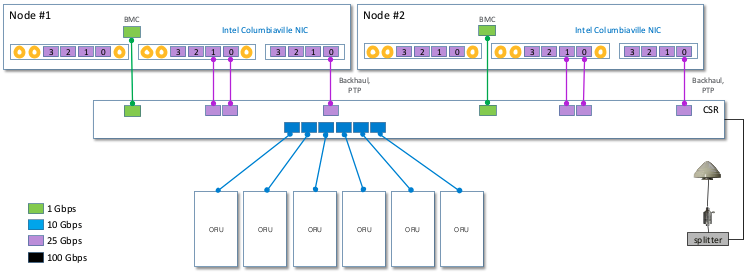
PTP Configuration:
- 2-node T-GM / T-GM configuration
or
- 2-node T-BC / T-BC configuration
NIS Configuration:
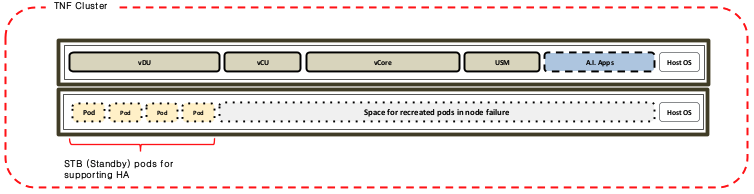
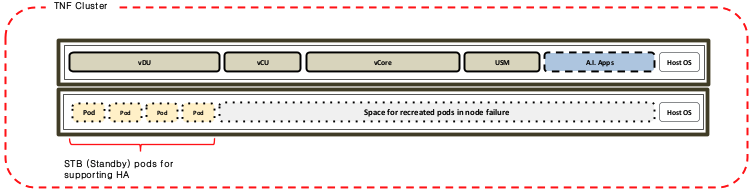
Basically, HA for each CNF is performed by pod recreation and switching over.
Each CNF consists of active and standby pods for supporting switchover and Standby pod is required for a pod that needs to be switched over immediately when the pod is not working.
Acceptance Criteria:
Types of Failure and Recovery Scenarios
- Single-node failure and restoration
- Single-disk failure and restoration
- Inter-node network failure and restoration
(network failure between the two nodes)
ODF(Storage)
- Support block RWX
- Single-node failure does not result in PVC data loss, and storage must remain operational during one node down.
- Split-brain prevention and data consistency are guaranteed.
- Automatic or procedurally defined recovery after node restoration is supported.
- Allow unused configurations to be disabled.
- During failure/recovery scenarios* and ODF upgrades, PV data integrity must be 100% (zero data loss).
- During failure/recovery scenarios* and ODF upgrades, I/O degradation and PV disconnection must be minimized, with the following criteria:
- I/O degradation must be limited to within 30 seconds.
- I/O instability during rebuild/rebalancing must be minimized (specific quantitative threshold to be defined).
- Pod-to-PV disconnection time must be limited to within 5 seconds.
- The total ODF upgrade time must not exceed 1 hour.
- Assumes an upgrade from an EUS version to the next EUS version (e.g., ODF 4.20 → 4.22).
TNF(Platform)
- During failures:
- Failure scenarios, including etcd and node failures
- CNF workloads restart or remain running based on policy.
- Split-brain prevention and data consistency are guaranteed
- Support these: Active-Active, Active-Passive
- Support rt-kernel
- Support GPU operator in rt-kernel
- Must support schedulable control plane together with workload partitioning.
- Each node must be capable of supporting up to 250 pods per node.
- During failure/recovery scenarios* or TNF upgrades, service interruption of OCP must be minimized, with the following performance criteria:
- Kubernetes API server response failure rate increase must be limited to within 1 second.
- CoreDNS response latency must remain within 1 second.
- Scheduling and pod lifecycle management (LCM) delays must remain within 10 seconds.
- During failure/recovery scenarios* or TNF upgrades, etcd data loss or corruption must be 0% (zero tolerance).
- The total TNF upgrade time must not exceed 2 hours.
- Assumes an upgrade from an EUS version to the next EUS version (e.g., OCP 4.20 → 4.22).
- CNF (workload) upgrade time is excluded.
- For additional worker nodes, allow an additional 30 minutes per worker node.
Lifecycle & Operations & Maintenance
- Official installation by ABI methodology.(Bootstrap should not be necessary)
- Supported upgrade paths for OpenShift minor and patch releases.
- Rolling upgrades and planned reboots are supported one node at a time.
- Single-node reboot or replacement is supported.
Observability
- TNF/ODF monitoring
- TNF/ODF alerts
Performance & Resource Constraints
- Minimum CPU, memory, and disk requirements for TNF/ODF are documented.
- Recommended CPU, memory, and disk requirements for TNF/ODF are documented.
- Service interruption is not allowed during a single-node failure.
Documentation
- Reference Architecture
- ABI installation guide
- Known limitations and sizing guide
- Failure & recovery guide

{kind=link}
{kind=link}