Details
-
Feature Request
-
Resolution: Unresolved
-
 Normal
Normal
-
None
-
None
-
None
-
False
-
None
-
False
-
Not Selected
-
0
-
0%
Description
Description of problem:
Ref: https://issues.redhat.com/browse/OHSS-30820
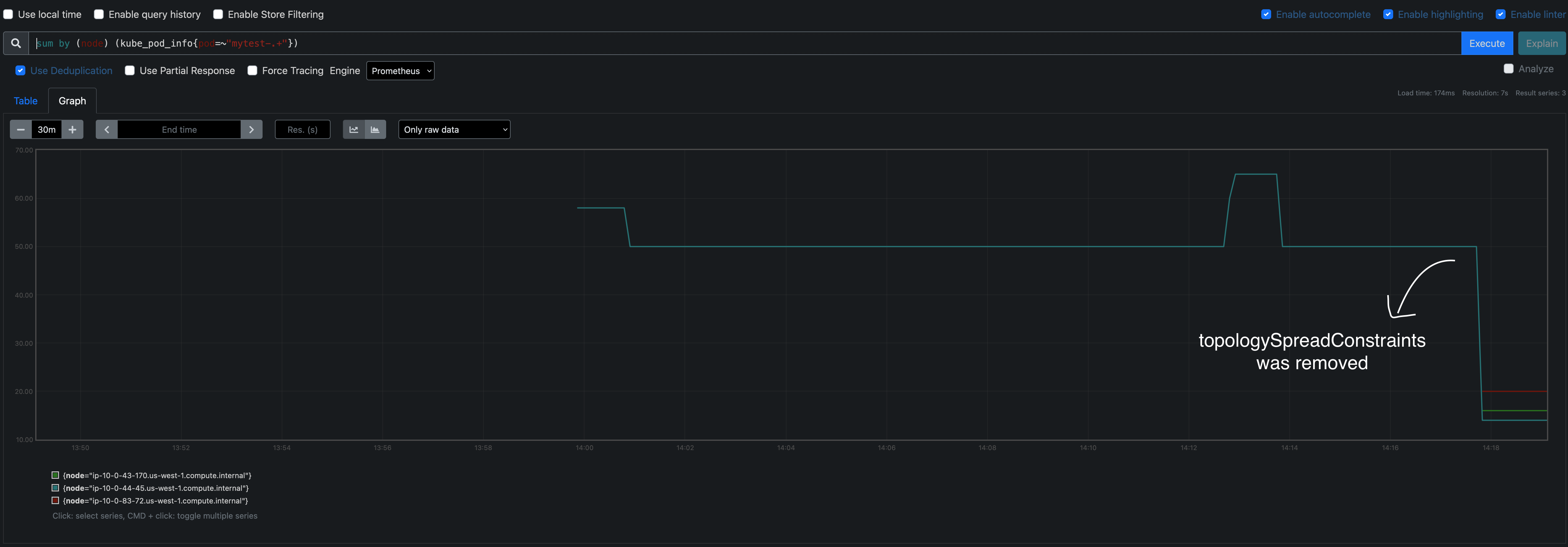
Regarding the HC prometheus pod placement policy, we recently noticed there is a topologySpreadConstraint added to them, that keeps them on Infra nodes if available. That is guaranteeing one of the pods to be on infra but leave the second replica to randomly pick a node(worker or infra) that ends up on worker node mostly(even after 3-4 attempts) which is working as expected based on the spec.
But PerfScale workload(in Prow as well as IBM Lakehouse testing) want both of them on infra pool due to prom resource consumption during high scale load
topologySpreadConstraints: - labelSelector: matchLabels: app: prometheus maxSkew: 1 nodeAffinityPolicy: Honor nodeTaintsPolicy: Honor topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway - labelSelector: matchLabels: app: prometheus maxSkew: 2 nodeAffinityPolicy: Honor nodeTaintsPolicy: Honor topologyKey: node-role.kubernetes.io/infra whenUnsatisfiable: ScheduleAnyway
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1. create a HC 2. add machinepool with required labels and taints for infra 3. migrate prometheus pods 4. wait and watch the migration to finish
Actual results:
One of the promethes-k8s pod gets migrated to infra and other one stays on the worker node, it might get in to infra node eventually but after multiple attempts as they get random allocation.
Expected results:
Need a policy to make sure prometheus pods with right toleration should get scheduled on Infra node
Additional info:
Slack thread - https://redhat-internal.slack.com/archives/C02LM9FABFW/p1705412300117649